Transformer聊天机器人教程

源 / 专知
在这篇文章中,我们将演示如何构建Transformer聊天机器人。 本文聚焦于:使用TensorFlow Dataset并使用tf.data创建输入管道来使用Cornell Movie-Dialogs Corpus,使用Model子类化实现MultiHeadAttention,使用Functional API实现Transformer。
Transformer 网络结构
Attention is All You Need 提出的Transformer是一种神经网络结构。
Transformer模型使用自注意力堆栈而不是RNN或CNN来处理可变大小的输入。这种通用架构具有许多优点:
- 它没有假设数据的时间/空间关系。这是处理一组对象的理想选择。
- 可以并行计算层输出,而不是像RNN那样的序列处理。
- 远距离的元素可以影响彼此的输出,而不会经过许多重复步骤或卷积层。
- 它可以学习远程依赖。
这种架构的缺点:
- 对于时间序列,每个时间序列输出是根据整个历史而不是仅输入和当前隐藏状态计算的。这可能效率较低。
- 如果输入确实具有时间/空间关系,则必须添加一些位置编码,否则模型将有效地看到一包单词。
数据集
我们使用Cornell Movie-Dialogs Corpus作为我们的数据集,其中包含超过10万对电影角色之间的超过220k个对话。
“+++ $ +++”被用作语料库数据集中所有文件的字段分隔符。
movie_conversations.txt具有以下格式:两个对话者的id,发生此对话的电影的ID以及行ID列表。 角色和电影信息可分别在movie_characters_metadata.txt和movie_titles_metadata.txt中找到。
u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L194’, ‘L195’, ‘L196’, ‘L197’]u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L198’, ‘L199’]u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L200’, ‘L201’, ‘L202’, ‘L203’]u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L204’, ‘L205’, ‘L206’]u0 +++$+++ u2 +++$+++ m0 +++$+++ [‘L207’, ‘L208’]movie_lines.txt具有以下格式:会话行的ID,该行角色的ID,电影的ID,角色的名称和行的文本。
L901 +++$+++ u5 +++$+++ m0 +++$+++ KAT +++$+++ He said everyone was doing it. So I did it.L900 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ As in…L899 +++$+++ u5 +++$+++ m0 +++$+++ KAT +++$+++ Now I do. Back then, was a different story.L898 +++$+++ u0 +++$+++ m0 +++$+++ BIANCA +++$+++ But you hate JoeyL897 +++$+++ u5 +++$+++ m0 +++$+++ KAT +++$+++ He was, like, a total babe我们将使用以下步骤构建输入管道:
- 从move_conversations.txt和movie_lines.txt中提取对话对的列表
- 通过删除每个句子中的特殊字符来预处理每个句子。
- 使用TensorFlow数据集SubwordTextEncoder构建标记生成器(将文本映射到ID和ID到文本)。
- 对每个句子进行标记并添加START_TOKEN和END_TOKEN以指示每个句子的开头和结尾。
- 过滤掉包含超过MAX_LENGTH 个令牌的句子。
- 将标记化句子填充到MAX_LENGTH
- 使用标记化句子构建tf.data.Dataset
请注意,Transformer是一个自回归模型,它一次预测一个部分,并使用其输出到目前为止决定下一步做什么。 在训练期间,此示例使用teach-Forcing。 无论模型在当前时间步骤预测什么,teach-forcing都会将真实输出传递到下一个时间步。
完整的预处理代码可以在文末代码链接的Prepare Dataset部分找到。
i really , really , really wanna go , but i can t . notunlessmy sister goes .i m workin on it . but she doesn t seem to be goin for him .Attention
与许多序列到序列模型一样,Transformer也包括编码器和解码器。 但是,Transformer不使用循环或卷积层,而是使用多头注意力层,其中包含多个缩放的点积注意力。
缩放点积注意力
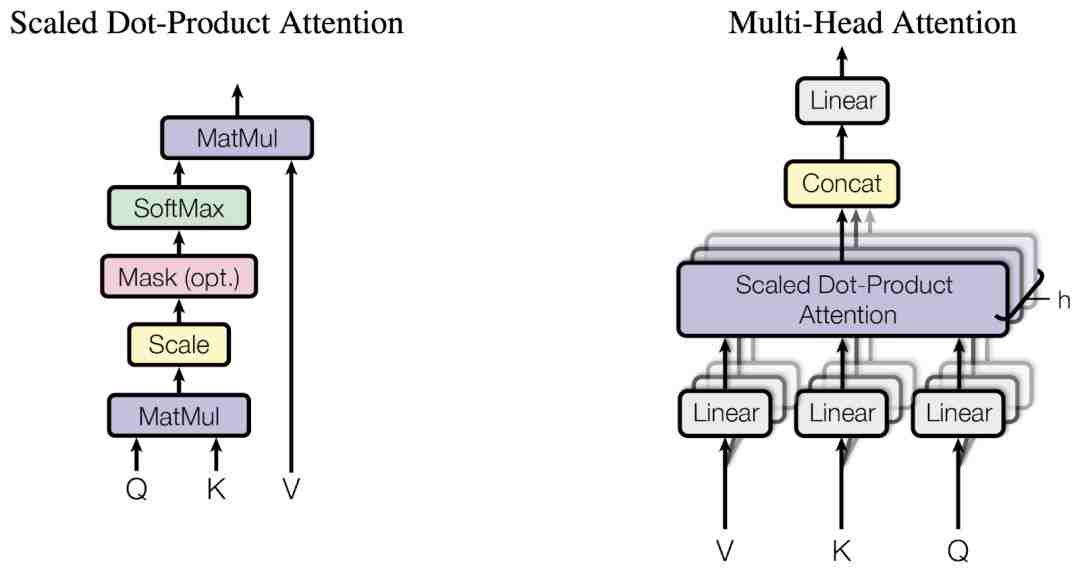
缩放的点积注意函数有三个输入:Q(查询),K(键),V(值)。 用于计算注意力的等式是:
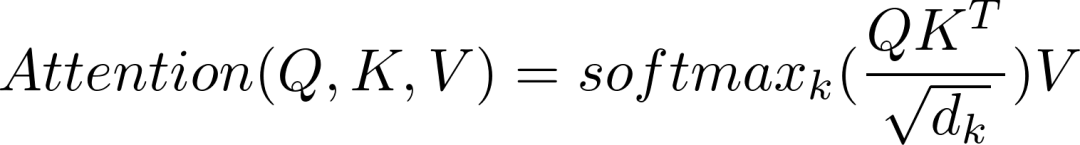
当softmax应用于K时,其值决定了给查询的重要性。 输出表示注意力量和值的乘积。 这可以确保我们想要关注的单词保持原样,并且不相关的单词被刷新。
