详解依存树的来龙去脉及用法

阅读大概5分钟
这开始介绍依存树的来龙去脉!
来历
a.简单的短语分词(正向逆向最大匹配,n-gram,机器学习...)(以单个词为重点)
比如: 猴子喜欢吃香蕉。->猴子 喜欢 吃 香蕉 。
b.由分词转向词性标注
猴子/NN 喜欢/VV 吃/VV 香蕉/NN 。/PU
(但是能不能站在句子上分析呢?就有了下面的发展)
c.由词性标注生成短语句法树(从整个句子分析)

短语句法树的计算机表示

短语句法树的逻辑表示
d.由短语句法树转成依存树(依存关系可以用树形图表示,表示依存关系的树形图称为依存树dependency tree)
三个工具
由短语句法树转到依存树一般可用这三个工具,顺便有链接
1.penn2malt
https://link.jianshu.com/?t=http%3A%2F%2Fstp.lingfil.uu.se%2F%7Enivre%2Fresearch%2FPenn2Malt.html
根据说明就可以用,想具体了解怎么用,可以看我之前写的penn2malt简书(上面的链接)
2.Stanford Parser
http://nlp.stanford.edu:8080/parser/ 这是可以体验功能。
这个是工具包
https://nlp.stanford.edu/software/stanford-dependencies.shtml 教你怎么用stanford dependency parser这个工具代码。
3.LTH
https://link.jianshu.com/?t=http%3A%2F%2Fnlp.cs.lth.se%2F
下面这个链接
https://link.jianshu.com/?t=http%3A%2F%2Fnlp.cs.lth.se%2Fsoftware%2Ftreebank-converter%2F
里面有依存树的应用和工具,但是你阅读会发现不能转换中文语料库
转换的依存树长这个样子:

依存树
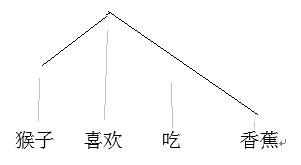
依存投射树
但是计算机中肯定就不是这么存的了。比如Stanford Parser 是这个样子的:

Stanford Parser Dependency Tree
这里的数字是这个词的序列: 猴子 -1,喜欢-2,吃-3,香蕉-4 (符号被抛弃)
比如:nsubj ( 喜欢-2,猴子-1)
nsubj是表示后两者的关系,这里前者是父亲,后者是儿子,也就是 猴子 依存于 喜欢 。
nsubj是表示后两者的关系,这里前者是父亲,后者是儿子,也就是 猴子 依存于 喜欢 。
如果前面的关系实在想弄清楚是啥的话,这有个网站
https://link.jianshu.com/?t=http%3A%2F%2Fwenku.baidu.com%2Flink%3Furl%3DIfW-hkMfPuK29t49Wa_nO2UAMpP2oGYCUAZuY5PrHHIQHsIm5moH82DMbTA521PMhCC4svgGRSgUTaSkHktw5Ru6RQCCRjwuHfkNVB3mcum
存储的话就很简单啦。不在细说
两个基本问题
都挺简单的数据结构问题(多叉树的节点问题):
a. 已知一个节点怎么找到它的父(子)节点。
这个就很简单了。自己应该会的。
b. 求两个节点的最短路径
就是找到一个节点,把自己和所有父节点放到一个数组里,再在另一个节点,从本身开始顺着父节点找,直到找到和第一个节点并且存在于第一个数组里,这样,第一个数组从0开始到这个公共节点和第二个节点的从这个节点到自己本身的所有节点就是这俩节点的最短路径。
举个实在例子(意见抽取):

dependency tree是:


属性之间的最短路径:

注意的是,这个路径上每次经过的线(也就是他们俩的关系),这里的路径就是这个。
属性与评价之间的最短路径:

从这两组最短路径很明显看出谁跟谁更亲近,这也是最短路径的一个应用。
应用
短语缩句
提取文本主要内容
文本分类
情感分析
意见抽取等
用途还是极其广泛的。很多论文中现在还继续在用呢。
每日托福单词
symbiosis
n.共生,互惠
interstellar adj.星际的
promise v.承诺 n.成功的迹象,光明的前景
probe v.调查,研究
paradox n.矛盾
推荐阅读:
欢迎关注深度学习自然语言处理公众号,我会在这里记录自己在路上的一点一滴!再小的人也有自己的品牌!期待和你一起进步!

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。