数据中心超融合以太技术(2023)
AI集群训练过程中,参数通过高速互联网络在不同的服务器间进行同步交互,这些通信流量具有共同的特征:流量成周期性、流数量少、流量长连接、并行任务间有强实时同步性要求,通信效率取决于最慢的节点,并且AI集群训练场景下,传输的数据量较大。上述的流量特征导致网络较易出现负载分担不均、整网吞吐下降的问题,从而影响AI集群训练的性能。
下载链接:
1、数据中心超融合以太技术白皮书
2、数据中心可持续发展能力要求
3、数据中心绿色设计白皮书(2023)
4、新型数据中心高安全技术体系白皮书
当前网络均衡的主流技术有三种,逐流(Flow-based)ECMP均衡、基于子流flowlet均衡和逐包(Packet-based)ECMP均衡。逐流ECMP均衡,是当前最为常用的负载均衡算法,基于流量的五元组进行HASH负载均衡,在流链接数量较多的场景下适用,它优势在于无乱序,劣势在于流数量较少时,例如AI训练场景下,存在HASH冲突问题,网络均衡效果不佳。基于子流flowlet均衡技术,它依赖于子流之间时间间隔GAP值的正确配置来实现均衡,但由于网路中全局路径级时延信息不可知,因此GAP值无法准确配置。同时,该技术存在接收端侧乱序的问题。逐包(Packet-based)ECMP均衡,理论上均衡度最好,但实际在接收端侧存在大量乱序问题,现实中几乎无使用案例。
现有创新的网络均衡技术NSLB是面向AI训练场景量身打造的,根据该场景下的流量特征,将搜集到的整网信息作为创新算路算法的输入,从而得到最优的流量转发路径,实现AI训练场景下整网流量100%的均衡度和AI训练性能的提升。
利用12台GPU服务器(每台服务器包含1块型号为Tesla v100S PCIe 32GB的GPU卡),4台华为交换机组成2级CLOS网络(其中2台交换机作为接入层交换机,每台下挂6台服务器,使用100GE单端口接入,2台交换机作为汇聚交换机,每台与接入层交换机之间使用6个100GE端口互联)的AI训练集群,运行开源Tensorflow深度学习平台上的VGG16深度学习网络模型。以下为采用NSLB技术运行单计算任务和多计算任务时,AI训练性能的提升结果。
Ring算法场景,运行单个计算任务下,使用NSLB技术对比典型ECMP负载分担技术,AI训练集性能最高提升113.41%。
Ring算法场景,运行两个计算任务下,使用NSLB技术对比典型ECMP负载分担技术,AI训练集性能最高提升57.29%。
高性能计算、AI模型训练等应用场景,以及数据中心网络/云网络在架构上的发展(资源池化),均要求网络传输排队时延和吞吐上的进一步性能提升。例如,为了保证性能损失在5%以内,数据库集群系统要求至少40Gbps的吞吐和3us的网络RTT。为了达到极低时延的传输,应当尽力降低网络设备上的排队时延,同时维持接近瓶颈链路满吞吐。
随着业务发放速度的不断加快,以及引入了VM、容器等虚拟化技术,网络流量的不确定性增加。而当前运维手段有限,仍然依靠传统网管和命令行方式进行查看、监控,分钟级的网络监控已经无法满足业务秒级体验保障的要求,往往被动感知故障。故障发生后,定位仍主要依赖专家经验,利用多种辅助工具,逐段定界、逐流分析、抓包定位,效率十分低下。
为了解决上述故障收敛慢的问题,提出了一种基于网络设备数据面的链路故障快速自愈技术,称为DPFF(Data Plane Fast Failover)。该技术基于转发芯片的硬件可编程能力构建。DPFF从传统的基于控制面软件协议的收敛方式演进到基于数据面硬件极速感知故障和快速换路的收敛方式,并且基于数据面硬件实现远程通告和快速换路,可达到亚毫秒级(<1ms)的收敛速度,将对业务性能的影响降至最低。该技术为高性能数据库、存储以及超算等关键应用提供了极致的高可靠性保证和稳定性体验。
