几张图告诉你什么是word2vec

参考文章: https://www.jianshu.com/p/471d9bfbd72f
理解word2vec之前,首先来理解一下什么是One-Hot 编码,这个简单的编码方法处理可枚举的特征时还是很有用的。
编码
One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:
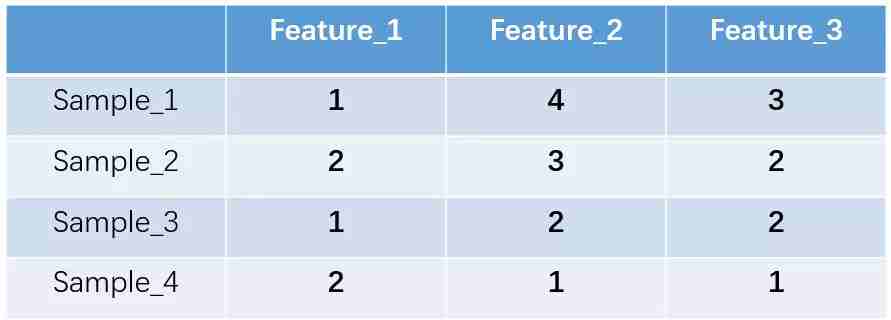
我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和feature_3各有4种取值(状态)。one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。上述状态用one-hot编码如下图所示:
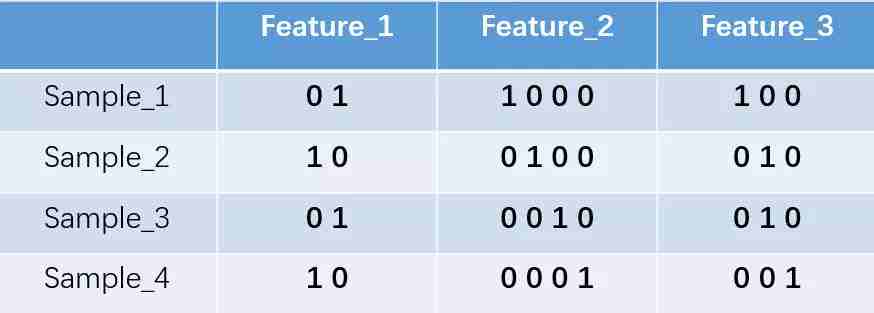
说白了就是,一个特征有多少种可能的取值,那么就用多少位二进制表示,所以可以看到,这种编码方法只适用于可枚举完的特征,对于连续特征没法完全枚举的,这个时候需要灵活处理下,比如对某个范围内的数当成一个值。
再考虑几个例子,比如有三个特征:
["male", "female"]
["from Europe", "from US", "from Asia"]
["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
将它换成独热编码后,应该是:
feature1=[01,10]
feature2=[001,010,100]
feature3=[0001,0010,0100,1000]
优缺点分析
•优点:一是解决了分类器不好处理离散数据的问题,二是在一定程度上也起到了扩充特征的作用。•缺点:在文本特征表示上有些缺点就非常突出了。首先,它是一个词袋模型,不考虑词与词之间的顺序(文本中词的顺序信息也是很重要的);其次,它假设词与词相互独立(在大多数情况下,词与词是相互影响的);最后,它得到的特征是离散稀疏的。
为什么得到的特征是离散稀疏的?
上面举例比较简单,但现实情况可能不太一样。比如如果将世界所有城市名称作为语料库的话,那这个向量会过于稀疏,并且会造成维度灾难。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0。
可以看到,当城市数比较大的时候,每一个城市表示的向量是非常长的,这就导致了很大的浪费,因为里面一大堆0几乎是没有用的。
一个最简单粗暴的方法就是降维了,比如PCA操作,降维后的特征肯定就不是0-1的特征了,而是小数表示的特征,这样才能用很低的维度覆盖大的特征区间。
当然降维的方法不止PCA,还有很多,我们要说的word2vec就是一种。word2vec
说起word2vec,首先需要简单理解下基于神经网络的自编码模型,自编码,其实就是一种降维方法。基础自编码的网络结构如下:
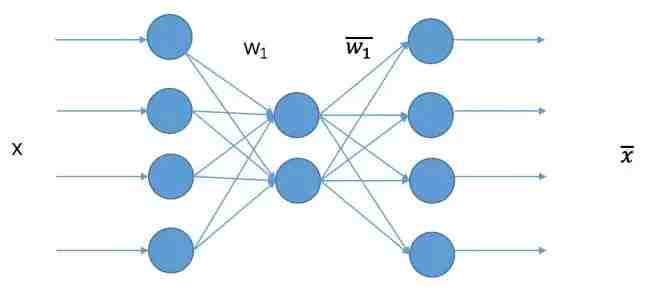
