深入剖析:RDMA在高速网络的应用与实现方式
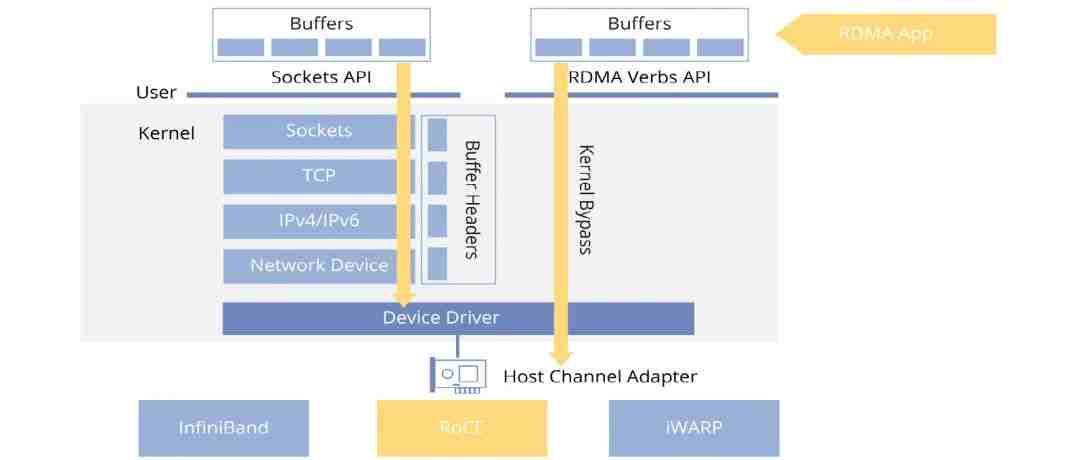
远程直接内存访问(RDMA)作为超高速网络内存访问技术的领军者,彻底颠覆了传统程序对远程计算节点内存资源的访问模式。其卓越性能的核心在于巧妙地绕过了操作系统内核层(如套接字、TCP/IP协议栈)对数据传输的干预,实现了网络通信范式的革新性跃迁。这一战略性的架构优化有效地减轻了与内核操作相关的CPU开销,使得数据可以直接从一个节点的网络接口卡(NIC)内存读写至另一个节点,这种硬件设备在特定场景下也被称为主机通道适配器(HCA)。
相关阅读:
在硬件实现方面,RDMA技术主要依托三种关键技术手段得以具体实施:InfiniBand、RoCE和iWARP。其中,InfiniBand与RoCE两种技术因其出色的性能表现及广泛应用,已被前沿技术专家广泛认可为行业主流选择。通过这两种技术,特别是在训练大型模型等对带宽和延迟有严苛要求的应用场景中,能够充分利用RDMA所赋予的高效低延迟特性构建高性能的高速网络系统,从而显著提高数据传输效率,并整体上优化系统的运行性能。
揭秘InfiniBand:卓越带宽的巅峰之作
目前,InfiniBand生态系统已经覆盖了100G和200G高速传输的主流技术。在这其中,增强数据速率(EDR,100G)和高数据速率(HDR,200G)成为该领域的一些专有名词。InfiniBand技术正迅速演进。
尽管InfiniBand拥有出色的性能,但由于其昂贵的成本,它经常被很多IT专业人士忽视,导致其在一般应用中的普及率相对较低。然而,在各大高校和科研机构的超级计算机中心,InfiniBand几乎成为不可或缺的标配,尤其是对于支持关键的超级计算任务而言。
与传统交换机不同,InfiniBand网络采用了独特的“胖树”网络拓扑结构,以确保任意两个计算节点之间的网络卡能够实现无缝通信。这种胖树结构包括两个层次:核心层负责流量转发并与计算节点分离,而接入层则连接各类计算节点。
在实施InfiniBand网络中的胖树拓扑时,其高昂的成本主要源于具有36个端口的汇聚交换机。其中,一半的端口必须连接到计算节点,而另一半则需要与上层核心交换机相连以实现无损通信。值得注意的是,每根电缆的价格大约为1.3万美元,并且为了保证无损通信,冗余连接是必需的。
正如俗话所说:“一分钱一分货”,这正是InfiniBand的真实写照。毫无争议地,它提供了无与伦比的高带宽和低延迟。根据维基百科的资料,相比以太网,InfiniBand的延迟显著更低,分别为100纳秒和230纳秒。这卓越的性能使得InfiniBand成为全球顶尖超级计算机中不可或缺的核心技术之一,受到微软、NVIDIA等行业巨头以及美国国家实验室的广泛采用。
释放RoCE潜力:经济高效的RDMA解决方案探索
在计算机网络技术领域中,RoCE(以太网融合上的RDMA)以其较高的性价比崭露头角,特别是在与成本高昂的InfiniBand等技术对比时。尽管RoCE并非低成本选项,但它为用户提供了更为经济的途径,在以太网上实现RDMA功能。近年来,RoCE技术迅速发展,并逐渐成为一种有竞争力的InfiniBand替代方案,尤其在对成本控制要求严苛的应用场景中表现突出。
然而,尽管具备性价比优势,要借助RoCE实现真正的无损网络仍面临挑战,整体网络成本难以低于采用InfiniBand方案的50%。
解锁大规模模型训练潜能:GPUDirect RDMA的关键作用
在大规模模型训练的过程中,节点间通信的成本至关重要。通过整合InfiniBand与GPU技术,GPUDirect RDMA这一颠覆性解决方案应运而生。该创新技术使得不同计算节点间的GPU能够直接进行数据交互,无需经过内存和CPU层级。简而言之,两个节点上GPU之间的复杂通信过程可直接经由InfiniBand网络接口卡完成,从而绕过了传统路径中必须通过CPU和内存的传输步骤。
在大规模模型训练背景下,GPUDirect RDMA的重要性尤为显著,因为模型通常存储于GPU内存中。传统的将模型复制至CPU并进一步传输至其他节点的过程耗时颇多,而使用GPUDirect RDMA则可以实现GPU间的直接信息交换,大幅度提升大规模模型训练的效率和性能表现。
优化大型模型网络架构:战略配置策略分析
在大型模型应用领域,要获得最佳性能,关键在于精密配置,特别是当GPU与InfiniBand网卡协同工作时。这里参考了合作伙伴NVIDIA推出的DGX系统,它倡导了一种GPU与InfiniBand网卡一对一配对的设计理念,并树立了行业标杆。在此架构下,一个标准计算节点能够集成9个InfiniBand网络接口控制器(NIC),其中一个用于连接存储系统,其余8个则分别对应单个GPU卡。
