神经网络基础模型--Logistic Regression的理论和实践

1
概述
Logistic Regression 即 逻辑回归,属于监督学习,输入x(特征数据),输出为0或1(显然是二分类)。为什么要用逻辑回归讲神经网络基础呢?我觉得这个相对比较简单,易懂,而且有神经网络基本都会用到的激活函数(Activation Function)。
正向传播,搭建神经网络
1
比如我们要给二维平面的点做分类,则输入的是特征有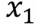 ,
, (即点的x,y坐标)。参数我们设置三个(一个特征配一个参数,再加一个biase),这里我设为
(即点的x,y坐标)。参数我们设置三个(一个特征配一个参数,再加一个biase),这里我设为
 ,在加上一个biase
,在加上一个biase  。这样我们就得到了一个函数值:
。这样我们就得到了一个函数值:
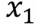





我们设置值为z,则此时我们已经对原始数据进行了第一次处理,也就是得到我们第一个神经元
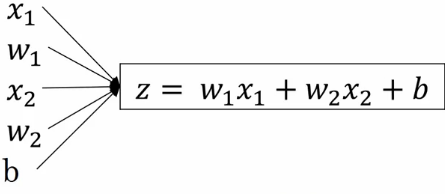
(注:我们也可以把参数放到的对应线上)
2
可是我们目的是为了分类0或1,也就是输出的结果起码得在0-1之间。可是我们根本不知道z的值有多大,也就无法控制范围,所以我们用一个函数来完美起到可以把结果限制到0-1范围内,这个函数是长这个样子 ,我们对它做个测验(->趋近于):
,我们对它做个测验(->趋近于):

当x->正无穷,值->1;
当x->负无穷时,值->0;
当x=0时,值=1/2。
大概图像长这个样子:
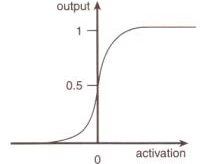
像这样将结果做一次函数特殊处理的,我们称之为Activation Function,记这个函数为sigmod。
因为接下来要用到它的导数,这里我推导下它的求导过程,以后记住结果就行:
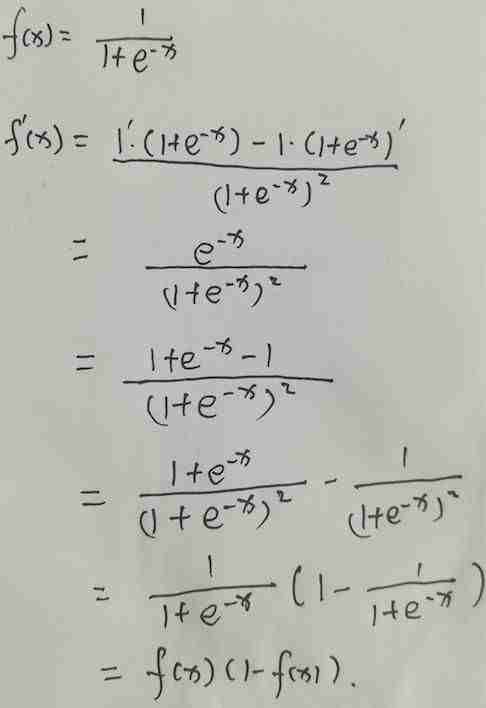
这次我们
第二次对数据做了处理,就可以再添加一个
神经元了:
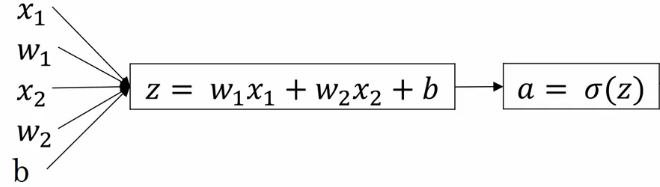
其中 这里表示sigmod,a表示它的值。
这里表示sigmod,a表示它的值。

3
结果我们已经计算出来了,是a,那么我们怎样才能更新我们的参数呢?当然是赶紧找到
损失函数啦。
我们先回顾下我们之前所用过的最简单的损失函数 (
( 预测值,y为真实值)。可是这种损失函数在参数w大于1个的时候,就很有可能出现多个极值点(比如它的函数这个样子
预测值,y为真实值)。可是这种损失函数在参数w大于1个的时候,就很有可能出现多个极值点(比如它的函数这个样子 ),而导致梯度下降法无法得到最优解。
),而导致梯度下降法无法得到最优解。



逻辑回归损失函数是这样的 。
。

if y=1,则 ,想要越大,则就要
,想要越大,则就要 越小。
越小。


if y=0,则 ,想要越小,则就要越小。
,想要越小,则就要越小。

综上所述,要想使精确地靠近y,仅仅使达到最小即可。
这次就是我们的第三次也是最后一次处理数据了,所以又添加了一个损失函数神经元:

(其中的a就是上面的)
上面的整个数据传送过程,我们称之为正向传播。
反向传播,更新参数
要想通过损失函数L对进行更新,就得求L的上的梯度,怎么求梯度呢?很显然,链式求导呀。
我推导了下:

(上图我标出的

是因为如果下面的代码dz没看懂的话瞅瞅这个)
然后我们对参数进行更新:
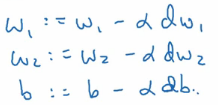
(alpha为学习率)
这个过程就是
反向传播。
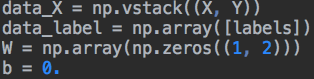
代码实现
初始化数据点,绿点为1类,红点为0类。

图像显示:

规范数据(缩小到-1 — 1,不清楚原因的可以看前面的梯度下降算法的相关说明)

图为:


初始成的数据:

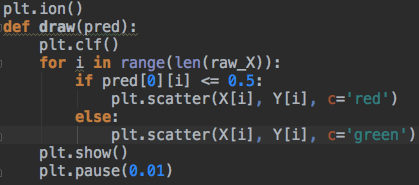
上面讲的很详细了,应该能看懂

第一个图:

第二张图:

后面的一张图:
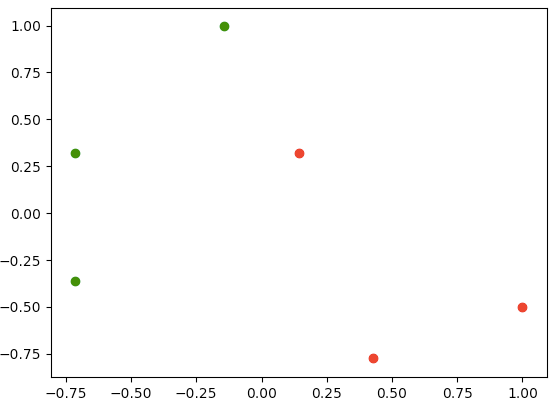
成功

损失函数图:

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。