顶刊IJCV 2024!基于概率表征的半监督对比学习框架
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!
转载自:将门创投
半监督语义分割算法(Semi-Supervised Semantic Segmentation, S4)能够使用较少的有标注数据对模型进行训练,并且获得一个性能良好的图像分割模型,因此得到了研究者们较为广泛的关注。然而,最近的许多研究都存在着以下问题:模型在无标注数据上训练时鲁棒性较差,容易受到错误的指导影响。本文研究者从现有的基于对比学习的S4算法鲁棒性欠佳这一问题出发,提出了概率表征来增强对比学习的鲁棒性,并且建立了PRCL框架,并在概率表征的基础上,提出了全局分布原型与虚拟负样本,两者都能够解决模型在单个迭代的训练中面临的问题,从而提升模型的最终表现。
点击下方卡片,关注“CVer”公众号
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!
转载自:将门创投
半监督语义分割算法(Semi-Supervised Semantic Segmentation, S4)能够使用较少的有标注数据对模型进行训练,并且获得一个性能良好的图像分割模型,因此得到了研究者们较为广泛的关注。然而,最近的许多研究都存在着以下问题:模型在无标注数据上训练时鲁棒性较差,容易受到错误的指导影响。本文研究者从现有的基于对比学习的S4算法鲁棒性欠佳这一问题出发,提出了概率表征来增强对比学习的鲁棒性,并且建立了PRCL框架,并在概率表征的基础上,提出了全局分布原型与虚拟负样本,两者都能够解决模型在单个迭代的训练中面临的问题,从而提升模型的最终表现。
论文题目:PRCL: Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation论文链接:https://arxiv.org/abs/2402.18117代码链接:https://github.com/Haoyu-Xie/PRC2
一、 引言 半监督语义分割算法(Semi-Supervised Semantic Segmentation, S4)能够使用较少的有标注数据对模型进行训练,并且获得一个性能良好的图像分割模型,因此得到了研究者们较为广泛的关注。最近的S4研究中,研究者们引入了像素级别的对比学习(Pixel-wise contrastive learning),进一步提升了模型的能力。然而,最近的许多研究都存在着以下问题:模型在无标注数据上训练时鲁棒性较差,容易受到错误的指导影响。为了提升模型的鲁棒性,我们提出了基于概率表征的对比学习框架(Probabilistic Representation Contrastive Learning framework, PRCL)。这个框架将像素级别的表征用高斯分布进行建模,并且根据表征语义的可靠性来微调它们在对比学习过程中的贡献。这样,模型就获得了容忍错误语义的表征的能力。随后,在概率表征(Probabilistic Representation, PR)的基础上,我们建立了全局分布原型(Global Distribution Prototype, GDP)和虚拟负样本(Virtual Negatives, VNs)来加入到对比学习的过程中,以解决传统像素级别的对比学习由小批量而造成的问题。实验表明,我们提出的PRCL框架在半监督设定下模型的分割能力达到了state-of-the-art的性能。此外,大量的消融实验也表明我们提出的模块的有效性。二、 基于概率表征的对比学习框架2.1 概率表征
近期的基于对比学习的S4算法框架大多都在原来的S4算法框架下(如老师-学生框架),将像素级别的对比学习视作一个辅助任务,让模型能够在潜在域上获得更规范的输出。具体的做法是将每一个表征分配上对应的语义信息,之后通过优化对比损失的方式将相同类的表征聚集在一起,将不同类的表征分散开来。由于每一个表征需要分配类别信息,在半监督条件设定下,模型在无标注数据上训练时获得的语义信息可能存在错误,这种错误会影响对比学习的效果,最终导致模型的准确度下降。
