【干货】GRU神经网络

现在目前用的最多的三种神经网络是CNN,LSTM,GRU。其中,后两者都是RNN的变种,去年又给RNN发明了个SRU(优点是train RNN as fast as CNN),SRU以后再讲,目前先消化了这个GRU再说。
GRU,Gated Recurrent Unit,门控循环单元。意思大概理解就是在RNN上多加了几个门,目的和LSTM基本一样,为了加强RNN神经网络的记忆能力。
我们先来回忆下最初的SimpleRNN

其中a是记忆单元,g是激活函数,x是输入,b偏执bias,t是时间点。
画图就是这样的:
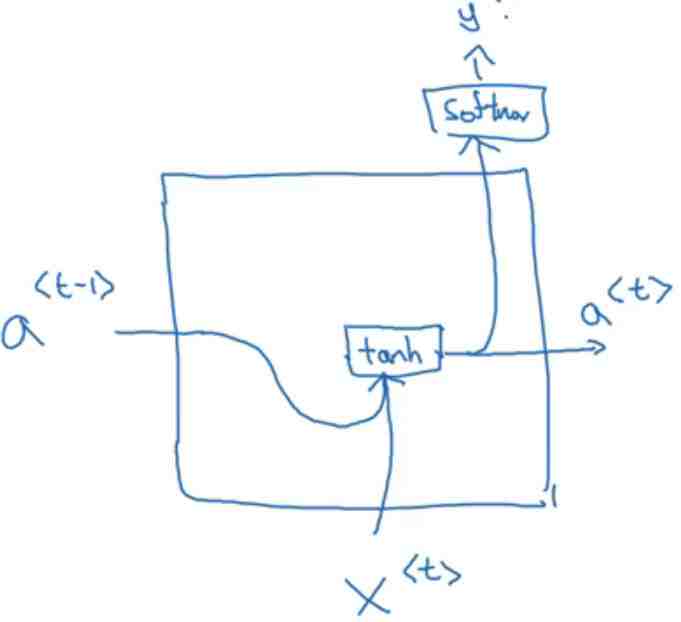
比如下面的一个机器翻译的例子。
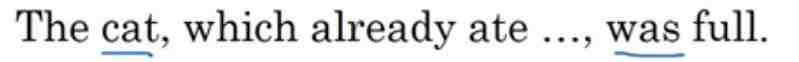
单数cat和was相聚甚远,如果考虑到SimpleRNN的长时间记忆会导致梯度消失的重大问题,有些人就在论文中提出了 GRU (Simplified)简化版。
首先,GRU的记忆单元是C

(也就是说上面的simpleRNN的a的功能给了C,主要是为了和LSTM区别开)
进入单元后,将用C~代替C:

重点来了,GRU的真正重要的思想是有一个 gamma u门,这个是希腊文,你看这个多像门呀,u代表update更新的意思,可以说这个是更新门。
gamma u门,这个是希腊文,你看这个多像门呀,u代表update更新的意思,可以说这个是更新门。


因为要设置在0-1之间,所以用的是sigmoid激活函数。实际中,经常非常接近0或1。
我们假设cat,用一个bit记录这个特征,单数设为1,复数的话设为0。(真正网络中会有自己独特的特征记法)

我们希望这个记忆单元C=1能一直保留到was那里,如

即使不是1,实际上也不可能不变是1的,但是只要和1别差距太大就行。其他的特征让C中用其他的参数记录就行,别影响我cat的就行。
那么怎么才能保证cat的特征单元不变呢?这就用到下一个门了:

看上面的公式,我们想,怎么才能让C_t依然等于C_t-1时刻呢?那么就是等于0的时候(这个肯定是理想情况了)
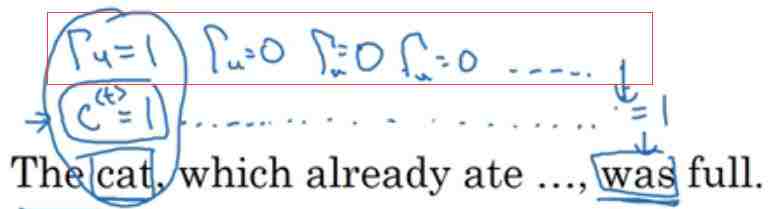
这个时候时间到了was这里时,C中还记着cat单数的事呢。而实际上,

是个负很大的数,也就是经过sigmoid后接近0了。所以,上述的情况是可以的。
到这里,这个简化版的GRU基本讲完了,看看可视化单元:
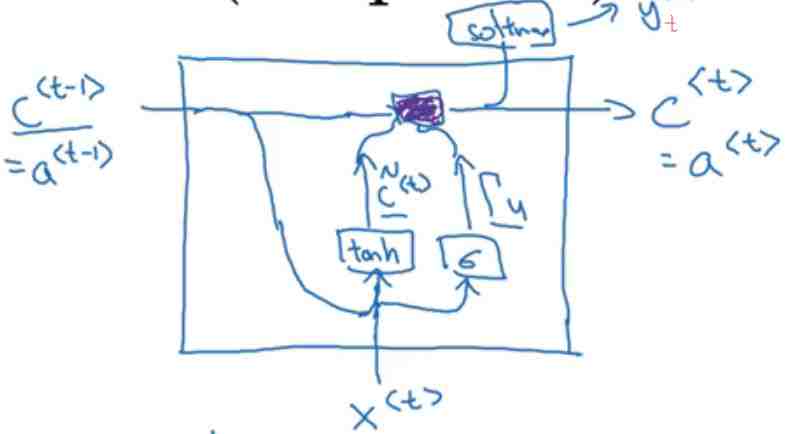
公式为:
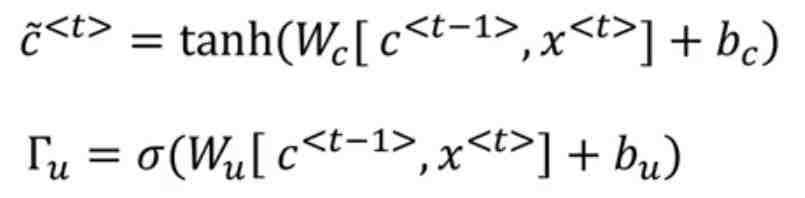
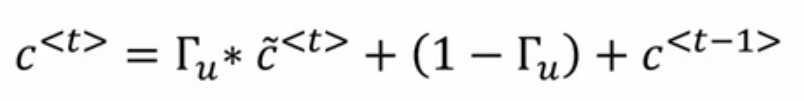
是不是也看到简化俩字了?
是的没错,经过研究者的不断探究,终于研究出来一种适合几乎各种研究实验的新型GRU网络是这样的:

这个GRU可以经过经
过更加深度的训练而保持强壮记忆力!
这里的第一个公式:


而这个 是什么矩阵呢?刚好第三个式子
是什么矩阵呢?刚好第三个式子

解释了的意思,其中W_r是新的参数。
好啦,这里就真的讲完了。
以上来自自己学习Andrew课程的笔记。
欢迎关注深度学习自然语言处理公众号,我会在这里记录自己在路上的一点一滴!期待和你一起进步!

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。