TreeLSTM Sentiment Classification
阅读大概需要5分钟
昨天的周日讨论班讲的是TreeLSTM Sentiment Classification,主讲人:王铭涛
今天我来做一下总结。
下面的图片来自于 王铭涛的ppt
导读
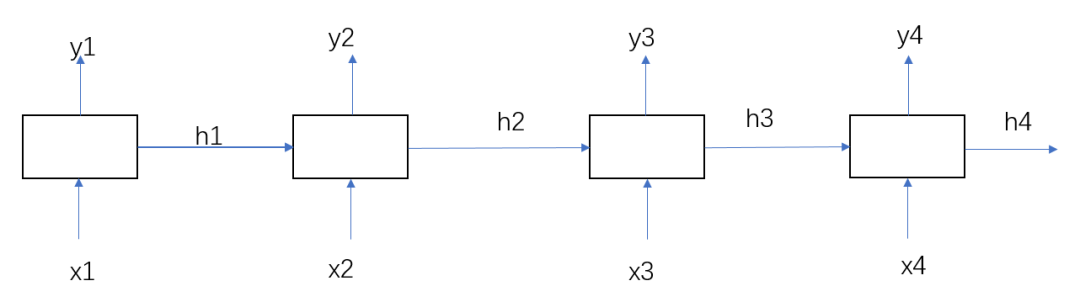
我们一步一步来。先说最基础的RNN
结构:
公式为:
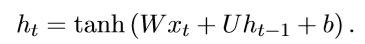
就一个简单的隐层h。
但是RNN的缺点是会有梯度爆炸或者梯度消失问题。这里我就不详细解释了。下面推荐阅读有我之前的RNN,LSTM详细讲解,想更深一步了解的可以去看看。
因为这个致命的问题,有人提出了LSTM网络,改善了RNN的缺点,我们来回顾下:
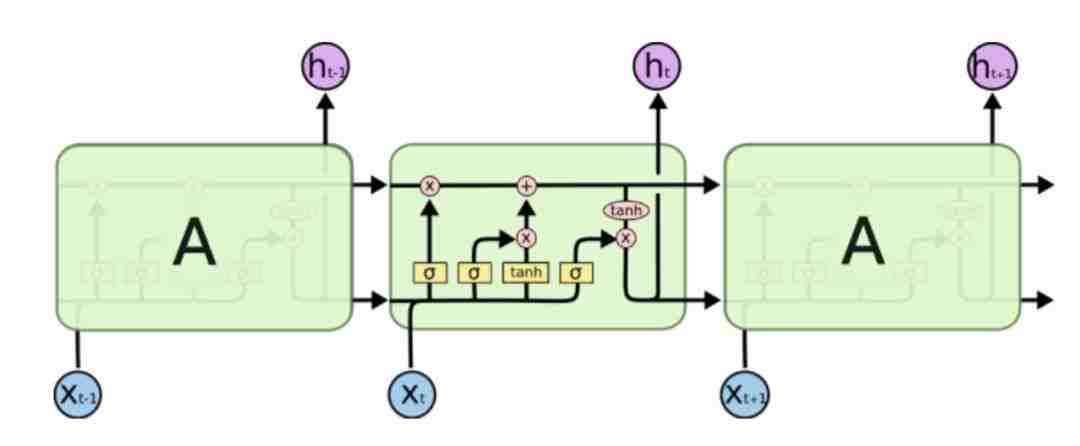
重新添加了输入门i,输出门o,遗忘门f和记忆单元C,外加之前的一个隐层h(此h非RNN的h,公式可见区别,但都是隐层)。
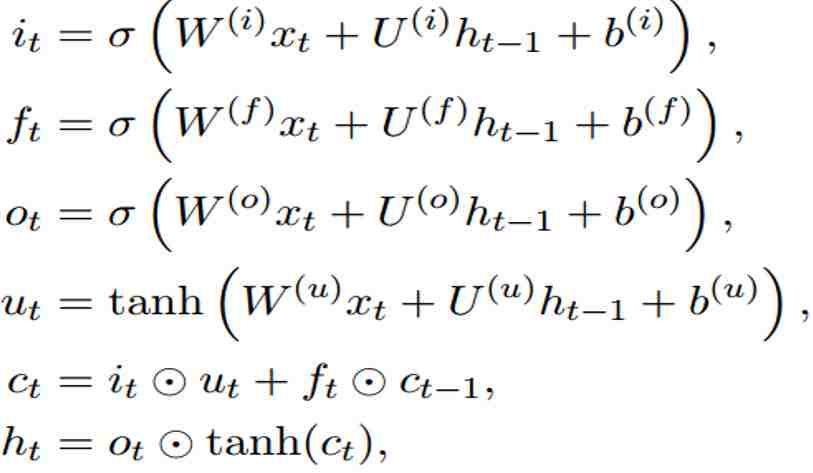
