机器学习(2) -- logistic regression
本篇内容对应机器学习课程的第二次视频~~~~~~~
大纲:
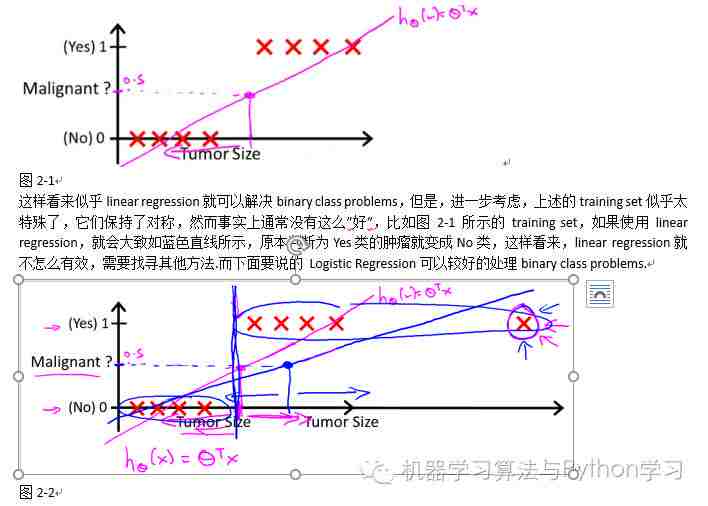
2 Logistic Regression.
2.1 Classification.
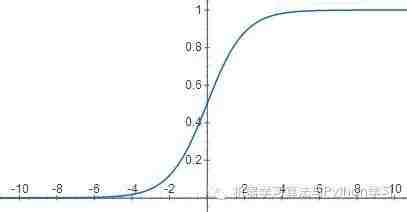
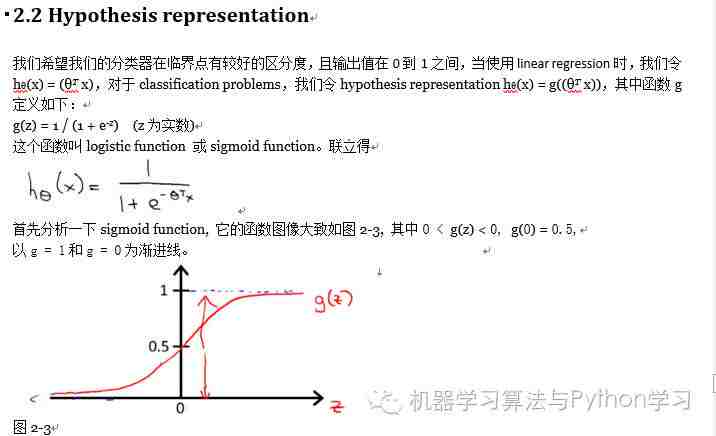
2.2 Hypothesis representation.
2.2.1 Interpreting hypothesis output.
2.3 Decision boundary.
2.3.1 Non-linear decision boundaries.
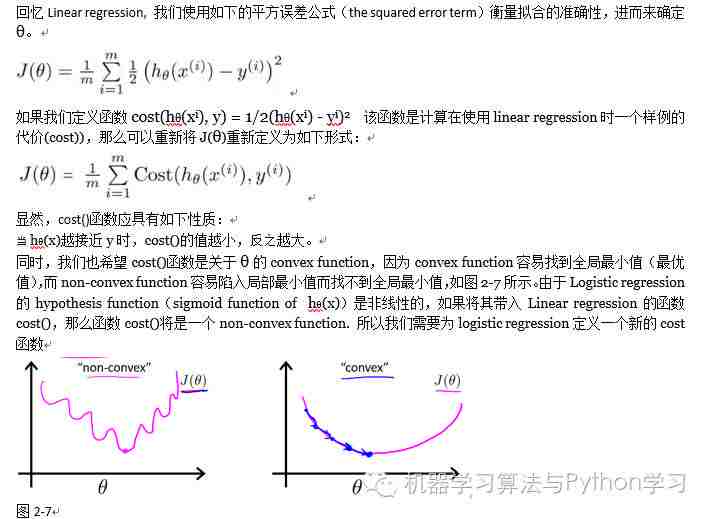
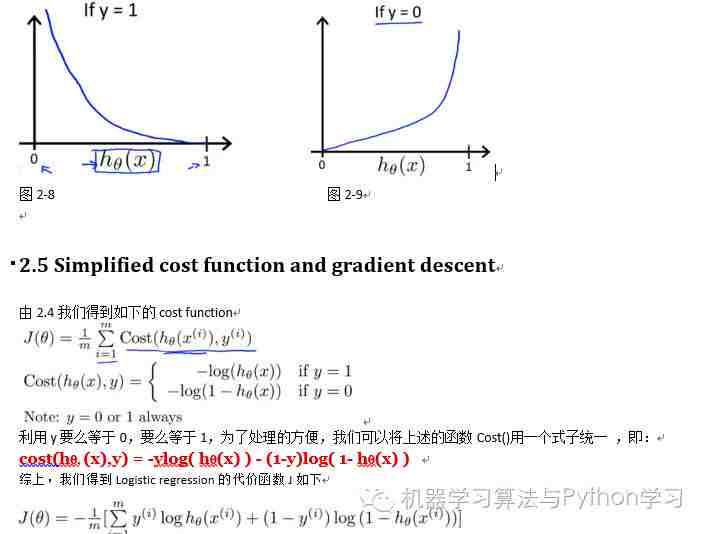
2.4 Cost function for logistic regression.
2.4.1 A convex logistic regression cost function.
2.5 Simplified cost function and gradient descent.
2.5.1 Probabilistic interpretation for cost function.
2.5.2 Gradient Descent for logistic regression.
2.6 Multiclass classification problem
key words: logistic regression, classification, decision boundary, convex function, One-vs-all