虽然这种配置方式理论上最为理想,但其成本相对较高,因此有必要探寻更具性价比的替代方案。一种有效的折衷策略是采用1:4的InfiniBand网卡与GPU卡的比例。
实际部署中,GPU和InfiniBand网卡均通过PCI-E交换机进行互联,一般情况下每个交换机可支持2块GPU。理想的状况是每块GPU都能精准分配到专属的InfiniBand网卡资源。然而,当两块GPU共享同一个InfiniBand网卡和PCI-E交换机时,会由于对共享资源的竞争而产生挑战。
InfiniBand网卡的数量直接影响着竞争程度及节点间通信效率,这一点可以通过附带图表生动展示。值得注意的是,在仅配备一块100 Gbps网卡的情况下,带宽可达12 GB/s,随着网卡数量增加,带宽几乎呈现线性增长趋势。设想一下,如果采用8块H100 GPU卡搭配8块400G InfiniBand NDR卡的配置方案,则能带来极为震撼的数据传输速率。
为每块GPU配备一张独立的网卡是最理想的配置情况:这样可以最大限度地减少资源争抢,提高节点间的通信效率和整体性能表现。
构建卓越:大型模型网络架构的轨式优化设计
在大规模模型运算的前沿领域,构建卓越性能的关键在于精心设计一套定制化的“轨式”网络拓扑结构,该结构是对传统高性能计算(HPC)中胖树架构的一种革新与优化。
此架构示意图生动展示了基础版胖树拓扑与经过轨式优化后的对比。系统内核心组件包括两台MQM8700系列HDR(高数据速率)交换机,它们通过四条HDR电缆实现高速互联,确保了极高的带宽和低延迟通信。每个DGX GPU节点装备了九块InfiniBand(IB)网卡,这些网卡在图中标注为主机通道适配器(HCAs),以满足不同功能需求。
其中特别指派一块IB卡作为存储连接专用接口(Storage Target),其余八块则专为大规模模型训练任务提供服务。具体布线策略如下:HCA1、HCA3、HCA5以及HCA7分别对接至第一个HDR交换机,而HCA2、HCA4、HCA6及HCA8则对应地与第二个交换机建立链接,以此形成了一种对称且高效的多路径传输体系,有力支撑了大规模并行计算环境下复杂模型的高效训练和数据交换。
为了营造高效流畅的网络环境,建议采用如图所示的全无阻塞、深度优化的轨式网络拓扑结构。在该设计中,每个DGX GPU节点均配备了八个InfiniBand (IB) 网卡,且每一个网卡都直接对接到一个独立的交换机单元,这些被称作叶交换机的设备总计部署了八台。连接布局极其精细:例如,HCA1与第一台叶交换机相连,HCA2与第二台相接,以此递增模式确保每张网卡都能专享一条高速链路。
后续的网络架构图清晰地揭示了底层细节,其中两台绿色标识的交换机代表脊交换机,它们负责实现四台蓝色标识的叶交换机之间的高速互联。整个系统通过80条线缆将蓝色和绿色交换机紧密耦合在一起,而蓝色叶交换机则策略性地设置于下层,直接与计算节点建立物理连接。
这种配置的核心优势在于其出色的可扩展性和低延迟特性,它能有效消除潜在的数据传输瓶颈,确保每一张IB卡都能够以最优速率与网络中的任何其他IB卡进行直接通信。这意味着任意GPU能够以前所未有的效率实现无缝、实时的远程内存访问,从而极大地提升了大规模并行计算环境中GPU间的协同工作效率。
在追求高性能且零损失的复杂网络环境中,选用InfiniBand或RoCE作为基础架构的核心决策应紧密贴合您的特定应用需求和现有设施条件。两者皆为业界翘楚,凭借低延迟、高吞吐量以及对CPU资源的极低占用率,在高性能计算(HPC)领域中展现出了卓越的适应性。
相关阅读:
InfiniBand高性能网络设计概述 面向E级计算的4款高性能处理器概述 基于鲲鹏处理器的高性能计算实践 高性能计算关键组件核心知识 一文全解高性能制造仿真技术 高性能计算:RoCE技术分析及应用 高性能计算:谈谈被忽视的国之重器 高性能计算:RoCE v2 vs. InfiniBand网络该怎么选? 高性能网络全面向RDMA进军
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”一起发送“服务器基础知识全解(终极版)”和“存储系统基础知识全解(终极版)”pdf及ppt版本,后续可享全店内容更新“免费”赠阅,价格仅收249元(原总价399元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。