利用 AI 合成假视频,川普竟能宣布「美国与加拿大合并」? | 潮科技


你有没有想过AI其实还可以用来伪造图片、音频乃至视频呢?今天介绍的黑科技既可以用来进行朋友间的轻松恶搞互黑,也有可能被别有用心的人拿来进行诬蔑诈骗。
文 | 田煦阳
编辑 | 傅博
千万不要以为人工智能的应用场景,只有无人驾驶,击败全人类最优秀的棋手,辅助甚至主导医疗行业等等严肃而高大上的方面。
你有没有想过AI其实还可以用来伪造图片、音频乃至视频呢?本项黑科技既可以用来进行朋友间的轻松恶搞互黑,也有可能被别有用心的人拿来进行诬蔑诈骗。
以PS为代表的美图工具已经让我们意识到了“照骗”的存在,而有了这项“嫁接”声音和嘴型的技术,我们已经可以选择对一切都持有怀疑态度了。
这项AI在音频视觉领域的魔幻黑科技来自于美国的华盛顿大学(University of Washington,其坐落于美丽的西雅图,微软、fb、亚马逊的总部均位于此)。此项目背后的资助者名单云集了各家大腕——三星,谷歌,Facebook以及Intel。其应用到的技术原理并不难理解。
科学家们先是创造了大规模处理音频文件的工具,紧接着是整个流程内最为关键的一步——创造出真实的口型变化以对应音频内容,达到以假乱真的效果。最后的一步反倒相应简单,只要将这些伪造出的口型变化安排给其他视频中无辜的被恶搞者即可。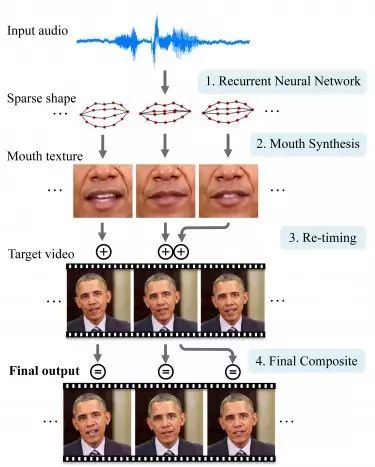