defscaled_dot_product_attention(query, key, value, mask): matmul_qk = tf.matmul(query, key, transpose_b=True) depth = tf.cast(tf.shape(key)[-1], tf.float32) logits = matmul_qk / tf.math.sqrt(depth)# add the mask zero out padding tokens.if mask isnotNone: logits += (mask * -1e9) attention_weights = tf.nn.softmax(logits, axis=-1)return tf.matmul(attention_weights, value)多头注意层
Sequential模型允许我们通过简单地将层叠在彼此之上来非常快速地构建模型;但是,对于更复杂和非顺序的模型,需要Functional API和Model子类。 tf.keras API允许我们混合和匹配不同的API样式。我最喜欢的Model子类化功能是调试功能。我可以在call()方法中设置一个断点,并观察每个层的输入和输出的值,就像一个numpy数组,这使调试变得更加简单。
在这里,我们使用Model子类来实现我们的MultiHeadAttention层。
多头注意力由四部分组成:
- 线性图层并分成头部。
- 缩放点产品注意力。
- 头部的连接。
- 最后的线性层。
每个多头注意块都以字典作为输入,包括查询,键和值。请注意,当使用带有Functional API的Model子类时,输入必须保存为单个参数,因此我们必须将查询,键和值包装为字典。
然后输入通过密集层并分成多个头。上面定义的scaled_dot_product_attention()应用于每个头。必须在注意步骤中使用适当的面罩。然后将每个头部的注意力输出连接起来并穿过最后的致密层。
查询,键和值不是一个单独的注意头,而是分成多个头,因为它允许模型共同处理来自不同表示空间的不同位置的信息。在拆分之后,每个头部具有降低的维度,因此总计算成本与具有全维度的单个头部注意力相同。
class MultiHeadAttention(tf.keras.layers.Layer): def __init__(self, d_model, num_heads, name="multi_head_attention"): super(MultiHeadAttention, self).__init__(name=name) self.num_heads = num_heads self.d_model = d_model assert d_model % self.num_heads == 0 self.depth = d_model // self.num_heads self.query_dense = tf.keras.layers.Dense(units=d_model) self.key_dense = tf.keras.layers.Dense(units=d_model) self.value_dense = tf.keras.layers.Dense(units=d_model) self.dense = tf.keras.layers.Dense(units=d_model) def split_heads(self, inputs, batch_size): inputs = tf.reshape( inputs, shape=(batch_size, -1, self.num_heads, self.depth)) return tf.transpose(inputs, perm=[0, 2, 1, 3]) def call(self, inputs):query, key, value, mask = inputs[ query ], inputs[ key ], inputs[ value ], inputs[ mask ] batch_size = tf.shape(query)[0]# linear layersquery = self.query_dense(query)key = self.key_dense(key)value = self.value_dense(value)# split headsquery = self.split_heads(query, batch_size)key = self.split_heads(key, batch_size)value = self.split_heads(value, batch_size) scaled_attention = scaled_dot_product_attention(query, key, value, mask) scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model)) outputs = self.dense(concat_attention)return outputsTransformer
Transformer使用堆叠的多头注意力和密集层用于编码器和解码器。 编码器将符号表示的输入序列映射到连续表示序列。 然后,解码器采用连续表示并一次一个元素地生成符号的输出序列。
位置编码
由于Transformer不包含任何重复或卷积,因此添加位置编码以向模型提供关于句子中单词的相对位置的一些信息。