网络的输入就是一组特征,对应到本文就是一组0-1串的特征,输出维度和输入维度一样,中间有一层隐含层映射,我们的目的就是训练网络使得输出X 尽可能等于输入X。训练好以后,任意一个x进入模型都可以得到中间层的输出结果,此时中间层的输出结果就可以认为是降维后的结果。像本图所示,就是一个4维降到2维的网络模型。
说完自编码,我们再来看看什么是word2vec。
因为word2vec是NLP里面应用的,是对词的一个编码,NLP里面一个很大的特点是什么呢?就是一段话中,一个词的表示是和上下文相关的。也就是说这是一个带有时间先后与相对顺序的表示。那么既要实现上面的降维,又要兼顾词的先后顺序关系,word2vec就是要解决这样的问题。
怎么解决的?首先还是有一个基础的神经网络自编码模型:
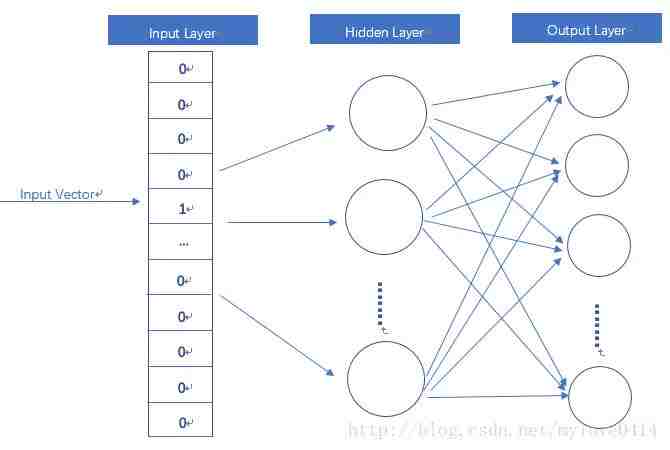
那么怎么考虑上下文的信息呢?很简单,输入的时候不光是一个词,而是上下文多个词一起当成输入:
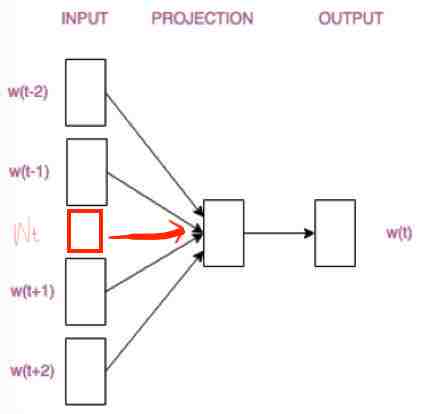
这是一种多对一的模型(CBOW),还有一种一对多(Skip-Gram)模型,我们先说这种多对一模型。
CBOW的训练模型如图所示:
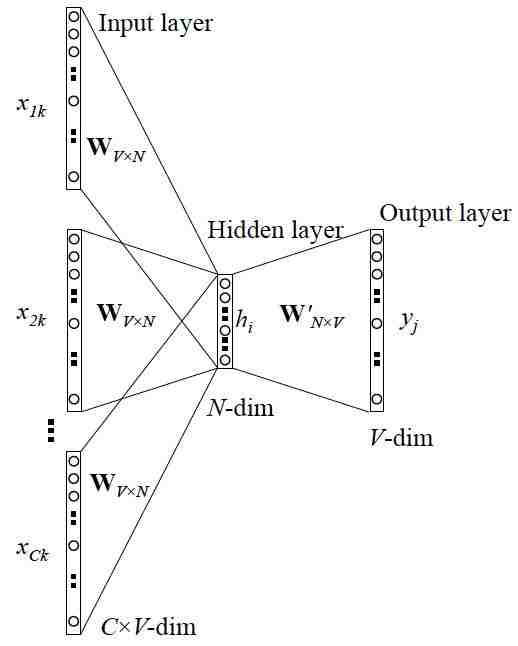
乍一看有点糊涂,不要紧,我们需要明白的是,这个网络结构就是最开始的自编码网络,只不过它的输入不是一次性输入的,而是好几批输入的,而隐含层的结果是好几批输入的加权平均值。
详细的过程为:
1 输入层:上下文单词的onehot.
2 这些单词的onehot分别乘以共享的输入权重矩阵W.
3 所得的向量相加求平均作为隐层向量.
4 乘以输出权重矩阵W {NV}
5 得到输出向量。
6 输出向量与真实单词的onehot做比较,误差越小越好。
这样就可以训练网络了。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的词向量(word embedding),这个矩阵(所有单词的word embedding)也叫做look up table(其实这个look up table就是矩阵W自身),也就是说,任何一个单词的onehot乘以这个矩阵都将得到自己的词向量。有了look up table就可以免去训练过程直接查表得到单词的词向量了。
相比于原始的自编码,word2vec最大的不同点在于输入上,要考虑先后关系的自编码,这一点值得好好理解下。
这是多对一的方式,还有一种一对多的方式:同理,目的为了保证上下文的顺序关系的同时实现降维。
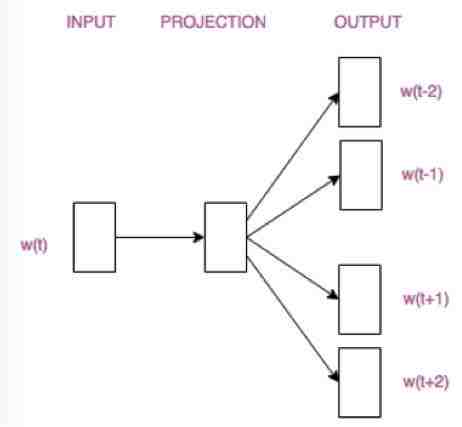
word2vec训练最终我们需要的是训练出来的权重矩阵,有了此权重矩阵就能实现输入单词的onehot降维,同时这个降维还包含了上下文的先后循序关系。这就是word2vec。
推荐阅读

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。