模糊最小二乘支持向量机

引言:
将模糊隶属度概念引入最小二乘支持向量机,提出一种基于支持向量数据域描述的模糊隶属度函数模型.将输入空间中的样本映射到一个高维的特征空间,然后根据其偏离数据域的程度赋予不同的隶属度.该方法提高了最小二乘支持向量机的抗噪声能力,尤其适用于未能完全揭示输入样本特性的情况.该模糊隶属度函数模型能够提高最小二乘支持向量机.
1995年Cortes和Vapnik 提出了以有限样本统计学习理论为基础的支持向量机(SVM),通过一个二次规划求取样本的最优分类面. 由于SVM坚实的理论基础, 良好的泛化性能 ,并能有效地解决非线性, 过学习, 局部极值等一系列难题, 使其受到广泛关注. 近年来 ,Suhkens提出一种新的 方法SVM------- 最小二乘支持向量机(LS-SVM) 方法.LS-SVM 是标准SVM的一种扩展 与传统的SVM 不同,LS-SVM求解线性方程组 极大减少了SVM 中由于求解二次规划问题带来的计算复杂性, 而且LS-SVM的数值稳定性和容量控制的策略, 使得核函数矩阵在非正定的情况下也能取得良好的效果.
与SVM相比,LS-SVM虽然具有更加快速的训练速度,但不能保证解的全局最优.而且其训练精度有所下降. 现在将模糊隶属度概念引入LS-SVR中, 提出一种基于支持向量数据域描述(SVDD)的模糊隶属度函数模型. 根据样本偏离数据域的程度赋予不同的隶属度. 该方法提高了LS-SVM 的抗噪声能力, 尤其适合于未能完全揭示输入样本特性的情况.
1,模糊最小二乘支持向量机
给定训练样本集
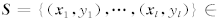
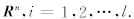
.在非线性情况下引入变换
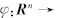
H.将样本从输入空间Rn映射到一个高维的希尔伯特特征空间H,输入空间中的函数估计可归纳为求解线面的二次规划:
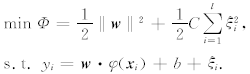
其中,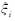 为松弛变量,C为惩罚因子.与传统的SVM相比,这一方法中二次规划约束条件为等式, 且损失函数为二次函数, 故称为最小二乘支持向量机. 引入Lagrange系数ai, 定义如下的Lagrange 函数:
为松弛变量,C为惩罚因子.与传统的SVM相比,这一方法中二次规划约束条件为等式, 且损失函数为二次函数, 故称为最小二乘支持向量机. 引入Lagrange系数ai, 定义如下的Lagrange 函数:
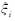
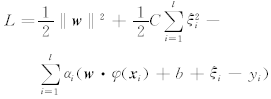
根据Mercer条件.存在映射
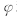
和核函数

使得
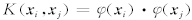
.令L对变量
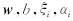
的偏导数为零,并将得到的等式带入到上式,可以得到矩阵方程:
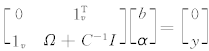
其中:

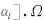
中的元素为
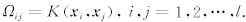
求解上述的矩阵方程,最后得到最小er二乘支持向量机的函数估计为:
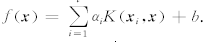
传统的SVM 中 只有一小部分a分量不为零( 支持向量), 而LS-SVM 中a 的每一个分量与样本的误差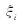 成正比 ,所以在LS-SVM 中没有支持向量的概念.LS-SVM 中常用的核函数
成正比 ,所以在LS-SVM 中没有支持向量的概念.LS-SVM 中常用的核函数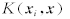 ,包括线性核
,包括线性核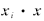 ,多项式核
,多项式核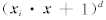 , 以及高斯径向基核
, 以及高斯径向基核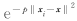 等.
等.
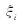
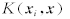
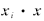
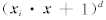
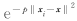
为解决SVM 对于孤立点过分敏感并由此而带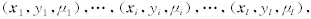
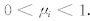
来的过拟合问题 .Lin等将模糊隶属度的概念引入SVM,模糊化输入样本集, 提出了模糊支持向量机(FSVM) 的概念, 将这一思想引入LS-SVM,为LS-SVM中每个样本引入模糊隶属度ui,模糊化输入样本集
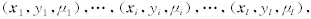
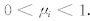
将最小二乘支持向量机的目标函数重写为:
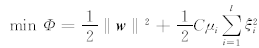
与LS-SVM函数估计方法一样,构造Lagrange函数,最后得到矩阵方程:
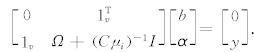
求解上述矩阵方程 即可得到模糊最小二乘支持向量机的估计函数. 与标准LS-SVM的矩阵方程相比 ,FLS-SVM的矩阵方程中多了模糊隶属度, 故这一方法被称为模糊最小二乘支持向量机(FLS-SVM).
2, 模糊隶属度
在分类问题中,Lin 等提出一种根据样本采集的先后顺序确定样本隶属度的模型, 该模型认为最近得到的样本相对要比其他的样本重要, 其隶属度也大, 但该模型缺乏理论上的依据. Huang提出一种基于孤立点检测的模糊隶属度模型, 他将样本集分为两部分, 一部分为孤立点集, 另一部分为主体集 .对于主体集中的样本 根据样本到其聚类中心的距离确定模糊隶属度, 而对于孤立点集中的样本其模糊隶属度则赋予一个很小的正数. 显然, Huang并没有区分孤立点集中的样本 ,仅简单地为每个孤立点赋予相同的模糊隶属度. 为了确定模糊隶属度函数的形式, 需要衡量一个样本偏离其所在类总体的程度. 本方法采用支持向量数据域描述方法, 将数据样本映射到一个高维的空间, 然后在这个高维空间中寻找其最小包含超球, 并根据样本到超球球心的距离确定其隶属度值。
2.1,支持向量数据域描述
支持向量数据域描述方法可描述为: 给定训练样本集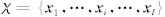 ,其中,
,其中,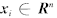 为输入空间, l 为样本个数. 为了建立样本的数据域描述模型, 需要寻找样本的最小包含超球.当输入空间中的样本为非球形分布时, 引入映射
为输入空间, l 为样本个数. 为了建立样本的数据域描述模型, 需要寻找样本的最小包含超球.当输入空间中的样本为非球形分布时, 引入映射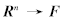 ,将输入空间中的样本映射到一个高维的特征空间F, 然后求解下面的二次规划:
,将输入空间中的样本映射到一个高维的特征空间F, 然后求解下面的二次规划:
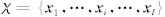
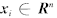
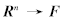
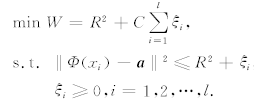
其中 :R为最小包含超球半径, a 为球心,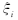 为松弛变量, C 为惩罚因子. 引入Lagrange系数
为松弛变量, C 为惩罚因子. 引入Lagrange系数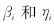 , 并进行对变换 最后得到Wolfe对偶为:
, 并进行对变换 最后得到Wolfe对偶为:
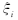
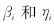
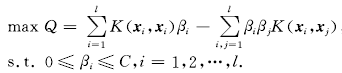
求解上述规划问题,即可得到最优的Lagrange系数及特征空间中的数据域描述.
2.2,基于数据域描述的模糊隶属度函数模型
输入空间中的点xi在特征空间中映射
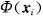
到最小包含超球球心a 的距离定义为
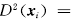
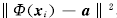
,考虑到

,有:
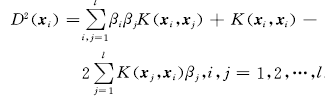
定义
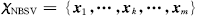
为输入空间中的自己,其中:xk为样本中非边界支持向量,m为非边界支持向量个数.特征空间中最小包含超球半径满足
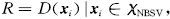
,当R和a确定后,便可得到给定数据集的数据域描述,定义:
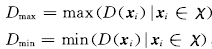
分别为样本到最小包含超球球心最大, 最小距离, 定义模糊隶属度函数如下:
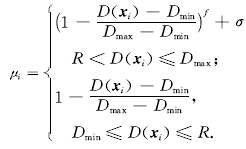
其中,

为足够小的正实数;f>=2,当f=2时,模糊隶属度函数ui随D(ui)变化曲线如下所示:

对于输入空间中的点xi, 其在特征空间中的映射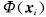 到最小包含超球球心a 的距离满足
到最小包含超球球心a 的距离满足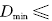
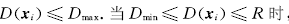 ,表示xi满足数据域描述,
,表示xi满足数据域描述,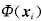 位于超球内或球面上, 其模糊隶属度随着 的增大而线性减少; 当
位于超球内或球面上, 其模糊隶属度随着 的增大而线性减少; 当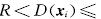
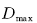 时, 样本xi偏离数据域描述, 也就是偏离其所在的类总体, 位于超球之外, 其模糊隶属度是
时, 样本xi偏离数据域描述, 也就是偏离其所在的类总体, 位于超球之外, 其模糊隶属度是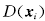 的二次函数,随着的增大,其模糊隶属度迅速减小.当接近于时,其隶属度已接近与一个非常小的正实数,这样可以减少这些离群点的影响。
的二次函数,随着的增大,其模糊隶属度迅速减小.当接近于时,其隶属度已接近与一个非常小的正实数,这样可以减少这些离群点的影响。
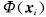
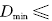
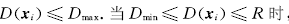
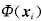
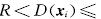
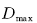
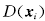
3,总结
将模糊隶属度概念引入LS-SVM中, 提出了一种基于支持向量数据域描述的模糊隶属度函数模型. 首先得到训练集中样本的数据域描述模型; 然后根据样本偏离数据域的程度赋予不同的隶属度.该方法提高了LS-SVM的抗噪声能力, 尤其适合于未能完全揭示输入样本特性的情况.

~欢迎推荐给你最好的朋友~
阅读原文 
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。