256个内核的Arm芯片猛兽,AmpereOne蓄势待发
👆如果您希望可以时常见面,欢迎标星🌟收藏哦~
来源:内容由半导体行业观察(ID:icbank)编译自nextplatform,谢谢。
服务器 CPU 有多少个核心就足够了?多多益善!
在过去的二十年中,计算引擎的游戏一直是尝试将尽可能多的内核和附加功能封装到一个插槽中,并使每单位功耗和散热的整体系统性价比下降。
第一批双核处理器于 2001 年进入数据中心,大约四年后,芯片时钟速度的Denard缩放或多或少停止了,这是芯片架构师在架构增强方面的最后一次免费搭车。当时摩尔定律仍然很强大,但显然已进入中年,因为每个制造节点的晶体管成本不断变得越来越小,但速度正在下降。
在 10 纳米屏障附近,每个晶体管的成本开始上升而不是下降,并且在可预见的未来,这种情况将持续下去,直到我们找到 CMOS 芯片蚀刻的替代方案。这可能意味着只要我们任何一个达到一定阶段的人都会关心这个问题。
因此,我们希望计算引擎上有越来越多的核心,充满小芯片的插槽正在成为主板,就像黑洞将周围的组件吸进去一样,因为任何可以将信号保持在插槽内的东西都会增加计算量和经济性 即使转向小芯片对功耗和散热造成各种破坏,也能提高效率。互连在插座功率预算中所占的份额越来越大,但转向小芯片可以提高良率,从而降低制造成本,并提供我们认为行业所需的灵活性。为什么您的计算引擎插槽只能配备来自一家芯片制造商的组件?你的主板从来没有这样做过。
正是在这样的背景下,以及为人工智能推理和其他更传统的工作负载创建更好的计算引擎的愿望,AmpereComputing 暗示未来将推出 AmpereOne 计算引擎。
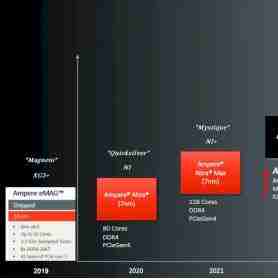
AmpereComputing 最初使用 Applied Micro 创建的 X-Gene 3 内核,Applied Micro 是前十年的原始定制 Arm 服务器芯片制造商,在 2018 年初成立时,它构成了 Ampere 基础的一部分。在 The Next Platform 上,我们创建了增强型 AmpereComputingArm 服务器芯片路线图,其中包括 2019 年的原始 eMAG 芯片的代号“Magneto”,并且我们已将最新 AmpereOne 处理器中使用的自研内核命名,因此我们不会疯狂地谈论该公司的芯片阵容。
这是我们 2022 年 5 月关于 Ampere 路线图的原始故事(《Ampere的芯片路线图》)。刚刚,我们与 Ampere 计算首席产品官 Jeff Wittich 进行的对话相关,以获取有关的最新信息 AmpereOne 路线图的进展。
在此路线图上,显示的日期大致与芯片从代工厂返回到开始向早期采用者客户提供样品之间的时间相关。它们往往会在大约一年后批量发货,这对于交换机芯片等各种 ASIC 来说很常见。当feeds和speeds可用,并且芯片接近批量发货时,我们将这个时间称为芯片的“发布”。
192核心的“Siryn”AmpereOne-1芯片基于台积电5纳米工艺蚀刻的A1核心,是安培计算首款自主研发的Arm核心 ,这是真正的 Ampere Computing代号,但我们将其称为 AmpereOne-1,因此我们可以将其与后续的 AmpereOne 芯片区分开来。这个 192 核 Siryn 芯片有 8 个 DDR5 内存通道,与 Amazon Web Services 的 Graviton3 Arm 服务器 CPU 设计一样,AmpereOne-1 设计将所有计算核心放在一个单片芯片上,然后将内存控制器和 I/O 外部控制器小芯片封装起来。AmpereOne-1 的 SKU 具有 136、144、160、176 和 192 个活动核心,功耗范围为 200 瓦到 350 瓦,核心运行频率为 3 GHz。