为了解决这个问题,我们在对比学习过程中使用了概率表征。概率表征与传统确定性表征不同的是,它不仅能够反映表征的位置,同时也能够反映表征出现在这个位置上的可能性,即表征分配到的语义信息的可靠性。
在实际训练中,我们使用高斯分布来拟合概率表征,高斯分布中的均值即代表概率表征的具体大小以及方向,高斯分布中的方差即代表概率表征的可靠性。均值和方差均由两个不同的MLP预测而得。有了概率表征之后,我们在衡量相似度与对比学习的过程中不仅考虑两个表征之间的距离,还考虑两个表征的可靠性,即两个表征如果距离很近但是可靠性很低,我们也不会认为这两个表征十分相似。由此,通过概率表征中方差的影响,模型在训练中能够容忍一定程度的噪声,极大地提高了鲁棒性。
图1 概率表征(右)与传统确定性表征(左)的差异
2.2 全局分布原型
在传统的基于对比学习的S4算法中中,由于批量大小(batch size)的限制,原型总是只集合了较少数量的同类表征的信息。我们认为这种做法会导致原型在训练的过程中产生比较大的漂移,从而无法给表征的聚合提供一个稳定的方向。这是由于每个迭代中的表征有可能存在着错误的语义信息,或者比较大的类间差距。
在概率表征的基础之上,我们提出了一种新的原型(Prototype)构建的方法。与传统原型构建方法不同的是,全局分布原型的构建是将训练过程中出现过的所有表征都考虑进原型的构建,即构建出的原型包含了训练中这一类的所有表征的信息。通过这种构建方式,全局分布原型能够让训练过程中的不同的迭代之间进行信息交互,容忍迭代中的瞬时噪声与表征的类间差异,从而让对比学习过程中的原型更加稳定,为对比学习过程提供一个稳定的指导方向。
2.3 虚拟负样本
另外,在传统基于对比学习的S4算法中,负样本的选取有两种方式:在当前迭代中的表征中选取或建立memory bank来存放并取用负样本。在这里,我们在全局分布原型的基础上,提出了虚拟负样本,用于高效的补充当前迭代中表征类别数可能少于数据集的类别数的问题。我们使用采样的方式从全局分布原型中获取虚拟表征,并且将其同真实表征一起用于构建对比学习中的负分布。
与只使用当前迭代中的真实表征的方法相比,我们的方法构建出的负分布能够更加全面,更加接近真实负分布。与建立memory bank的策略相比,由于我们的方法只需要存储全局分布原型,不需要存储很大数量的真实表征,因此消耗更少的存储空间,并且能够加快训练速度,获得更好的效果。
图2 两个由有限的batch size带来的问题(L1, L2)以及对应的解决办法(S1, S2)
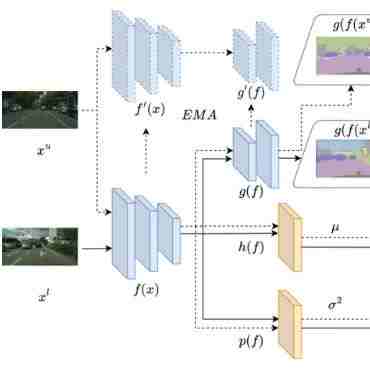
此外,PRCL整体框架如下图所示:
图3 PRCL的整体框架
三、实验结果
3.1 算法性能的对比
我们将PRCL与最近的SOTA S4算法在Pascal VOC 2012数据集和Cityscapes数据集上的性能进行定量比较。所有算法所采用的骨干网络均为ResNet-101。从结果中可以看到,相比于其他SOTA算法,无论在哪个数据集上,我们提出的PRCL都有极强的竞争力,尤其是在标签率较少的时候。这是由于在标签率较低时,模型预训练较少,产生的伪标签质量较差。我们提出的算法能够一定程度上增强模型在低质量伪标签下的表现,因此在低标签率下的表现更为优异。
3.2 概率表征的有效性
接下来我们展示了概率表征中方差的热度图与产生的伪标签情况的对比。热度图中颜色越红的地方代表这里的表征的语义信息越有可能不正确。从图中可以直观的看出概率表征中的方差有能力找到错误的伪标签与容易出现模棱两可的边缘部分,从而,这些部分的表征在对比学习中的贡献将会减少。
图4 概率表征方差热度图
下表展现了使用概率表征之后,模型的准确度将在很大的标签率范围内超过基线模型。
3.3 全局分布原型的有效性
