pytorch自然语言处理之Pooling层的句子分类


Pooling作为最简单的层其实也可以作为句子分类任务。Pooling有很多种,max_Pooling,avg_Pooling,min_Pooling等。常用的还是max_Pooling:取同维度的最大值。
先看看
流程图:

这里的Linear Layer后面应该经过一个Softmax的,可是由于交叉熵cross_entropy里隐含有Softmax,这里我就没有画了。
第一步搭建网络

这里除了划线的和类的名字外,其他都是pytorch固定模板。__init__就是搭建网络的函数,forward是数据怎么在你刚搭建的网络中流动的写出来就行,注意数据矩阵的维数,要前后对上。该维度可以用view(),t(),transport()按照想法进行改变。我在这个维度上浪费了很长时间,就是对不上。慢慢理解了,就会了。
这里的Embeding层就是把现实客观特征转成电脑识别的特征,也就是特征向量化。
第二步读入数据并将数据数字化
数据是这个样子:

前面文本后面类别
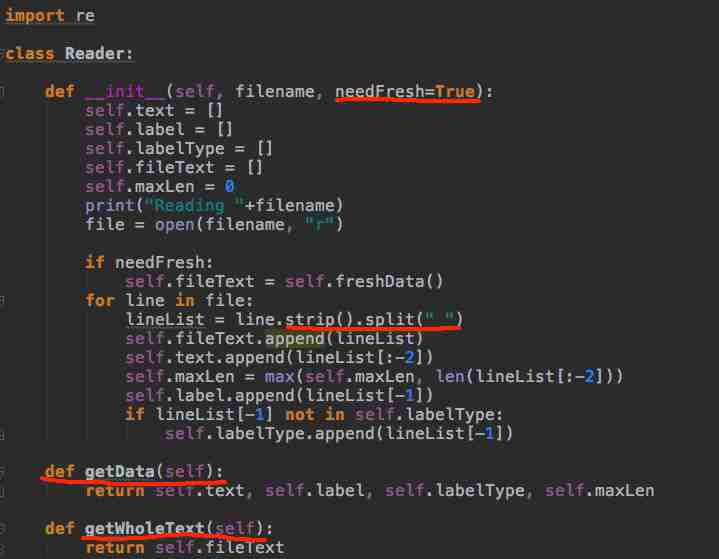
读取文本的类
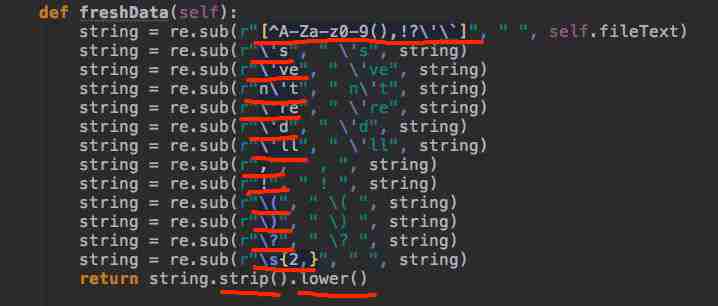
清洗英文文本的函数,这个写过一次后,下次清洗文本直接复制直接用。
文本读取完后,建立词典,为只有数字序列化做准备。函数如下:
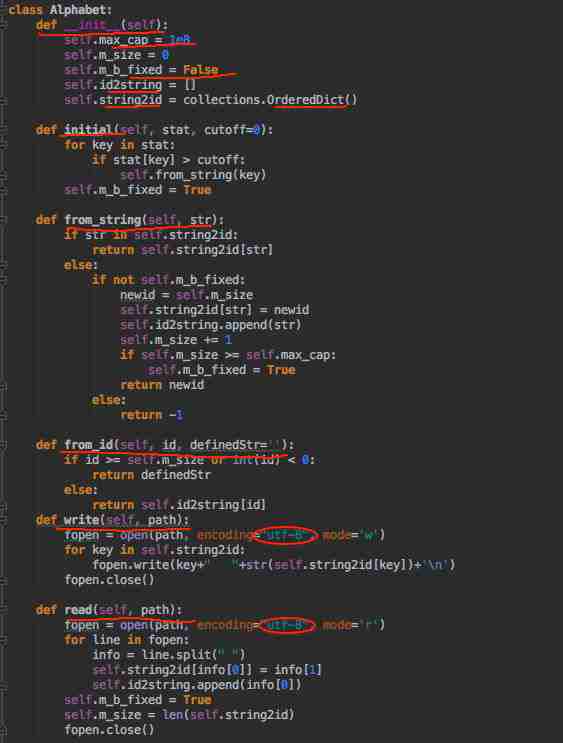
字典为:

然后通过函数调用就能生成数字序列:

第三步开始训练

因为用SGD很多时候不能够收敛。。。特别悲催。所以推荐用Adam优化。


这是计算精确度的函数,在一遍跑好的模型上走一遍Dev数据,得出开发集准确率。torch和numpy交换就用 .numpy()。
最后得出结果:
这个贼耗时间



精确度慢慢增长。。。
在此,非常感谢刘宗林师兄的技术支持。

点击阅读原文,获得源代码
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。