机器学习(14)之评价准则RoC与PR

微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第二
【Python】:排名第三
【算法】:排名第四
前言
在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢?
TP, FP, TN, FN
1. True Positives,TP:预测为正样本,实际也为正样本的特征数
2. False Positives,FP:预测为正样本,实际为负样本的特征数
3. True Negatives,TN:预测为负样本,实际也为负样本的特征数
4. False Negatives,FN:预测为负样本,实际为正样本的特征数
听起来还是很费劲,不过我们用一张图就很容易理解了。图如下所示,里面绿色的半圆就是TP(True Positives), 红色的半圆就是FP(False Positives), 左边的灰色长方形(不包括绿色半圆),就是FN(False Negatives)。右边的浅灰色长方形(不包括红色半圆),就是TN(True Negatives)。这个绿色和红色组成的圆内代表我们分类得到模型结果认为是正值的样本。
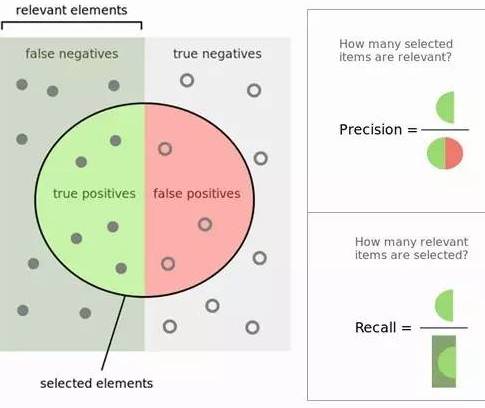
精确率(precision)与召回率(Recall)
精确率(Precision)的定义在上图可以看出,是绿色半圆除以红色绿色组成的圆。严格的数学定义如下:
P=TP/(TP+FP)
召回率(Recall)
的定义也在图上能看出,是绿色半圆除以左边的长方形。严格的数学定义如下
R=TP/(TP+FN)
特异性(specificity)的定义图上没有直接写明,这里给出,是红色半圆除以右边的长方形。严格的数学定义如下:
S=FP/(FP+TN)
F1值来综合评估精确率和召回率,它是精确率和召回率的调和均值。当精确率和召回率都高时,F1值也会高。严格的数学定义如下:
2/F1=1/P+1/R
有时候我们对精确率和召回率并不是一视同仁,比如有时候我们更加重视精确率。我们用一个参数β来度量两者之间的关系。如果β>1, 召回率有更大影响,如果β<1,精确率有更大影响。自然,当β=1的时候,精确率和召回率影响力相同,和F1形式一样。含有度量参数β的F1我们记为Fβ, 严格的数学定义如下:
Fβ=(1+β2)∗P∗R/(β2∗P+R)
RoC和PR
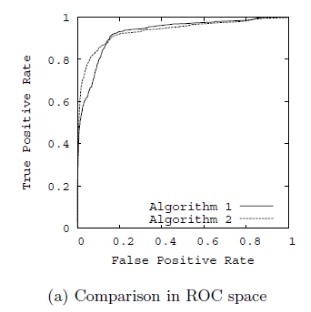
以召回率为y轴,以特异性为x轴,我们就直接得到了RoC曲线。从召回率和特异性的定义可以理解,召回率越高,特异性越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即AUC(Area Under Curve)值来作为算法和模型好坏的标准。
小结
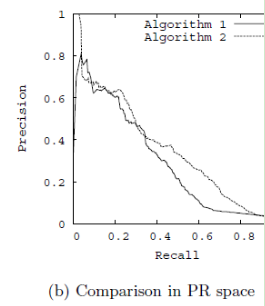
以精确率为y轴,以召回率为x轴,我们就得到了PR曲线。仍然从精确率和召回率的定义可以理解,精确率越高,召回率越高,我们的模型和算法就越高效。也就是画出来的PR曲线越靠近右上越好。如上图右图所示。使用RoC曲线和PR曲线,我们就能很方便的评估我们的模型的分类能力的优劣了。
参考:
1. 周志华《机器学习》
2. 博客园:作者(刘建平)http://www.cnblogs.com/pinard/p/5993450.html
3. 李航 《统计学习方法》


加我微信:guodongwe1991,备注姓名-单位-研究方向(加入微信机器学习交流1群)
招募 志愿者
广告、商业合作
请加QQ:[email protected]

喜欢,别忘关注~
帮助你在AI领域更好的发展,期待与你相遇!
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。