Machine Learning -- ID3算法

今天,我来讲解的是决策树。对于决策树来说,主要有两种算法:ID3算法和C4.5算法。C4.5算法是对ID3算法的改进。今天主要先讲ID3算法,之后会讲C4.5算法和随机森林等。
Contents
1. 决策树的基本认识
2. ID3算法介绍
3. 信息熵与信息增益
4. ID3算法的C++实现
1. 决策树的基本认识
决策树是一种依托决策而建立起来的一种树。在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象,树中的每一个分叉路径代表某个可能的属性值,而每一个叶子节点则对应从根节点到该叶子节点所经历的路径所表示的对象的值。决策树仅有单一输出,如果有多个输出,可以分别建立独立的决策树以处理不同的输出。接下来讲解ID3算法。
2. ID3算法介绍
ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事。ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法。
在信息论中,期望信息越小,那么信息增益就越大,从而纯度就越高。ID3算法的核心思想就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。该算法采用自顶向下的贪婪搜索遍历可能的决策空间。
3. 信息熵与信息增益
在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。在认识信息增益之前,先来看看信息熵的定义
熵这个概念最早起源于物理学,在物理学中是用来度量一个热力学系统的无序程度,而在信息学里面,熵是对不确定性的度量。在1948年,香农引入了信息熵,将其定义为离散随机事件出现的概率,一个系统越是有序,信息熵就越低,反之一个系统越是混乱,它的信息熵就越高。所以信息熵可以被认为是系统有序化程度的一个度量。
假如一个随机变量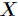 的取值为
的取值为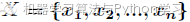 ,每一种取到的概率分别是
,每一种取到的概率分别是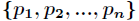 ,那么的熵定义为
,那么的熵定义为
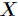
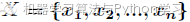
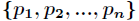

意思是一个变量的变化情况可能越多,那么它携带的信息量就越大。
对于分类系统来说,类别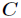 是变量,它的取值是
是变量,它的取值是 ,而每一个类别出现的概率分别是
,而每一个类别出现的概率分别是
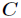

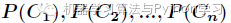
而这里的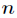 就是类别的总数,此时分类系统的熵就可以表示为
就是类别的总数,此时分类系统的熵就可以表示为
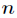

以上就是信息熵的定义,接下来介绍信息增益。
信息增益是针对一个一个特征而言的,就是看一个特征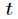 ,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。
,系统有它和没有它时的信息量各是多少,两者的差值就是这个特征给系统带来的信息量,即信息增益。
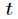
接下来以天气预报的例子来说明。下面是描述天气数据表,学习目标是play或者not play。

可以看出,一共14个样例,包括9个正例和5个负例。那么当前信息的熵计算如下
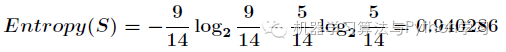
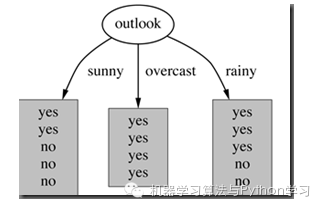
在决策树分类问题中,信息增益就是决策树在进行属性选择划分前和划分后信息的差值。假设利用属性Outlook来分类,那么如下图
划分后,数据被分为三部分了,那么各个分支的信息熵计算如下
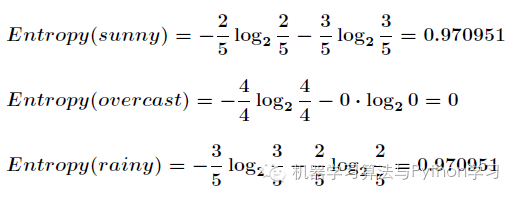
那么划分后的信息熵为
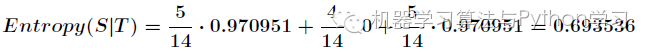
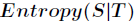
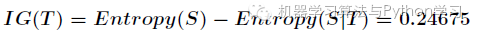
信息增益的计算公式如下
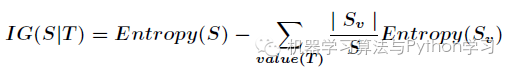
其中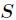 为全部样本集合,
为全部样本集合,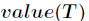 是属性
是属性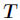 所有取值的集合,
所有取值的集合,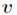 是的其中一个属性值,
是的其中一个属性值,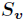 是中属性的值为的样例集合,
是中属性的值为的样例集合,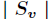 为中所含样例数。
为中所含样例数。
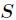
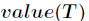
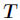
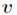
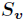
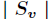
在决策树的每一个非叶子结点划分之前,先计算每一个属性所带来的信息增益,选择最大信息增益的属性来划分,因为信息增益越大,区分样本的能力就越强,越具有代表性,很显然这是一种自顶向下的贪心策略。以上就是ID3算法的核心思想。
生活中程序猿的真实写照、一款游戏一包烟,一台电脑一下午。一盒泡面一壶水,一顿能管一整天。

谢谢您的支持与关注
欢迎转载
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。