高性能GPU服务器硬件拓扑与集群组网
01、术语与基础
大模型训练一般都是用单机 8 卡 GPU 主机组成集群,机型包括 8*{A100,A800,H100,H800} 。下面一台典型 8*A100 GPU 的主机内硬件拓扑:
CPU、内存、存储(NVME)、GPU、网卡等支持 PICe 的设备,都可以连接到 PCIe 总线或专门的 PCIe 交换芯片,实现互联互通。
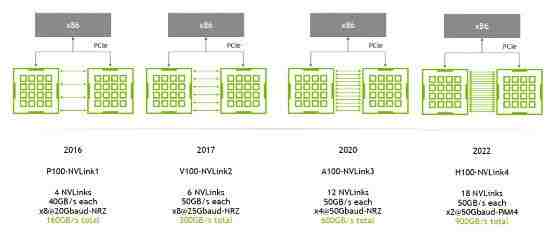
是一种短距离通信链路,保证包的成功传输,更高性能,替代 PCIe, 支持多 lane,link 带宽随 lane 数量线性增长, 同一台 node 内的 GPU 通过 NVLink 以 full-mesh 方式(类似 spine-leaf)互联, NVIDIA 专利技术。
A100 是 2 lanes/NVSwitch * 6 NVSwitch * 50GB/s/lane= 600GB/s 双向带宽(单向 300GB/s)。注意:这是一个 GPU 到所有 NVSwitch 的总带宽; A800 被阉割了 4 条 lane,所以是 8 lane * 50GB/s/lane = 400GB/s 双向带宽(单向 200GB/s)。
NVSwitch 听名字像是交换机,但实际上是 GPU module 上的交换芯片,用来连接同一台主机内的 GPU。
AMD MI300X 采用 192GB HBM3 方案,带宽 5.2TB/s; HBM3e 是 HBM3 的增强版,速度从 6.4GT/s 到 8GT/s。
大规模 GPU 训练的性能与数据传输速度有直接关系。这里面涉及到很多链路,比如 PCIe 带宽、内存带宽、NVLink 带宽、HBM 带宽、网络带宽等等。
网络习惯用 bits/second (b/s) 表示之外,并且一般说的都是单向(TX/RX); 其他模块带宽基本用 byte/sedond (B/s) 或 transactions/second (T/s) 表示,并且一般都是双向总带宽。
主机内拓扑:2-2-4-6-8-8
2 片 CPU(及两边的内存,NUMA) 2 张存储网卡(访问分布式存储,带内管理等) 4 个 PCIe Gen4 Switch 芯片 6 个 NVSwitch 芯片 8 个 GPU 8 个 GPU 专属网卡
从分布式存储读写数据,例如读训练数据、写 checkpoint 等; 正常的 node 管理,ssh,监控采集等等。
A100 用的 NVLink3,50GB/s/lane,所以 full-mesh 里的每条线就是 12*50GB/s=600GB/s,注意这个是双向带宽,单向只有 300GB/s。 A800 是阉割版,12 lane 变成 8 lane,所以每条线 8*50GB/s=400GB/s,单向 200GB/s。
GPU 之间(左上角区域):都是 NV8,表示 8 条 NVLink 连接; NIC 之间:
在同一片 CPU 上:NODE,表示不需要跨 NUMA,但需要跨 PCIe 交换芯片;
GPU 和 NIC 之间:
这个网络的目的是 GPU 与其他 node 的 GPU 交换数据; 每个 GPU 和自己的网卡之间通过 PCIe 交换芯片连接:GPU <--> PCIe Switch <--> NIC。
RoCEv2:公有云卖的 8 卡 GPU 主机基本都是这种网络,比如 CX6 8*100Gbps 配置;在性能达标的前提下,(相对)便宜; InfiniBand (IB):同等网卡带宽下,性能比 RoCEv2 好 20% 以上,但是价格贵一倍。
同主机 GPU 之间:走 NVLink,双向 600GB/s,单向 300GB/s; 同主机 GPU 和自己的网卡之间:走 PICe Gen4 Switch 芯片,双向 64GB/s,单向 32GB/s; 跨主机 GPU 之间:需要通过网卡收发数据,这个就看网卡带宽了,目前国内 A100/A800 机型配套的主流带宽是(单向) 100Gbps=12.5GB/s。所以跨机通信相比主机内通信性能要下降很多。
200Gbps==25GB/s:已经接近 PCIe Gen4 的单向带宽; 400Gbps==50GB/s:已经超过 PCIe Gen4 的单向带宽。
PCIe Gen5 SXM5:性能更高一些
下面是一片 H100 GPU 芯片的内部结构:
4nm 工艺; 最下面一排是 18 根 Gen4 NVLink;双向总带宽 18 lanes * 25GB/s/lane = 900GB/s; 中间蓝色的是 L2 cache; 左右两侧是 HBM 芯片,即显存。
比如 FP64 和 NVLink 都干掉了; 使用 GDDR6 显存,不依赖 HBM 产能(及先进封装)。
大头可能来自 GPU 本身价格降低:因为去掉了一些模块和功能,或者用便宜的产品替代; 整机成本也有节省:例如去掉了一层 PCIe Gen4 Swtich;不过相比于 4x/8x GPU,整机的其他部分都可以说送的了。
下面是一个官方标称性能对比:
性能 1.2x ~ 2x(看具体场景); 功耗:两台 L40S 和单台 A100 差不多。
2 片 CPU(NUMA) 2 张双口 CX7 网卡(每张网卡 2*200Gbps) 4 片 L40S GPU 另外,存储网卡只配 1 张(双口),直连在任意一片 CPU 上
单机 8 卡 L40S GPU 主机拓扑,来自 NVIDIA L40S 官方推介材料
说是现在PCIe Gen5 Switch 单片价格 1w 刀(不知真假),一台机器需要 2 片;价格不划算; PCIe switch 只有一家在生产,产能受限,周期很长; 平摊到每片 GPU 的网络带宽减半。
PCIe Gen4 x16 双向 64GB/s,单向 32GB/s; CPU 处理瓶颈?TODO
PCIe Gen4 x16 双向 64GB/s,单向 32GB/s; 平均每个 GPU 一个单向 200Gbps 网口,单向折算 25GB/s; 需要 NCCL 支持,官方说新版本 NCCL 正在针对 L40S 适配,默认行为就是去外面绕一圈回来;
任何两片 GPU 的通信带宽和延迟都是一样的,是否在一台机器内或一片 CPU 下面并不重要,集群可以横向扩展(scaling up,compared with scaling in); GPU 机器成本降低;但其实对于那些对网络带宽要求没那么高的业务来说,是把 NVLINK 的成本转嫁给了网络,这时候必须要组建 200Gbps 网络,否则发挥不出 L40S 多卡训练的性能。
L40S:200Gbps(网卡单向线速) A100:300GB/s(NVLINK3 单向) == 12x200Gbps A800:200GB/s(NVLINK3 单向) == 8x200Gbps
相关阅读:
Arm架构升级,v9与v8版本有何差异? 从X86到ARM,跨越CPU架构鸿沟 走进芯时代:AI算力GPU行业深度报告 高性能计算:RoCE技术分析及应用 高性能计算:谈谈被忽视的国之重器 高性能计算:RoCE v2 vs. InfiniBand网络该怎么选? 高性能网络全面向RDMA进军
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”一起发送“服务器基础知识全解(终极版)”和“存储系统基础知识全解(终极版)”pdf及ppt版本,后续可享全店内容更新“免费”赠阅,价格仅收249元(原总价399元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。