将位置编码矢量添加到嵌入矢量。 嵌入表示在d维空间中的标记,其中具有相似含义的标记将彼此更接近。 但嵌入不会编码句子中单词的相对位置。 因此,在添加位置编码之后,基于在d维空间中它们的含义和它们在句子中的位置的相似性,单词将彼此更接近。
我们使用Model子类化实现了Positional Encoding,我们将编码矩阵应用于call()中的输入。
classPositionalEncoding(tf.keras.layers.Layer):def__init__(self, position, d_model):super(PositionalEncoding, self).__init__()self.pos_encoding = self.positional_encoding(position, d_model)defget_angles(self, position, i, d_model): angles = 1 / tf.pow(10000, (2 * (i // 2)) / tf.cast(d_model, tf.float32))return position * anglesdefpositional_encoding(self, position, d_model): angle_rads = self.get_angles( position=tf.range(position, dtype=tf.float32)[:, tf.newaxis], i=tf.range(d_model, dtype=tf.float32)[tf.newaxis, :], d_model=d_model)# apply sin to even index in the array sines = tf.math.sin(angle_rads[:, 0::2])# apply cos to odd index in the array cosines = tf.math.cos(angle_rads[:, 1::2]) pos_encoding = tf.concat([sines, cosines], axis=-1) pos_encoding = pos_encoding[tf.newaxis, ...]return tf.cast(pos_encoding, tf.float32)defcall(self, inputs):return inputs + self.pos_encoding[:, :tf.shape(inputs)[1], :]Transformer实现
可以堆叠类似于Sequential模型的层,但没有它作为顺序模型的约束,并且不像模型子类化那样预先声明我们需要的所有变量和层。 Functional API的一个优点是它在构建模型时验证模型,例如检查每个层的输入和输出形状,并在出现不匹配时引发有意义的错误消息。
我们正在使用Functional API实现我们的编码层,编码器,解码层,解码器和Transformer本身。
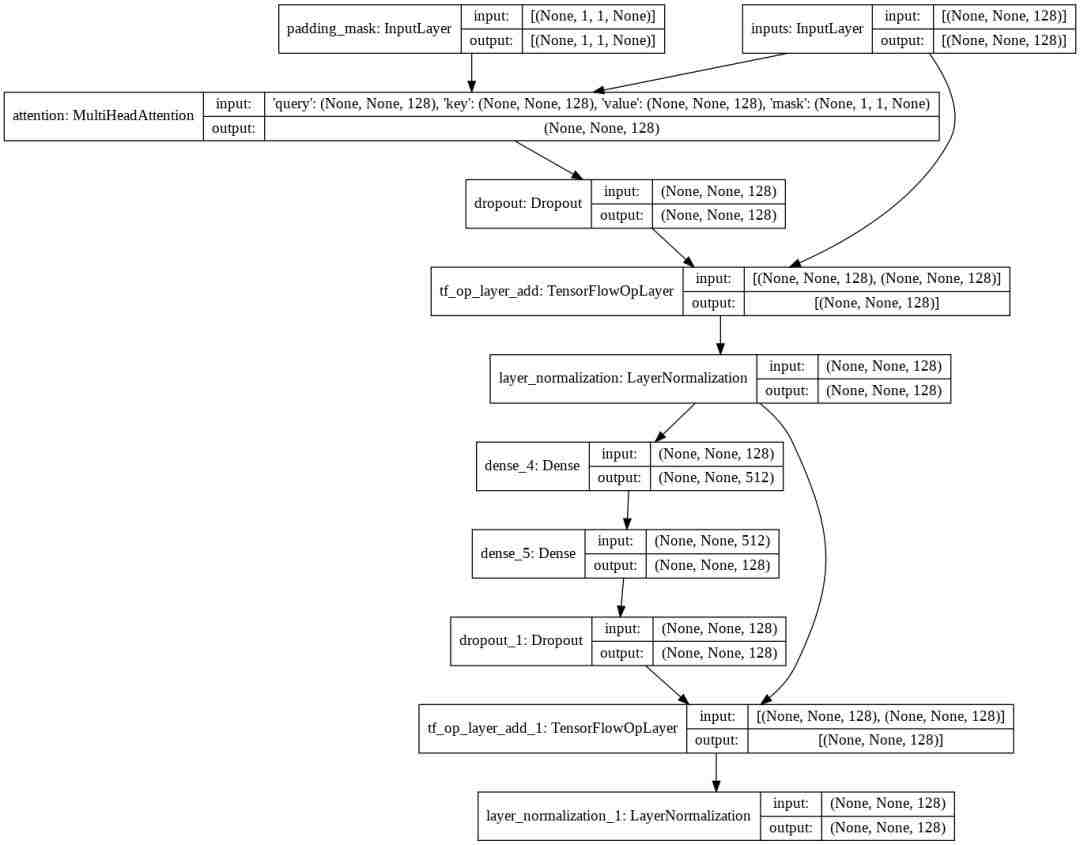
嵌入层
每个嵌入层由子层组成:
- 多头注意
- 2个Dense层然后Dropout
defencoder_layer(units, d_model, num_heads, dropout, name="encoder_layer"): inputs = tf.keras.Input(shape=(None, d_model), name="inputs") padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask") attention = MultiHeadAttention( d_model, num_heads, name="attention")({ query : inputs, key : inputs, value : inputs, mask : padding_mask }) attention = tf.keras.layers.Dropout(rate=dropout)(attention) attention = tf.keras.layers.LayerNormalization( epsilon=1e-6)(inputs + attention) outputs = tf.keras.layers.Dense(units=units, activation= relu )(attention) outputs = tf.keras.layers.Dense(units=d_model)(outputs) outputs = tf.keras.layers.Dropout(rate=dropout)(outputs) outputs = tf.keras.layers.LayerNormalization( epsilon=1e-6)(attention + outputs)return tf.keras.Model( inputs=[inputs, padding_mask], outputs=outputs, name=name)我们可以使用tf.keras.utils.plot_model()来可视化我们的模型。
编码器
编码器包括:
- 输入嵌入
- 位置编码
- N个编码器层
输入通过嵌入进行,嵌入与位置编码相加。 该求和的输出是编码器层的输入。 编码器的输出是解码器的输入。
