超越Llama-2!微软新作Phi-3:手机上能跑的语言模型
点击下方卡片,关注“CVer”公众号
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!
转载自:机器之心 | 编辑:小舟、泽南
数据已成为提升大模型能力的重点。
Llama-3 刚发布没多久,竞争对手就来了,而且是可以在手机上运行的小体量模型。
本周二,微软发布了自研小尺寸模型 Phi-3。
新模型有三个版本,其中 Phi-3 mini 是一个拥有 38 亿参数的语言模型,经过 3.3 万亿 token 的训练,其整体性能在学术基准和内部测试上成绩优异。
尽管 Phi-3 mini 被优化至可部署在手机上,但它的性能可以与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美。微软表示,创新主要在于用于训练的数据集。
与此同时,Phi-3 与 Llama-2 使用相同的架构,方便开源社区在其基础上开发。
此前,微软的 Phi 系列模型曾经引发了人们的热议,去年 6 月,微软发布了《Textbooks Are All You Need》论文,用规模仅为 7B token 的「教科书质量」数据训练 1.3B 参数的模型 phi-1,实现了良好的性能。
去年 9 月,微软进一步探索这条道路,让 1.3B 参数的 Transformer 架构语言模型 Phi-1.5 显示出强大的编码能力。
去年底,微软提出的 Phi-2 具备了一定的常识能力,在 2.7B 的量级上多个基准测试成绩超过 Llama2 7B、Llama2 13B、Mistral 7B 等一众先进模型。
Phi-3 技术报告:https://arxiv.org/abs/2404.14219
刚刚提出的 phi-3-mini 是一个在 3.3 万亿个 token 上训练的 38 亿参数语言模型。实验测试表明,phi-3-mini 的整体性能可与 Mixtral 8x7B 和 GPT-3.5 等模型相媲美,例如 phi -3-mini 在 MMLU 上达到了 69%,在 MT-bench 上达到了 8.38。
微软之前对 phi 系列模型的研究表明,高质量的「小数据」能够让较小的模型具备良好的性能。phi-3-mini 在经过严格过滤的网络数据和合成数据(类似于 phi-2)上进行训练,并进一步调整了稳健性、安全性和聊天格式。
此外,研究团队还提供了针对 4.8T token 训练的 7B 和 14B 模型的初始参数扩展结果,称为 phi-3-small 和 phi-3-medium,两者都比 phi-3-mini 能力更强。
学术基准
在标准开源基准测试中,phi-3-mini 与 phi-2 、Mistral-7b-v0.1、Mixtral-8x7B、Gemma 7B 、Llama-3-instruct8B 和 GPT-3.5 的比较结果如下表所示,为了确保具有可比性,所有结果都是通过完全相同的 pipeline 得到的。
安全性
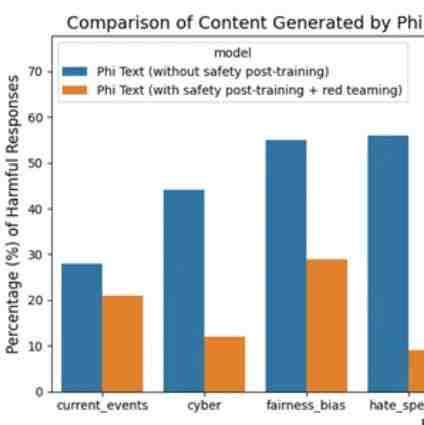
Phi-3-mini 是根据微软负责任人工智能原则开发的。保证大模型安全的总体方法包括训练后的安全调整、红队(red-teaming)测试、自动化测试和数十个 RAI 危害类别的评估。微软利用受 [BSA+ 24] 启发修改的有用和无害偏好数据集 [BJN+ 22、JLD+ 23] 和多个内部生成的数据集来解决安全性后训练(post-training)的 RAI 危害类别。微软一个独立的 red team 反复检查了 phi-3-mini,以进一步确定后训练过程中需要改进的领域。
根据 red team 的反馈,研究团队整理了额外的数据集从而完善后训练数据集。这一过程导致有害响应率显著降低,如图 3 所示。
下表显示了 phi-3-mini-4k 和 phi-3-mini-128k 与 phi-2、Mistral-7B-v0.1、Gemma 7B 的内部多轮对话 RAI 基准测试结果。该基准测试利用 GPT-4 模拟五个不同类别的多轮对话并评估模型响应。
缺陷
微软表示,就 LLM 能力而言,虽然 phi-3-mini 模型达到了与大型模型相似的语言理解和推理能力水平,但它在某些任务上仍然受到其规模的根本限制。例如,该模型根本没有能力存储太多「事实知识」,这可以从 TriviaQA 上的低评分中看出。不过,研究人员相信这些问题可以通过搜索引擎增强的方式来解决。
参考内容:https://news.ycombinator.com/item?id=40127806
何恺明在MIT授课的课件PPT下载
何恺明在MIT授课的课件PPT下载
CVPR 2024 论文和代码下载
CVPR 2024 论文和代码下载
Mamba、多模态和扩散模型交流群成立
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

 ▲扫码加入星球学习
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
阅读原文 ▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。