这种普通的LSTM都是解决线性问题的。例如常用的应用之句子分类:
每个词在随着时间序列的增加而不断地依次进入LSTM网络。
这种方法有明显的局限性:当前词的输入需要依赖前一步词的输入。但是如果我当前词要进行运算,而此时前一步词还没有进行计算可怎么办?比如下面的基于依存树的情感分类。(依存树的详细讲解在今晚凌晨的推文。)
TreeLSTM
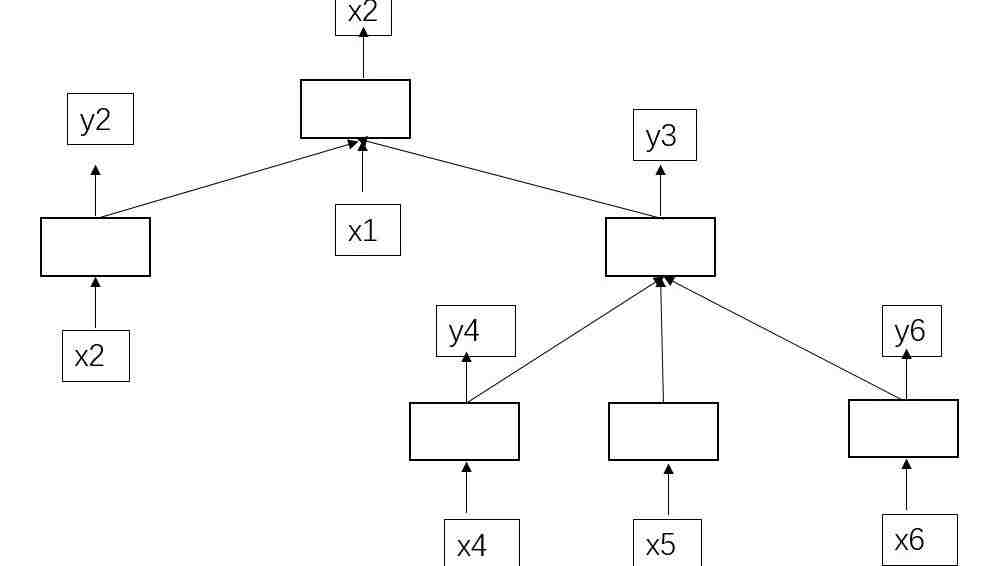
比如,这是一棵依存树的抽象表达(如果暂时不知道依存树的就把这个当成一棵树):
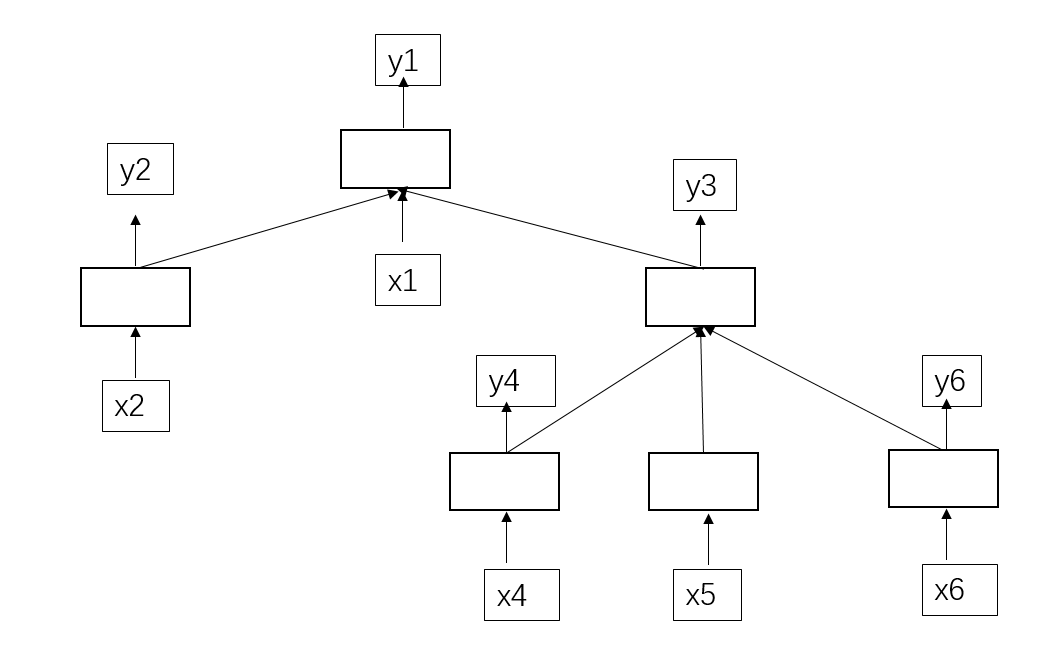
空白方框就LSTM的一个单元。文本序列为x1,x2,x4,x5,x6。(x3ppt中少画了,谅解)
x是输入的序列,y是每个x输入后经过LSTM一个时间片段的预测输出。我们可以看出(y5你们能看出是哪个),y4的产生依靠于x4的输入,y5的产生依靠于x5的输入,y6的产生依靠于x6的输入;y3产生需要依赖于y4,y5,y6的输入,y2的产生依靠于x2的输入;y1的产生依靠于y2,x1,y3的输入。这个显然就不能用到普通LSTM了。这时候TreeLSTM就登场上了历史舞台,开始绽放放光彩!