def encoder(vocab_size,num_layers,units,d_model,num_heads,dropout,name="encoder"):inputs = tf.keras.Input(shape=(None,), name="inputs")padding_mask = tf.keras.Input(shape=(1, 1, None), name="padding_mask")embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)embeddings*= tf.math.sqrt(tf.cast(d_model, tf.float32))embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)fori in range(num_layers):outputs = encoder_layer(units=units,d_model=d_model,num_heads=num_heads,dropout=dropout,name="encoder_layer_{}".format(i),padding_mask])returntf.keras.Model(inputs=[inputs, padding_mask], outputs=outputs, name=name)解码器层
每个解码器层由子层组成:
- 多头注意力。 值和键接收编码器输出作为输入。 查询接收来自掩蔽的多头关注子层的输出。
- 2个Dense层然后Dropout
当查询从解码器的第一个注意块接收输出,并且键接收编码器输出时,注意权重表示基于编码器输出给予解码器输入的重要性。 换句话说,解码器通过查看编码器输出并自我关注其自己的输出来预测下一个字。
defdecoder_layer(units, d_model, num_heads, dropout, name="decoder_layer"): inputs = tf.keras.Input(shape=(None, d_model), name="inputs") enc_outputs = tf.keras.Input(shape=(None, d_model), name="encoder_outputs") look_ahead_mask = tf.keras.Input( shape=(1, None, None), name="look_ahead_mask") padding_mask = tf.keras.Input(shape=(1, 1, None), name= padding_mask ) attention1 = MultiHeadAttention( d_model, num_heads, name="attention_1")(inputs={ query : inputs, key : inputs, value : inputs, mask : look_ahead_mask }) attention1 = tf.keras.layers.LayerNormalization( epsilon=1e-6)(attention1 + inputs) attention2 = MultiHeadAttention( d_model, num_heads, name="attention_2")(inputs={ query : attention1, key : enc_outputs, value : enc_outputs, mask : padding_mask }) attention2 = tf.keras.layers.Dropout(rate=dropout)(attention2) attention2 = tf.keras.layers.LayerNormalization( epsilon=1e-6)(attention2 + attention1) outputs = tf.keras.layers.Dense(units=units, activation= relu )(attention2) outputs = tf.keras.layers.Dense(units=d_model)(outputs) outputs = tf.keras.layers.Dropout(rate=dropout)(outputs) outputs = tf.keras.layers.LayerNormalization( epsilon=1e-6)(outputs + attention2)return tf.keras.Model( inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask], outputs=outputs, name=name)解码器
解码器包括:
- 输出嵌入
- 位置编码
- N个解码器层
目标通过嵌入与位置编码相加。 该求和的输出是解码器层的输入。 解码器的输出是最终线性层的输入。