Wittich 在我们的电话会议上提醒我们,这次电话会议表面上是关于 CPU 上的人工智能推理,更新后的 AmpereOne 芯片将于今年晚些时候推出,具有 12 个内存通道。在我们的路线图中,这被称为“Polaris”芯片 - 这是我们的代号 - 它使用 A2 内核,比 A1 内核具有更高的性能和更多功能。
AmpereOne-2(我们也这么称呼它)的 DDR5 内存控制器数量将增加 33%,并且根据支持的内存速度和容量,容量将增加约三分之一,甚至可能增加 40% 甚至 50% 带宽。AmpereOne-1 具有运行频率为 4.8 GHz 的 DDR5 内存,但您可以获得运行频率高达 6 GHz 或 7.8 GHz 的 DIMM。如果你不介意热量,那么当有十几个内存控制器在 7.8 GHz 下运行时,这款采用 TSMC 增强型 5 纳米工艺蚀刻的 AmpereOne-2 芯片的带宽可能会增加 2.25 倍。我们认为 AmpereComputing 将采用 6.4GHz DDR5 内存,并将每个插槽的带宽加倍,这将有助于在 CPU 上进行人工智能推理。
内存控制器的增强可能为我们所说的 AmpereOne-3 芯片奠定了基础,这是我们给它起的名字,采用台积电的 3 纳米(准确地说是 3N)工艺蚀刻而成。我们认为这将使用改进的 A2+ 核心。Wittich 向我们证实,未来的 AmpereOne 芯片实际上正在使用 3N 工艺,并且在即将推出时正在台积电进行蚀刻。然后他告诉我们,这个未来的芯片将有 256 个核心。他没有深入讨论小芯片架构,但确实表示 Ampere 计算正在使用 PCI-Express 的 UCI-Express 插槽内变体作为未来设计的小芯片互连。
“我们在计算方面的进展相当快,”Wittich 告诉 The Next Platform。“这个设计包含了许多其他云功能——围绕性能管理的内容,以充分利用所有这些核心。在每个芯片版本中,我们都会对 CPU 内核进行通常被认为是代际的更改。我们每一代人都在增加很多东西。因此,您将看到更多的性能、更高的效率、更多的功能(例如安全性增强),所有这些都发生在微架构级别。但我们做了很多工作来确保您在所有 AmpereOne 上获得出色的性能一致性。我们还在 256 核设计中采用了小芯片方法,这也是又一步。Chiplet 是我们整体战略的重要组成部分。”
我们认为,未来的 AmpereOne-3 芯片实际上很有可能在核心上采用双小芯片设计,每个小芯片有 128 个核心。它可能是四小芯片设计,每个小芯片有 64 个内核。
看起来 AWS 有两个小芯片组成了 Graviton4,使用 Arm Ltd 的“Demeter”V2 内核,每个计算小芯片有 48 个内核。顺便说一句,Graviton4 有十几个 DDR5 内存控制器。如果 AWS 能够打破其单一的计算芯片,那么 Ampere 计算也能做到。
我们还认为AmpereOne-3将支持PCI-Express 6.0 I/O控制器,其带宽对于AI推理工作负载也很重要。
AmpereOne-3 也很有可能拥有更胖的向量(fatter vectors ) - AmpereOne-1 有两个 128 位向量,就像 Neoverse N1 和 N2 内核所做的那样,但我们认为这需要加倍到四个 128 位 向量或真正的张量核心矩阵数学单元必须添加到核心或作为核心图块的附件。可能性有很多种,但我们知道一件事:
在上面的测试中,机器都是单套接字实例(single socket instances),要么在 Oracle 或 AWS 云(左侧)上运行,要么使用在测试实验室中运行的 OEM Iron(右侧)。
DLRM 是 Meta Platforms 的深度学习推荐引擎;BERT是Google早期的自然语言转换器;Whisper 是 OpenAI 的自动语音识别系统;ResNet-50 是典型的图像识别模型,推动了整个机器学习 AI 的发展。