2.6 Multiclass classification problem
现实中也常遇到多分类问题(multiclass classification problem),如判断手写的数字是0~9中的哪一个就是一个有10类的问题。多分类学习的基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。具体来说,先对问题进行拆分,然后为拆分出的每个二分类任务训练一个分类器(也就是h(x));在预测时,对这些分类器的预测结果进行集成。
下面介绍一个常用的拆分策略-“One-vs-all”.
One-vs-all每次将一个类的样例作为正例(“1”),所有其他类作为反例(“0”)来训练n个分类器。在预测时,有两种情况看:
- 情况1:若仅有一个分类器预测为正例,则对应的类别标记作为最终分类结果;
- 情况2:若有多个分类器预测为正例,则选择分类器的预测置信度最大的类别标记为分类结果。
例如对于图2-10所示的多分类问题,我们先将三角形,正方形,叉分别标记为类别1,2,3,然后做如下划分:
- 先将三角形看作正例“1”,正方形和叉看作反例“0”,训练出hθ1(x)
- 再将正方形看作正例“1”,三角形和叉看作反例“0”,训练出hθ2(x)
- 最后将叉看作正例“1”,三角形和正方形看作反例“0”,训练出hθ3(x)
预测时每一个预测值都是一个形如[hθ1(x), hθ2(x), hθ3(x)]的向量。选出最大的h(x),它的上标就是对应的类别标记。例如若预测值为[0.13, 0.24, 0.79],对应的就是上文所说的情况1,即只有hθ3(x) > 0.5表现为正例,所以应该认为是属于3标记类,即为叉。若预测值为[0.12, 0.83, 0.56], 对应的就是上文所说的情况2,hθ2(x) 和hθ3(x)都大于0.5,都预测为正例,但hθ2(x)> hθ3(x),所以应该预测是属于2标记类,即为正方形。

图2-10

谢谢支持与关注
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。