视觉prompt工程!无需微调、无需任何模型修改,让一个通用模型可以执行多种指定任务
社区是国内外知名的机器学习与自然语言处理社区,受众覆盖国内外NLP硕博生、高校老师以及企业研究人员。
转载自 | 极市平台
作者丨科技猛兽
太长不看版
本文做了什么工作
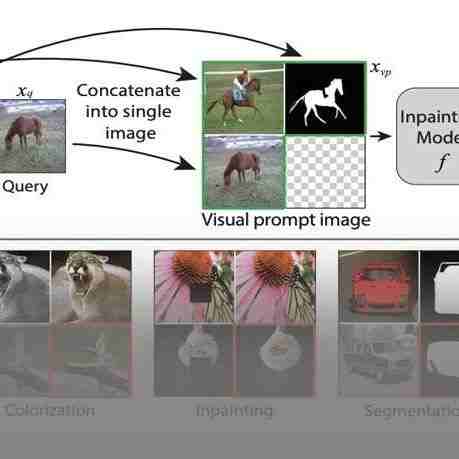
证明许多计算机视觉任务都可以按照图像修复任务来对待,只需给一些任务输入和输出示例和查询图像就可以做成。 构建了一个包含 88000 量的大型数据集,允许模型能够学习图像修复任务。无需任何标注信息,任务相关的描述。 展示出为训练数据集增加额外数据 (比如 ImageNet) 能获得更好效果。
论文名称:Visual Prompting via Image Inpainting (NeurIPS 2022) 译名:通过图像修复任务完成视觉提示
语言模型中一个通用模型做多种下游任务的特点能否迁移到视觉领域?
I love ice cream
MAE-VQGAN 方法介绍
给训练好的图像修复模型加提示
Visual Prompt 的设计
数据集
实验结果
下游任务实验结果
合成数据研究
数据集规模的影响
视觉提示工程
^Masked Autoencoders Are Scalable Vision Learners ^Taming Transformers for High-Resolution Image Synthesis
技术交流群邀请函 
△长按添加小助手 扫描二维码添加小助手微信请备注:姓名-学校/公司-研究方向 (如:小张-哈工大-对话系统) 即可申请加入自然语言处理/Pytorch等技术交流群
扫描二维码添加小助手微信
关于我们
MLNLP 社区是由国内外机器学习与自然语言处理学者联合构建的民间学术社区,目前已经发展为国内外知名的机器学习与自然语言处理社区,旨在促进机器学习,自然语言处理学术界、产业界和广大爱好者之间的进步。 社区可以为相关从业者的深造、就业及研究等方面提供开放交流平台。欢迎大家关注和加入我们。 
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。