【干货】python正则表达式应用笔记

回老家了,继续更新。今天重新看了看文本清洗的代码,发现有一个正则表达式木有看懂,应该是之前学过的现在也印象太模糊了,就网上搜索,最终找到了一个干货----莫烦 python正则表达式讲解视频。如下
正则表达式 (Regular Expression) 又称 RegEx, 是用来匹配字符的一种工具. 在一大串字符中寻找你需要的内容. 它常被用在很多方面, 比如网页爬虫, 文稿整理, 数据筛选等等. 最简单的一个例子, 比如我需要爬取网页中每一页的标题. 而网页中的标题常常是这种形式.
<title>我是标题</ title> 而且每个网页的标题各不相同, 我就能使用正则表达式, 用一种简单的匹配方法, 一次性选取出成千上万网页的标题信息. 正则表达式绝对不是一天就能学会和记住的, 因为表达式里面的内容非常多, 强烈建议, 现在这个阶段, 你只需要了解正则里都有些什么, 不用记住, 等到你真正需要用到它的时候, 再反过头来, 好好琢磨琢磨, 那个时候才是你需要训练自己记住这些表达式的时候.
简单匹配
正则表达式无非就是在做这么一件事。在文字中找到特定的内容。我们在“dog runs to cat” 这句话中寻找存在“cat” 或者 “bird” 。
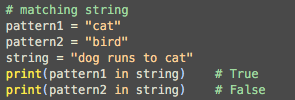
但是正则表达式绝非不止这些简单的匹配,它还能做更加高级的内容。要使用正则表达式,首先需要调用一个python的内置模块
re 。然后我们重复上面的步骤,不过这次使用正则。可以看出,如果
re.search() 找到了结果,它会返回一个
match 的 object 。如果没有匹配到,它会返回
None 。这个re.search() 只是 re 中的一个功能,之后会介绍其他功能。

灵活匹配
除了上面的简单匹配,下面的内容才是正则的核心内容,使用特殊的
pattern 来灵活匹配需要找的文字。
如果需要找到潜在的多个可能性文字,我们可以使用
[ ] 将可能的字符囊括进来。比如 [ ab ]就说明我想要找的字符可以是 a 也可以是 b 。这里我们还需要注意的是,建立一个正则的规则,我们在 pattern 的 ""
前面需要加上一个 r 用来表示这是正则表达式,而不是普通字符串。通过下面这种形式,如果字符串中出现 "run" 或者 "ran" , 它都能找到 。

同样,中括号 [ ] 中还可以是一下这些或者是这些的组合。比如
[ A-Z ] 表示的就是所有大写的英文字母。
[ 0-9a-z ] 表示可以是数字也可以使任何小写字母。


按类型匹配
除了自己定义的规则,还有很多匹配的规则时提前就给我们定义好了的。下面有一些
特殊的匹配类型给大家总结一下,然后再上一些例子。
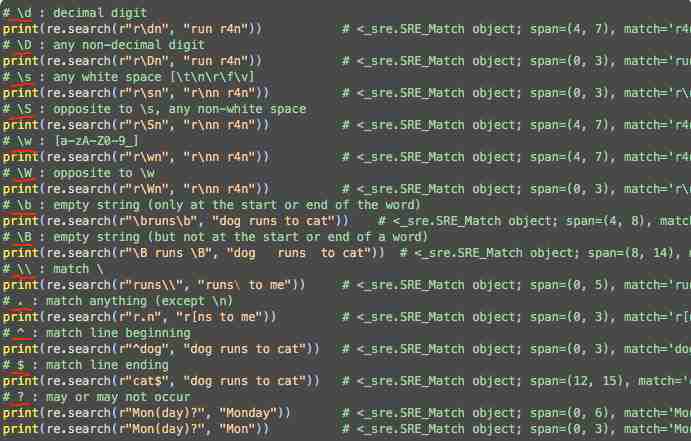
- \d : 任何数字
- \D : 不是数字
- \s : 任何 white space, 如 [\t\n\r\f\v]
- \S : 不是 white space
- \w : 任何大小写字母, 数字和 “” [a-zA-Z0-9]
- \W : 不是 \w
- \b : 空白字符 (只在某个字的开头或结尾)
- \B : 空白字符 (不在某个字的开头或结尾)
- \\ : 匹配 \
- . : 匹配任何字符 (除了 \n)
- ^ : 匹配开头
- $ : 匹配结尾
- ? : 前面的字符可有可无
下面就是具体的举例说明。
如果一个字符串有
很多行,我们想使用 ^ 形式来匹配行开头的字符,如果通常的形式是不成功的。比如下面的 " | " 出现在第二行,这时候,我们要使用另一个参数,让 re.search() 可以对每一个单独处理。这个参数就是
flags = re.M ,或者这样写也行
flags.re.MULTILINE 。


重复匹配
如果我们想让某个规律被重复使用,在正则里面也是可以实现的,而且实现的方式还有很多。具体可以分为这三种:
*: 重复零次或多次+: 重复一次或多次{n, m}: 重复 n 至 m 次{n}: 重复 n 次
举例如下:

分组
我们甚至可以为找到的内容分组,使用 ( ) 能轻松实现这件事。通过分组,我们能轻松定位所找到的内容。比如这个 ( \d+ ) 组里,需要找到的是一些数字,在 ( .+ ) 这个组里,我们会找到 " Date: "后面的所有内容。当使用 match.group( ) 时,它会返回所有组里的内容,而如果给 .group(2) 里加了一个数,它就能定位你需要返回哪个组里的信息。

有时候,组会很多,光用数字可能比较难找到自己想要的组,这时候,如果有一个名字当索引,会是一件很容易的事。我们需要在括号的开头写上这样的形式 ?P<名字> 就给这个组定义一个名字。然后就能用这个名字找到这个组的内容。

findall
前面我们说的都是只找到最开始匹配上的一项而已,如果需要找到全部的匹配项,我们可以使用 findall 功能。然后返回一个列表。注意下面还有一个新的知识点, | 是 or 的意思,要不是前者要不是后者。

replace
我们还能通过正则表达式匹配上一些形式的字符串然后再替换掉这些字符串。使用这种匹配 re.sub( ) ,将比python自带的string.replace( ) 要灵活的多。

split
再来我们python中有个字符串的分割功能,是split,比如" a is b".split(" "),这样它就会产生一个列表来保存所有单词。但是在正则中,这种普通的分割也可以做的淋漓尽致。

compile
最后我们还能使用 compile 过后的正则,来对这个正则重复使用。先将正则 compile 进一个变量,比如 compiled_re ,然后直接使用这个 compiled_re 来搜索。

小抄

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。