机器学习(33)之局部线性嵌入(LLE)【降维】总结
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
前言
局部线性嵌入(Locally Linear Embedding,简称LLE)也是非常重要的降维方法。和传统的PCA,LDA等关注样本方差的降维方法相比,LLE关注于降维时保持样本局部的线性特征,由于LLE在降维时保持了样本的局部特征,它广泛的用于图像图像识别,高维数据可视化等领域。
什么是流形学习
LLE属于流形学习(Manifold Learning)的一种。因此我们首先看看什么是流形学习。流形学习是一大类基于流形的框架。数学意义上的流形比较抽象,不过可以认为LLE中的流形是一个不闭合的曲面。这个流形曲面有数据分布比较均匀,且比较稠密的特征,有点像流水的味道。基于流行的降维算法就是将流形从高维到低维的降维过程,在降维的过程中我们希望流形在高维的一些特征可以得到保留。
一个形象的流形降维过程如下图。有一块卷起来的布,希望将其展开到一个二维平面,同时也希望展开后的布能够在局部保持布结构的特征,其实也就是将其展开的过程,就想两个人将其拉开一样。

在局部保持布结构的特征,不同的保持方法对应不同的流形算法。比如等距映射(ISOMAP)算法在降维后希望保持样本之间的测地距离而不是欧式距离,因为测地距离更能反映样本之间在流形中的真实距离。
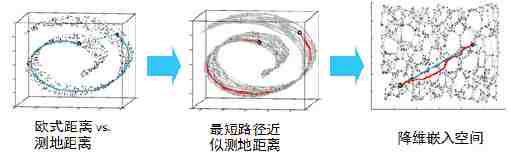
但等距映射算法有一个问题就是他要找所有样本全局的最优解,当数据量很大,样本维度很高时,计算非常的耗时,鉴于这个问题,LLE通过放弃所有样本全局最优的降维,只是通过保证局部最优来降维。同时假设样本集在局部是满足线性关系的,进一步减少的降维的计算量。
LLE思想
LLE首先假设数据在较小的局部是线性的,即某一个数据可以由它邻域中的几个样本来线性表示。比如我们有一个样本x1,我们在它的原始高维邻域里用K-近邻思想找到和它最近的三个样本x2,x3,x4. 然后我们假设x1可以由x2,x3,x4线性表示,即:
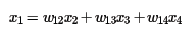
其中w12,w13,w14为权重系数。在通过LLE降维后,希望x1在低维空间对应的投影x1′,同时x2,x3,x4对应的投影x2′,x3′,x4′也尽量保持同样的线性关系,即