具体的技术流程展示
通过结合华盛顿大学图像实验室(UW Graphics and Image Laboratory)之前研发的新式嘴型合成技术,项目组成员终于可以将嘴型及其纹理移植到现存视频中的人脸上。
由此,我们便能看到说话者一本正经地说出他们连想都没有想过的事情的奇葩场景。
比如说,川普一本正经地宣布“美国和加拿大从明年1月1日起将合并为一个国家”,亦或是巴基斯坦总理纳瓦兹·谢里夫宣布巴基斯坦全境将并入中华人民共和国管辖。
在视频中,左面图画应用到的声源的原视频,而右面的视频则来自于完全不同的演讲(由于视频中含有奥巴马,上传国内网站没过审,大家凑合看)。
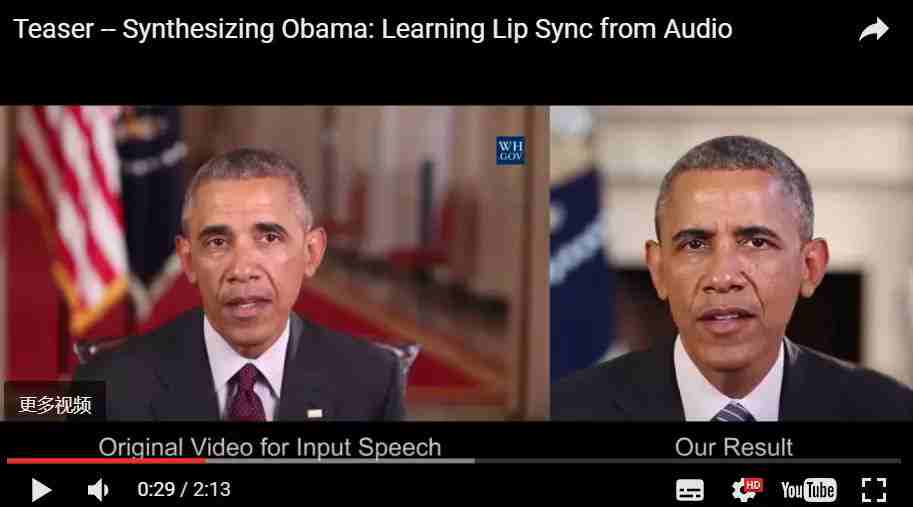
研究人员通过算法,成功地把左面中的嘴型移植到了右面的人相中,虽然效果不甚完美(如果细心的话,你可以发现奥巴马的嘴部有一些模糊,这是利用AI产生的图像的通病),但总体上已经足可以让不明真相的吃瓜群众信以为真。
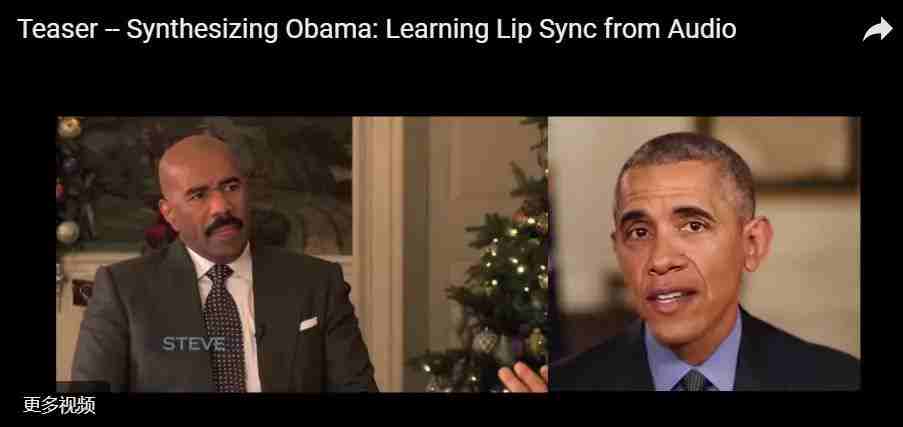
为什么研究人员会选用奥巴马来当做实验品呢?他们给出的理由是这样的,由于前总统出众的曝光度,其高质量的演讲视频数量庞大,十分容易获得,使训练神经网络的过程变得轻松起来。
项目中的一位研究人员Ira Kemelmacher教授通过邮件告诉The Verge,目前他们若想达到视频中展现的较为完美的嘴型“移植”,需要足足十七个小时长的视频作为数据来让机器解析、学习。不过在未来技术成熟后,这一过程耗费的时长将大大缩短。
当然,开发该技术的团队希望能扩展其应用场景,比如说用来提升视频聊天软件如Skype的使用体验。
用户们可以自行收集自身讲话时的画面,并将其利用到软件的训练之中,意图解决目前视频通话中声音信号传输良好,图片却模糊得一团糟的情况。若一切发展顺利的话,理想状况是用户完全可以关掉视频画面,软件会自动把语音转化为相应的画面发送给另一端的用户。这将在网络连接糟糕或者是用户想节省手机流量的情境下大显神威。
当然,从出生那一天起,这项技术的伦理道德问题和社会影响会一直处在舆论的漩涡之中。单单该项技术带来的破坏力就已经令人无法忽视,如果再搭配上仅需几分钟音频就能伪造任何人声音的黑科技,不法分子完全可以制作出以假乱真的视频引发骚动或是进行诈骗活动。与此原理类似的其他技术还有改变他人表情,通过寥寥几张图片制作3D人脸模型等等。
华盛顿大学的研究人员也意识到了这一点,生成他们在训练中只使用了奥巴马的声音和视频,尽量与上文提到的灰色应用场景保持距离。
但是在原理上,只要能掌握技巧熟练应用这一黑科技组合,我们可以将任何人的声音移植到任何人的脸上,创造出各种意想不到,以假乱真的视频。
本项技术的具体细节将会在今年8月2号举行的全球最具影响力图像技术盛会SIGGRAPH 2017上以论文的形式披露出来。
(部分信息来源: The Verge)

点击关键词,查看过去两周的潮科技:
消费:「科学剁手」
感情:「VR恋爱设备」
影视:「裸眼3D阿凡达」

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。