KNN算法实战——改进约会网站配对效果

kNN实战之改进约会网站配对效果

引言
简单的说,KNN算法采用测量不同特征值之间的距离方法进行分类。工作原理:存在一个样本数据集,即训练数据集,并且样本集中每个样本数据都存在标签,即我们知道样本数据集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,只选择样本数据集中前K个最相似的数据,这就是KNN算法中的k的出处,通常K是大于20的整数。最后,选择k个最相似的数据中出现次数最多的分类作为新数据的分类。
优点:精度高,对异常值不敏感,无数据输入假定
缺点:计算复杂度高,空间复杂度高
适用范围:数值型和标称型
今天我们将使用KNN算法改进约会网站的配对效果,首先先介绍一下该实战的背景。
背景介绍
美女二丫在在线约会网站寻找适合自己的约会对象时,尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。经过一番总结,她发现曾经交往过三种类型的人:
不喜欢的人
魅力一般的人
极具魅力的人
尽管发现上述的规律,但二丫依然不能将约会网站推荐匹配的对象归入恰当的分类。她可以在周一到周五月那些魅力一般的人,在周六周天约那些极具魅力的人。为此希望我们帮她设计一个可以将不同对象归入恰当的分类,为此,二丫还收提供了一些必要的信息。
算法流程
收集数据:提供文本文件
准备数据:使用python解析文本文件
分析数据:使用matplotlib画二维图
训练数据:
测试算法:使用二丫提供的部分数据作为测试集
部署算法:产生简单的命令行程序,然后二丫可以输入一些特征数据以判断对方是否为自己喜欢的类型。
数据保存在datingTestSet.txt中,每个样本数据占据一行,总共1000行,样本主要包含以下三个特征:
每年获得的飞行里程
玩游戏所消耗的时间百分比
每周消耗的冰激凌公斤数
将文本记录转换为Numpy的解析程序:
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
该函数作为kNN函数的子函数存放在kNN.py文件中,在python命令行输入一下命令:
>>> import sys
>>> sys.path.append('C:\Users\NEU\Desktop\JKXY\machinelearninginaction\Ch02')
>>> import os
>>> os.getcwd()
'C:\\Python26\\Lib\\idlelib'
>>> os.chdir('C:\Users\NEU\Desktop\JKXY\machinelearninginaction\Ch02')
>>> os.getcwd()
'C:\\Users\\NEU\\Desktop\\JKXY\\machinelearninginaction\\Ch02'
>>> import kNN
>>> datingDataMat, datintLabels = kNN.file2matrix("datingTestSet2.txt")


现在已经将文本文件导入到运行空间,并转化成所需要的格式了,接下来需要了解数据的具体含义。所以使用python工具来图像化展示数据内容,以辨识出一些数据模式。
首先使用matplotlib制作原始数据的散点图,在python命令行中输入一下命令:
>>> import matplotlib
>>> import matplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
<matplotlib.collections.CircleCollection object at 0x03C8A190>
>>> plt.show()
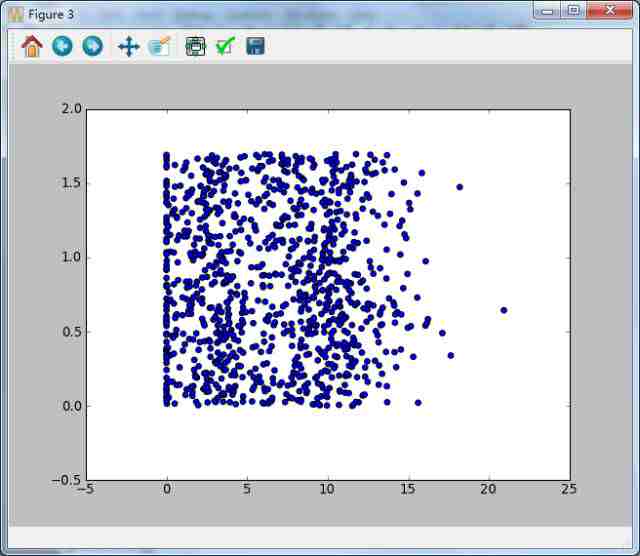
没有类别标签的约会数据散点图,难以辨识图中的点属于哪一类(“玩游戏所占时间百分比”和“每周消耗的冰激凌公斤数”)
datingDataMat的第二列和第三列分别表示特征值的“玩游戏所占时间百分比”和“每周消耗的冰激凌公斤数”,第一列为“每年的飞行里程数”。由于没有使用样本分类的特征值,上图我们不能得到任何有用的数据模式信息。
在python命令行重新输入以下命令:
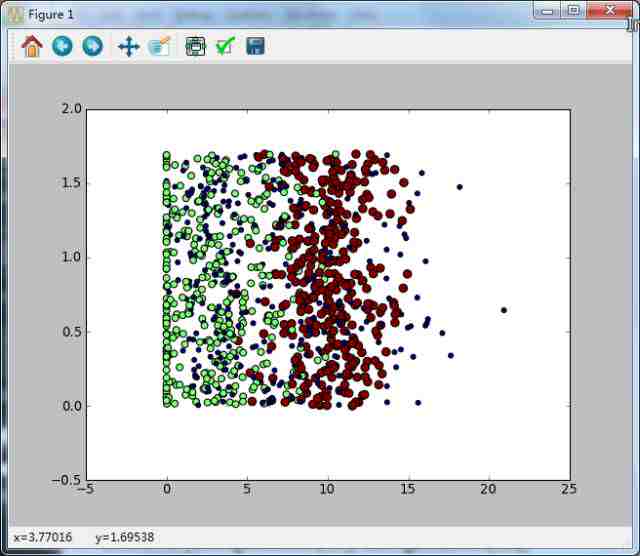
带有分类标签的约会数据散点图,虽然能够比较容易的区分数据点属于哪一类,但依然难以根据这张表得出结论性的信息(“玩游戏所占时间百分比”和“每周消耗的冰激凌公斤数”)
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。