也就是说,投影前后线性关系的权重系数w12,w13,w14是尽量不变或者最小改变的。从上面可以看出,线性关系只在样本的附近起作用,离样本远的样本对局部的线性关系没有影响,因此降维的复杂度降低了很多。
LLE的推导
对于LLE,首先要确定邻域大小的选择,即需要多少个邻域样本来线性表示某个样本。假设这个值为k,可以通过和KNN一样的思想通过距离度量比如欧式距离来选择某样本的k个最近邻。
在寻找到某个样本的xi的k个最近邻之后需要找到找到xi和这k个最近邻之间的线性关系,也就是要找到线性关系的权重系数。找线性关系,这显然是一个回归问题。假设我们有m个n维样本{x1,x2,...,xm},可以用均方差作为回归问题的损失函数:即:
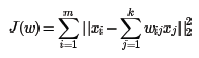
一般也会对权重系数wij做归一化的限制,即权重系数需要满足
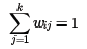
对于不在样本xi邻域内的样本xj,令对应的wij=0。也就是需要通过上面两个式子求出我们的权重系数。一般可以通过矩阵和拉格朗日子乘法来求解这个最优化问题。
对于第一个式子,先将其矩阵化:
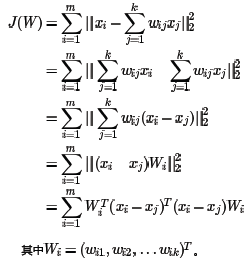
令矩阵
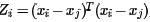
则第一个式子进一步简化为
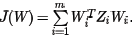
对于第二个式子,我们可以矩阵化为:
现在将矩阵化的两个式子用拉格朗日子乘法合为一个优化目标:
对W求导并令其值为0得:
其中 λ′=−0.5*λ为一个常数。权重系数Wi为:
现在得到了高维的权重系数,希望这些权重系数对应的线性关系在降维后的低维一样得到保持。假设n维样本集{x1,x2,...,xm}在低维的d维度对应投影为{y1,y2,...,ym}, 则我们希望保持线性关系,也就是希望对应的均方差损失函数最小,即最小化损失函数J(Y)如下:
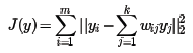
可以看到这个式子和在高维的损失函数几乎相同,唯一的区别是高维的式子中,高维数据已知,目标是求最小值对应的权重系数W,而我们在低维是权重系数W已知,求对应的低维数据。为了得到标准化的低维数据,一般也会加入约束条件如下:
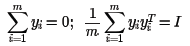
首先将目标损失函数矩阵化:
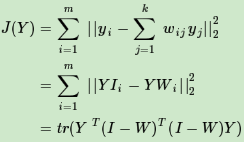
如果令M=(I−W)^T(I−W),则优化函数转变为最小化下式:J(Y)=tr(Y^TMY),tr为迹函数。约束函数矩阵化为:
Y^TY=mI
如果大家熟悉PCA的优化,就会发现这里的优化过程几乎一样。其实最小化J(Y)对应的Y就是M的最小的d个特征值所对应的d个特征向量组成的矩阵。
LLE算法流程
整个LLE算法用一张图可以表示如下:
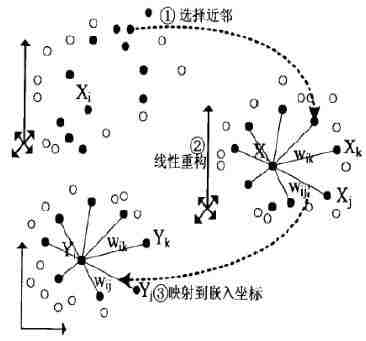
从图中可以看出,LLE算法主要分为三步,第一步是求K近邻的过程,这个过程使用了和KNN算法一样的求最近邻的方法;第二步,就是对每个样本求它在邻域里的K个近邻的线性关系,得到线性关系权重系数W;第三步就是利用权重系数来在低维里重构样本数据。
具体过程如下:
输入:样本集D={x1,x2,...,xm}, 最近邻数k,降维到的维数d
输出: 低维样本集矩阵D`
1) for i 1 to m, 按欧式距离作为度量,计算和xi最近的的k个最近邻(xi1,xi2,...,xik,)
2) for i 1 to m, 求出局部协方差矩阵Zi=(xi−xj)T(xi−xj),并求出对应的权重系数向量:
3) 由权重系数向量Wi组成权重系数矩阵W,计算矩阵M=(I−W)T(I−W)。
4) 计算矩阵M的前d+1个特征值,并计算这d+1个特征值对应的特征向量{y1,y2,...yd+1}。
5)由第二个特征向量到第d+1个特征向量所张成的矩阵即为输出低维样本集矩阵D′=(y2,y3,...yd+1)
LLE总结
LLE是广泛使用的图形图像降维方法,实现简单,但对数据的流形分布特征有严格的要求。比如不能是闭合流形,不能是稀疏的数据集,不能是分布不均匀的数据集等等,这限制了它的应用。下面总结下LLE算法的优缺点。
优点
1)可以学习任意维的局部线性的低维流形
2)算法归结为稀疏矩阵特征分解,计算复杂度相对较小,实现容易。
缺点
1)算法所学习的流形只能是不闭合的,且样本集是稠密均匀的。
2)算法对最近邻样本数的选择敏感,不同的最近邻数对最后的降维结果有很大影响。

参考:
- 周志华《机器学习》
- Neural Networks and Deep Learning by By Michael Nielsen
- 博客园http://www.cnblogs.com/pinard/p/6244265.html
- 李航《统计学习方法》
- Deep Learning, book by Ian Goodfellow, Yoshua Bengio, and Aaron Courville
近期热文
加入微信机器学习交流群
请添加微信:guodongwe1991
(备注姓名-单位-研究方向)
广告、商业合作
请添加微信:guodongwe1991
(备注:商务合作)
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。