既然TreeLSTM和普通LSTM不一样了,那么咱们怎么计算他们呢?
虽说不一样,其实也是有相同的地方。比如普通LSTM当前时间段需要的输入是在执行在本时间段以前就产生了。这样就能一个接一个的运行下去。
TreeLSTM也一样,我们看图:
我们先找y2,y4,y5,y6的产生依赖于的x2,x4,x5,x6都已经存在,那么我们就能通过x2,x4,x5,x6分别过自己的隐层,得到对应的y2,y4,y5,y6;类似的,y2,y3也能相继产生;接着最终的y1也产生了。
计算逻辑
那这样的到底怎么个呢?暂时我知道的有两种方法
前提:
如果当前节点的孩子节点有了值(就是有了y),那么我们就将该孩子节点与当前节点的度去掉。
方法一
当前节点入度为0的时候,也就是计算它的所有准备条件都有了的时候,就能对它进行计算了。
所以,这个方法总结就是入度为0的节点都可以计算,然后更新每个节点的入度,再重复该操作。
方法二
层次遍历。最下面的从最下面的开始计算,最下面的肯定是可以直接计算的。然后刷新,再计算。
这两种方法在自己以后优化batch的时候很有用的。
具体TreeLSTM计算分析
我们找具体找一个分析:
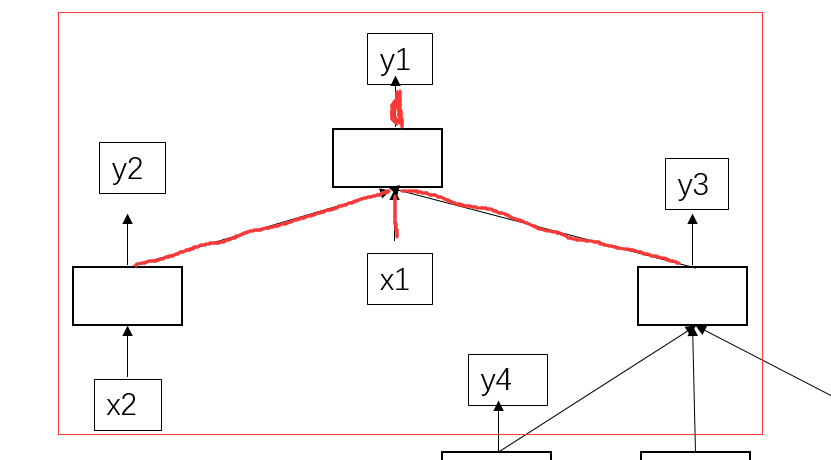
y1的产生依靠于y2,x1,y3的输入。那具体怎么计算的呢?