在左侧,AmpereComputing 的 80 核 Altra CPU 和 Nvidia T4 GPU 加速器之间每花费一美元的推理结果非常接近,除了 OpenAI Whisper 自动语音识别系统,其中 Altra CPU 远远超过了 T4,而且让英特尔“Ice Lake”Xeon 和 AWS Graviton3 芯片看起来相当糟糕。
在右侧,我们只是测量四种工作负载的每秒推理量,这一次,它将 128 核 Altra Max M128-30 与 40 核 Intel Xeon SP-8380 和 64 核 AMD Epyc 7763 进行比较。显然,有更新的英特尔和 AMD 处理器,它们在一个插槽中塞进了更多的内核。但 Ampere 正在开始其 192 核 AmpereOne A192-32X 的升级,其整数性能大约是 Altra Max M128-30 的两倍,矢量单元的性能可能高出 1.5 倍,如果架构发生变化,可能会, 多达 2 倍以上。我们预计明年推出的 256 核芯片将在整数和矢量性能上有很大的提升。
以下是使用 OpenAI Whisper 语音转文本平台的有趣比较,以每秒事务数(transactions per second)进行评级:
使用whisper-medium模型,Altra Max M128-30 每秒可以执行 375,415 个事务 (TPS),Nvidia“Hopper”H100 GPU 可以执行 395,500 TPS。
如果将机架功率限制在 15 千瓦(这对于企业数据中心来说是合理的),那么 60 个机架中使用 Altra Max CPU 的 2,400 台服务器的成本为 1,720 万美元,并可提供 9.01 亿 TPS。计算得出,性价比为每百万 TPS 18,979 美元。在相同的 60 个机架空间中,每个机架 15 千瓦,每个机架只有一个 DGX H100,这并不算多。这 60 台 DGX H100 的成本为 2730 万美元,只能提供 1.9 亿 TPS,但每百万 TPS 的成本为 143,684 美元。CPU 推理在 Whisper 上的性价比提高了 7.6 倍。您可以在每个机架中放置 4 个 DGX,然后购买 240 个,总计 1.092 亿美元,并驱动 7.6 亿 TPS,但性价比不会改变。我们怀疑 Whisper 模型正在使用 FP16 半精度数据格式和处理,通过转向 FP8,Nvidia 可以将这一差距缩小一半。但一半的差距仍然是 3.8 倍的性价比差异,有利于安培计算 Arm CPU。
当 Nvidia 使用“Blackwell”B100 GPU 提供 FP4 推理处理并提供 5 倍的原始推理性能时,AmpereOne-3 配备 256 个核心,可能提供 3 到 4 倍的推理性能(这取决于 AmpereOne-3 的性能) 看起来像),Nvidia 将缩小一些差距。
我们必须拭目以待。但目前还不要指望企业数据中心的 CPU 能够运行具有数百到数千亿参数的中等规模的 AI 模型。
话虽如此,我们很高兴看到 192 核 AmpereOne-2 与 AMD“Genoa”Epyc 9004s、AMD“Bergamo”Epyc 9004s、英特尔“Sapphire Rapids”Xeon SP 以及 Nvidia Hopper H200s 的比较 比 H100 更大的内存。英特尔“Sierra Forest”至强 6 处理器将于今年第二季度推出,可扩展至 288 个核心,但没有 AVX-512 矢量或 AMX 矩阵数学单元,对于 AI 推理来说基本上毫无用处。
👇👇 点击文末【阅读原文】,可查看原文链接!
↓推荐一场行业会议↓
点这里👆加关注,锁定更多原创内容
END
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。
今天是《半导体行业观察》为您分享的第3738期内容,欢迎关注。
推荐阅读
『半导体第一垂直媒体』
实时 专业 原创 深度
公众号ID:icbank
喜欢我们的内容就点“在看”分享给小伙伴哦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。