深度学习之卷积神经网络CNN理论与实践详解
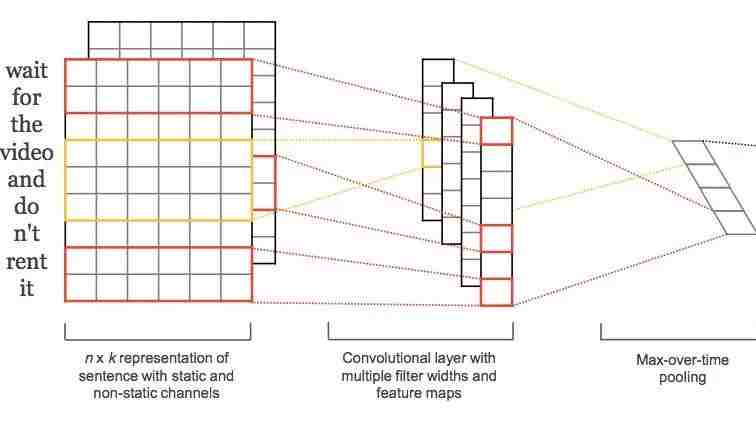
概括
大体上简单的卷积神经网络是下面这个网络流程:
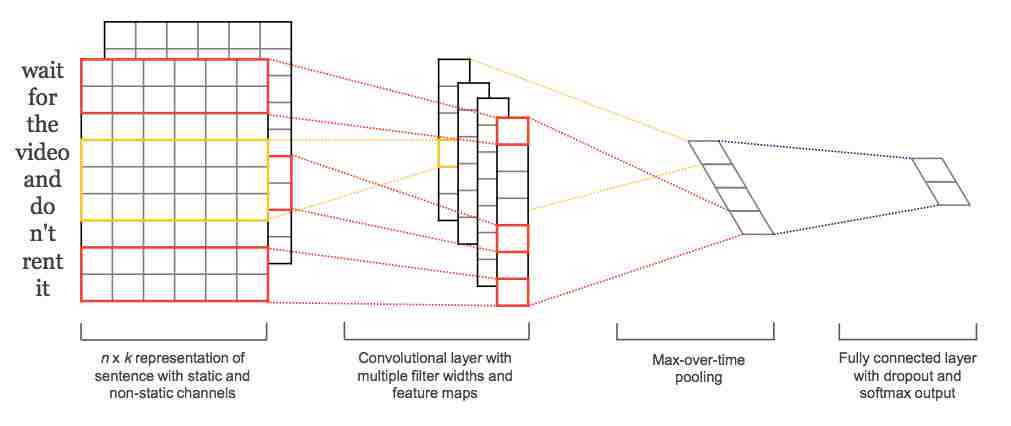
笼统的说:
文本通过Embeding Layer 后,再通过一些filters进行过滤,对结果进行maxPooling,再经过线性层映射到类别上,最后经过Softmax,得出类别分数。
细致的说:
就得慢慢分析了,as follows:
第一层:将Embeding进行filter
设 Embeding大小为:EmbedSize
边解释专有名词边讲述过程:
Channel: 每个单词的向量是上图的对应的行。这里的一个句子形成一个二维矩阵,这里二维矩阵叫做 一个channel。
Filter:过滤器,有时候也叫做kernel。图片处理的filter大小可以根据情况选择不同的正方形的filter;而自然语言处理中,每行表示一个特征,不能分离,所以这里的filter的长为EmbedSize,而宽呢?一般设置为奇数3,4,5(这些都是经验值,当然可以设置成别的值,但是不推荐。宽为偶数的特别少见,一般不用)。这里的Filter在和计算的时候,是和Embeding矩阵对应位相乘,最后相加,得出一个结果,公式为y = W*X + b(有没有b,自己决定)最后随着滑动,得到一个新的矩阵。
Strides: 步长。也就是滑动的距离。无论向右滑动还是向下滑动都是这个大小。(因为这里的Filter长为EmbedSize,所以,这里只能向下滑动)
Filter后的输出矩阵大小为:(n-f+1)/s+1 * 1 其中n为句子的长度,f为Filter的宽,s为Stride。可以看出,不同的Filter对应的输出矩阵大小是不一样的。所以,提出Padding。
Padding:四周填充0。它的用途有两个:1.解决输出大小不一致的问题。2.解决信息丢失的问题(主要是角上的信息)。
所以这时候的矩阵输出为:(n-f+2p+1)/s+1 * 1(p为pooling大小), 一般默认s为1,所以为了使输出的矩阵高为n,则
n-f+2p+1 = n
即:
p = (f-1)/2 (f为一般为奇数,所以p = (f-1)//2)
这里在pytorch里的网络层代码:

最后的矩阵记得要经过一个激活函数。
数据流动:
第二层 maxPooling最大池化
有时候这个也说不算是一个层,因为不含参数。
将第一层得到的m个二维矩阵,进行maxPooling,最终变成m*1的矩阵。(m为相同Filter的个数*Filter种类)
数据流动代码:
第三层 Fully Connected Layer全连接层
将上面的m*1维的数据进过一个线性层,映射到k*1上。(k是种类个数)
再进行Softmax,得到最终分类。
这里在pytorch里的网络层代码:

数据流动代码:
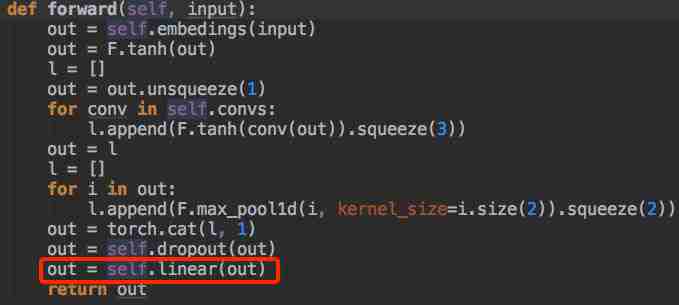
注:代码里没有Softmax,是因为之后用到的Loss函数里默认有。
ok,这里就讲完了。最近在想CNN好想不太适合做立场检测,觉得LSTM应该更为合适,接下来系统理论的学习下LSTM网络。
欢迎关注深度学习自然语言处理公众号

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。