这里有张计算图,请看:
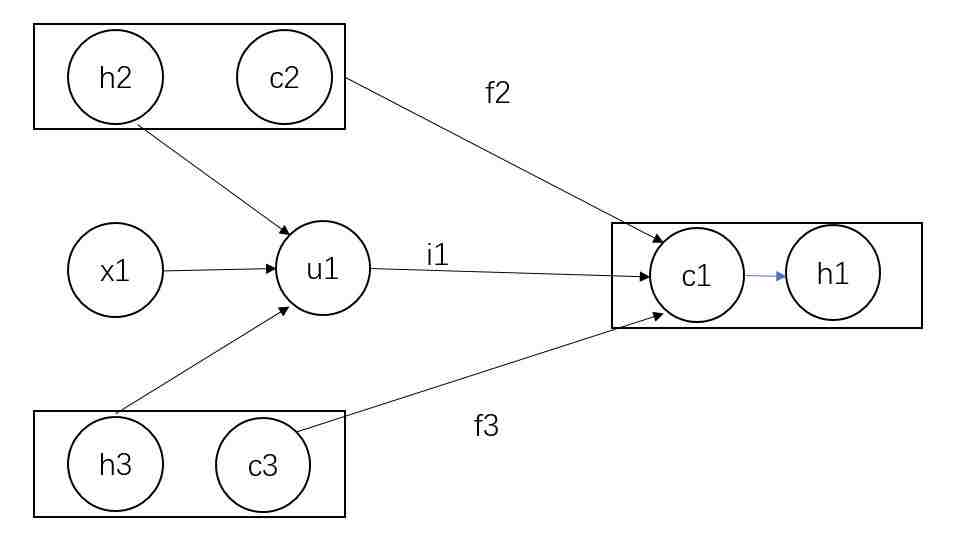
其中h为LSTM的隐层,c为LSTM的记忆单元。
公式为(在普通LSTM上稍微修改了下):
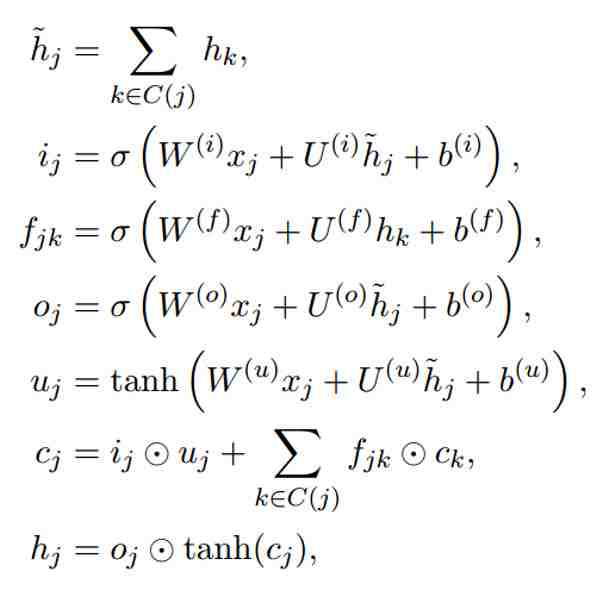
根据公式,我们来梳理下上面计算图:
h2,h3求和再与x1进行
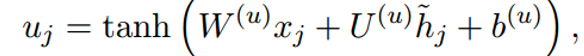
得到u1。
c2,f2与c3,f3分别按位相乘再求和,再加上u1,i1按位相乘,最后两个和相加即可,得到c1。(i1怎么算,公式里有。)
最后通过该公式
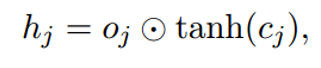
得到隐层h1。
计算loss
每个隐层y都要经过一个线性层,映射到具体的类别上,就是每个x对应一个类别,公式为:
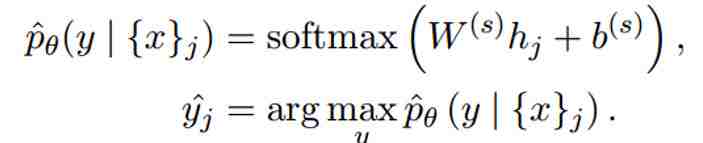
最终的
损失函数为:
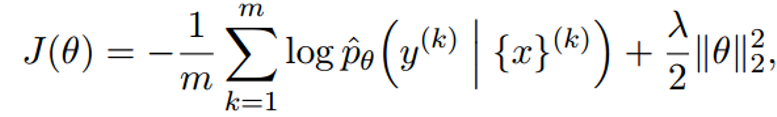
这个损失函数用的是交叉熵,最后是一个正则化。我之前也讲过,放到下面的推荐里了。
每日托福单词
handedness n.用手习惯;旋向性
confine v.限制
fashion n.方式 v.制作
juvenile adj.青年的;幼稚的
mar v.损害,破坏
下一篇:
详解依存树的来龙去脉
推荐阅读:
欢迎关注深度学习自然语言处理公众号,我会在这里记录自己在路上的一点一滴!再小的人也有自己的品牌!期待和你一起进步!

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。