defdecoder(vocab_size,num_layers,units,d_model,num_heads,dropout,name= decoder ):inputs = tf.keras.Input(shape=(None,), name= inputs )enc_outputs = tf.keras.Input(shape=(None, d_model), name= encoder_outputs )look_ahead_mask = tf.keras.Input(shape=(1, None, None), name= look_ahead_mask )padding_mask = tf.keras.Input(shape=(1, 1, None), name= padding_mask )embeddings = tf.keras.layers.Embedding(vocab_size, d_model)(inputs)embeddings*= tf.math.sqrt(tf.cast(d_model, tf.float32))embeddings = PositionalEncoding(vocab_size, d_model)(embeddings)outputs = tf.keras.layers.Dropout(rate=dropout)(embeddings)fori in range(num_layers):outputs = decoder_layer(units=units,d_model=d_model,num_heads=num_heads,dropout=dropout,name= decoder_layer_{} .format(i),=[outputs, enc_outputs, look_ahead_mask, padding_mask])returntf.keras.Model(inputs=[inputs, enc_outputs, look_ahead_mask, padding_mask],outputs=outputs,name=name)Transformer
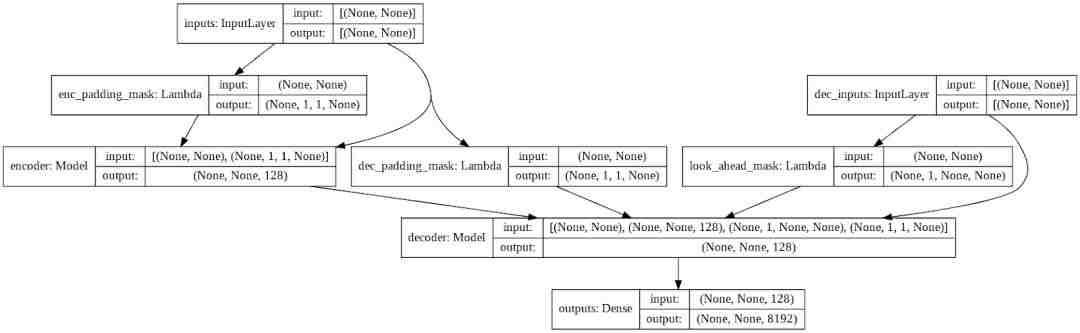
Transformer由编码器,解码器和最终线性层组成。 解码器的输出是线性层的输入,并返回其输出。
enc_padding_mask和dec_padding_mask用于屏蔽所有填充token。 look_ahead_mask用于屏蔽序列中的未来标记。 随着掩码的长度随着输入序列长度的变化而变化,我们将使用Lambda层创建这些掩码。
def transformer(vocab_size,num_layers,units,d_model,num_heads,dropout,name="transformer"):inputs = tf.keras.Input(shape=(None,), name="inputs")dec_inputs = tf.keras.Input(shape=(None,), name="dec_inputs")enc_padding_mask = tf.keras.layers.Lambda(output_shape=(1, 1, None),name= enc_padding_mask )(inputs) # mask the future tokens for decoder inputs at the 1st attention blocklook_ahead_mask = tf.keras.layers.Lambda(create_look_ahead_mask,output_shape=(1, None, None),name= look_ahead_mask )(dec_inputs) # mask the encoder outputs for the 2nd attention blockdec_padding_mask = tf.keras.layers.Lambda(output_shape=(1, 1, None),name= dec_padding_mask )(inputs)enc_outputs = encoder(vocab_size=vocab_size,num_layers=num_layers,units=units,d_model=d_model,num_heads=num_heads,dropout=dropout,=[inputs, enc_padding_mask])dec_outputs = decoder(vocab_size=vocab_size,num_layers=num_layers,units=units,d_model=d_model,num_heads=num_heads,dropout=dropout,=[dec_inputs, enc_outputs, look_ahead_mask, dec_padding_mask])outputs = tf.keras.layers.Dense(units=vocab_size, name="outputs")(dec_outputs)returntf.keras.Model(inputs=[inputs, dec_inputs], outputs=outputs, name=name)训练模型
我们可以按如下方式初始化Transformer:
NUM_LAYERS = 2D_MODEL = 256NUM_HEADS = 8UNITS = 512DROPOUT = 0.1model = transformer( vocab_size=VOCAB_SIZE, num_layers=NUM_LAYERS, units=UNITS, d_model=D_MODEL, num_heads=NUM_HEADS, dropout=DROPOUT)在定义了我们的损失函数,优化器和度量之后,我们可以使用model.fit()简单地训练我们的模型。 请注意,我们必须屏蔽我们的损失函数,以便忽略填充标记,我们可以自定义学习速率。