实验室采用4台华为交换机组成2级CLOS网络(其中2台交换机作为接入层交换机,每台下挂>2台服务器,2台交换机作为汇聚交换机),利用vdbench 测试套件,客户端服务器与存储阵列建立两个连接,每连接8个qp,并发访问8个SSD磁盘。通过拔光纤模拟链路故障。256KB message size,16 threads,write IO , 观察链路故障发送后的IOPS指标。
测试结论:DPFF方案下链路故障对IOPS性能几乎没有影响,而OSPF协议收敛方案下IOPS出现多秒跌零情况。
利用Benchmarksql测试套件进行在线事务处理模型的测试,又称TPC-C测试。统计每百毫秒周期内完成的在线事务的数量,通过查看该数量值的变化测试收敛性能对业务性能的影响。模拟链路故障,重复测试4次, 观察在线交易事务受影响情况。
测试结论:DPFF收敛方案比传统的OSPF收敛方案在链路故障下,每100ms周期内完成交易事务数量下降减少60%~80%。
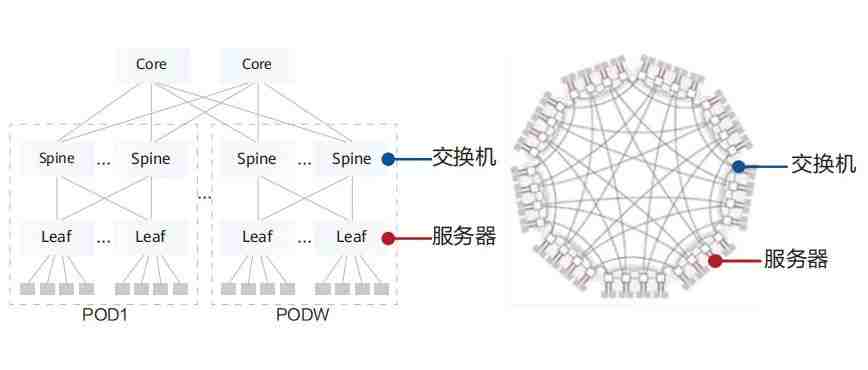
计算集群网络传统采用CLOS架构,以业界常见的64口盒式交换机为例,3级CLOS架构,最大可支持6.5万服务器接口,不满足10E级计算集群规模诉求。如果增加网络层数则会带来网络跳数增加,通信时延不满足业务需求。
业界针对该问题开展了多样的架构研究和新拓扑的设计。直连拓扑在超大规模组网场景下,因为网络直径短,具备低成本、端到端通信跳数少的特点。以64口盒式交换机构建10万个节点超大规模集群为例,传统的CLOS架构需要部署4层组网,端到端通信最大需要跨7跳交换机。使用无阻塞直连拓扑组网,端到端交换机转发跳数最少只3跳,交换机台数(整体投资)下降40%。
采用12台GPU服务器,每台服务器2块GPU卡,型号Tesla v100s;2块CX6-Dx网卡,网卡是100G单端口接入。OSU MPI Benchmark测试AllReduce集合通信操作,DF相对FT组网,任务完成时间最高提升39.47%,总体提升21.63%。
OSU MPI Benchmark测试Alltoall集合通信操作, DF相对FT组网,任务完成时间最高提升56.53%,总体提升49.71%。
随着高性能网络的全以太化发展,超融合以太网络同时承载计算、存储、管理和虚拟化等多种业务流量。为了追求更极致的性能,不同业务流量之间,极易出现互相干扰现象,竞争网络侧有限的端口转发资源。
为了解决这个难题,提出超融合智能无损网络方案,将业务级SLA智能保障技术引入到交换机中,用iLoss-less智能无损算法代替专家经验,对网络流量的变化进行基于队列级捕获和预测,实现细粒度动态差异化优化。结合不同业务的流量变化情况以及业务特征,实现不同业务流量差异化动态优化保障。
根据实验室测试,采用3台华为交换机组成2级Spine-Leaf组网,每台接入层交换机下挂16台100GE服务器,Spine与每个Leaf之间采用4个400G互联(1:1收敛)。在计算和存储benchmark流量混跑的测试环境下,智能无损算法相比于传统算法配置,在保持存储持平前提下,能够有效降低计算任务的总体完成时间,在测试场景中实现最高20%以上的计算时延降低。
下载链接:
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
2、随着电子书数量增加及内容更新,价格会随之增加,所以现在下单最划算,购买后续可享全店内容更新“免费”赠阅。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。