下面展示的是有无更新策略的原型在训练中的漂移情况。从图中可以看出,如果不使用任何原型更新策略,即原型的计算总是通过集合当前迭代中所有的同类表征的信息这一方法,那么在相邻迭代中,原型的位置会发生比较大的漂移,导致在对比学习的过程中不能够给表征聚合提供一个稳定的方向。相反,有了更新策略之后,原型的漂移减小,表征聚合的方向更加稳定。另外,由于概率表征能够在建立原型的时候对错误的语义信息有容忍性,因此原型在更新的过程中漂移更小。
图5 不同更新方式的原型的漂移情况
下表展现了原型更新策略相比于基线模型的有效性。
3.4 虚拟负样本的有效性
下图简单展示了虚拟负样本的生成过程。虚拟负样本是通过全局分布原型采样获得的。它围绕在全局分布原型周围,相较于真实的表征来说,虚拟负样本能够包含该类表征的全局信息。最重要的是,使用生成虚拟负样本这一策略在对比学习构建负分布时进行补充,能够极大的减少需要的显存,因为我们只需要存储与类别数相同数量的全局分布原型,而不是存储具体的表征。
图6 虚拟负样本的示意图
下表展现了虚拟负样本在对比学习中的表现,并且定量地反映了节省的存储空间。
四、结论
在这一工作中,我们从现有的基于对比学习的S4算法鲁棒性欠佳这一问题出发,提出了概率表征来增强对比学习的鲁棒性,并且建立了PRCL框架。另外,我们在概率表征的基础上,提出了全局分布原型与虚拟负样本,两者都能够解决模型在单个迭代的训练中面临的问题,从而提升模型的最终表现。最后,我们希望我们的工作能够对之后的S4工作有所启发。
作者简介: 谢昊宇 东北大学博士四年级学生,博士期间于阿里巴巴通义实验室实习。主要研究方向为半监督学习、语义分割、文生图方向。目前在AAAI,ICCV等国际会议上发表论文多篇,国家奖学金获得者。 王昶棋 东北大学三年级硕士研究生,硕士期间曾在香港中文大学MMLab进行远程实习。主要研究方向为语义分割和半监督学习。目前在AAAI,ICCV等国际会议上发表论文、多篇。曾获得国家奖学金,东北大学校长奖学金等荣誉。 赵健 中国电信人工智能研究院青年科学家、西北工业大学研究员、北京图象图形学学会理事,博士毕业于新加坡国立大学,研究兴趣包括多媒体分析、临地安防、多模态大模型、生成式人工智能。围绕无约束视觉感知理解共发表CCF-A类论文32篇,以第一/通讯作者在T-PAMI、CVPR等国际权威期刊和会议上发表论文31篇,含一作T-PAMI×2(IF: 24.314)、IJCV×3(IF: 13.369)。曾入选中国科协及北京市科协“青年人才托举工程”,主持国自然青年科学基金等项目6项。获2023 CAAI吴文俊人工智能优秀青年奖、2022 CAAI吴文俊人工智能自然科学奖一等奖、PREMIA Lee Hwee Kuan奖、ACM MM最佳学生论文奖,7次在国际重要科技赛事中夺冠。 孙佰贵 2014浙江大学CAD&CG国家重点实验室计算机硕士毕业,导师为章国锋、鲍虎军老师。同年加入阿里巴巴,10年AI经验,一直从事深度学习研发工作。4年淘宝技术部&搜索事业部,5年达摩院,目前在通义实验室负责人物AIGC,曾获得淘宝技术部最佳新人,阿里巴巴开源先锋人物等奖项。参与研发的大规模应用代表工作有:拍立淘、绿网/云盾、DeepCTR、钉钉考勤机、阿里云人脸API版块、FaceChain等。曾获得WiderFace检测6项冠军,6项国内外开源项目/个人奖项。目前发表合作顶会/刊论文26+篇,谷歌学术引用1070+,开源Star 8K+。
Illustration From IconScout By Delesign Graphics
何恺明在MIT授课的课件PPT下载
何恺明在MIT授课的课件PPT下载
CVPR 2024 论文和代码下载
CVPR 2024 论文和代码下载
Mamba和扩散模型交流群成立
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

 ▲扫码加入星球学习
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。