def loss_function(y_true, y_pred):y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))loss = tf.keras.losses.SparseCategoricalCrossentropy( from_logits=True, reduction= none )(y_true, y_pred)mask = tf.cast(tf.not_equal(y_true, 0), tf.float32)loss = tf.multiply(loss, mask)returntf.reduce_mean(loss)classCustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):def__init__(self, d_model, warmup_steps=4000):super(CustomSchedule, self).__init__()self.d_model = d_modelself.d_model = tf.cast(self.d_model, tf.float32)self.warmup_steps = warmup_stepsdef__call__(self, step):arg1 = tf.math.rsqrt(step)arg2 = step * (self.warmup_steps**-1.5)returntf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)learning_rate = CustomSchedule(D_MODEL)optimizer = tf.keras.optimizers.Adam( learning_rate, beta_1=0.9, beta_2=0.98, epsilon=1e-9)defaccuracy(y_true, y_pred): # ensurelabelshaveshape (batch_size, MAX_LENGTH - 1)y_true = tf.reshape(y_true, shape=(-1, MAX_LENGTH - 1))accuracy = tf.metrics.SparseCategoricalAccuracy()(y_true, y_pred)returnaccuracymodel.compile(optimizer=optimizer, loss=loss_function, metrics=[accuracy])EPOCHS = 20model.fit(dataset, epochs=EPOCHS)评估
为了评估,我们必须一次一个地推断一个步骤,并将前一个时间步的输出作为输入传递。
请注意,我们通常不会在推理期间应用dropout,但是我们没有为模型指定训练参数。 这是因为我们已经内置了训练和掩码,如果我们想运行模型进行评估,我们可以简单地调用模型(输入,训练= False)来以推理模式运行模型。
def evaluate(sentence):sentence = preprocess_sentence(sentence)sentence = tf.expand_dims(START_TOKEN + tokenizer.encode(sentence) + END_TOKEN, axis=0)output = tf.expand_dims(START_TOKEN, 0)for i in range(MAX_LENGTH):predictions = model(inputs=[sentence, output], training=False) # select the last word from the seq_len dimensionpredictions = predictions[:, -1:, :]predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32) # return the result if the predicted_id is equal to the end tokenif tf.equal(predicted_id, END_TOKEN[0]):break # concatenated the predicted_id to the output which is given to the decoder as its input.output = tf.concat([output, predicted_id], axis=-1)return tf.squeeze(output, axis=0)def predict(sentence):prediction = evaluate(sentence)predicted_sentence = tokenizer.decode([i for i in prediction if i < tokenizer.vocab_size])return predicted_sentence为了测试我们的模型,我们可以调用预测(句子)。
>>> output = predict(‘Where have you been?’)>>> print(output)i don t know . i m not sure . i m a paleontologist .代码链接:
https://github.com/tensorflow/examples/blob/master/community/en/transformer_chatbot.ipynb
原文链接:
https://medium.com/tensorflow/a-transformer-chatbot-tutorial-with-tensorflow-2-0-88bf59e66fe2
推荐阅读

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。