Nvidia AI芯片架构分析
前期分享参看“Nvidia AI芯片路线图分析与解读”、“Nvidia芯片工艺洞察和推演”。
互联技术在很大程度上决定了芯片和系统的物理架构。Nvidia利用NVLink-C2C这种低时延、高密度、低成本的互联技术来构建SuperChip超级芯片,旨在兼顾性能和成本打造差异化竞争力。与传统的SerDes互联相比,NVLink C2C采用了高密度单端架构和NRZ调制,使其在实现相同互联带宽时能够在时延、功耗、面积等方面达到最佳平衡点;而与Chiplet Die-to-Die互联相比,NVLink C2C具备更强的驱动能力,并支持独立封装芯片间的互联,因此可以使用标准封装,满足某些芯片的低成本需求。
为了确保CPU和GPU之间的内存一致性操作 (Cache-Coherency),对于NVLink C2C接口有极低时延的要求。H100 GPU的左侧需要同时支持NVLink C2C和PCIE接口,前者H100 GPU的左侧需要同时支持NVLink C2C和PCIE接口,前者用于实现与Nvidia自研Grace CPU组成Grace-Hopper SuperChip,后者用于实现与PCIE交换芯片、第三方CPU、DPU、SmartNIC对接。NVLink C2C的互联带宽为900GB/s,PCIE互联带宽为128GB/s。
而当Hopper GPU与Grace CPU组成SuperChip时,需要支持封装级的互联。值得注意的是,Grace CPU之间也可以通过NVLink C2C互联组成Grace CPU SuperChip。考虑到成本因素,Nvidia没有选择采用双Die合封的方式组成Grace CPU,而是通过封装间的C2C互联组成SuperChip超级芯片。
从时延角度来看,NVLink C2C采用40Gbps NRZ调制,可以实现无误码运行 (BER<1e-12),免除FEC,接口时延可以做到小于5ns。相比之下,112G DSP架构的SerDes本身时延可以高达20ns,因为采用了PAM4调制,因此还需要引入FEC,这会额外增加百纳秒量级的时延。此外,NVLink C2C采用了独立的时钟线来传递时钟信号,因此数据线上的信号不需要维持通信信号直流均衡的编码或扰码,可以进一步将时延降低到极致。因此,引入NVLink C2C的主要动机是满足芯片间低时延互联需求。
从互联密度来看,当前112G SerDes的边密度可以达到12.8Tbps每边长,远远大于当前H100的(900+128)GB/s * 8/2 = 4.112Tbps的边密度需求。NVLink C2C的面密度是SerDes的3到4倍,(169Gbps/mm2 vs. 552Gbps/mm2)。而当前NVLink C2C的边密度还略低于SerDes (281Gbps/mm vs. 304Gbps/mm)。更高的边密度显然不是NVLink C2C需要解决的主要矛盾。
从驱动能力来看,112G SerDes的驱动能力远大于NVLink C2C。这在一定程度上会制约NVLink C2C的应用范围,未来类似于NVLink C2C的单端传输线技术有可能进一步演进,拓展传输距离,尤其是在224G 及以上SerDes时代,芯片间互联更加依赖于电缆解决方案,这对与计算系统是不友好的,会带来诸如芯片布局、散热困难等一系列工程挑战,同时也需要解决电缆方案成本过高的问题。
从功耗来看,112G SerDes的功耗效率为5.5pJ/bit,而NVLink C2C的功耗效率为1.3pJ/bit。在3.6Tbps互联带宽下,SerDes和NVLink C2C的功耗分别为19.8W和4.68W。虽然单独考虑芯片间互联时,功耗降低很多,但是H100 GPU芯片整体功耗大约为700W,因此互联功耗在整个芯片功耗中所占比例较小。
从成本角度来看,NVLink C2C的面积和功耗优于SerDes互联。因此,在提供相同互联带宽的情况下,它可以节省更多的芯片面积用于计算和缓存。然而,考虑到计算芯片并不是IO密集型芯片,因此这种成本节约的比例并不显著。但是,如果将双Chiplet芯粒拼装成更大规模的芯片时,NVLink C2C可以在某些场景下可以避免先进封装的使用,这对降低芯片成本有明显的帮助,例如Grace CPU SuperChip超级芯片选择标准封装加上NVLink C2C互联的方式进行扩展可以降低成本。在当前工艺水平下,先进封装的成本远高于逻辑Die本身。
C2C互联技术的另一个潜在的应用场景是大容量交换芯片,当其容量突破200T时,传统架构的SerDes面积和功耗占比过高,给芯片的设计和制造带来困难。在这种情况下,可以利用出封装的C2C互联技术来实现IO的扇出,同时尽量避免使用先进的封装技术,以降低成本。然而,目前的NVLink C2C技术并不适合这一应用场景,因为它无法与标准SerDes实现比特透明的转换。因此,需要引入背靠背的协议转换,这会增加时延和面积功耗。
Grace CPU 具有上下翻转对称性,因此单个芯片设计可以支持同构 Die 组成 SuperChip 超级芯片。Hopper GPU 不具备上下和左右翻转对称性,未来双 Die B100 GPU 芯片可能由两颗异构 Die 组成。
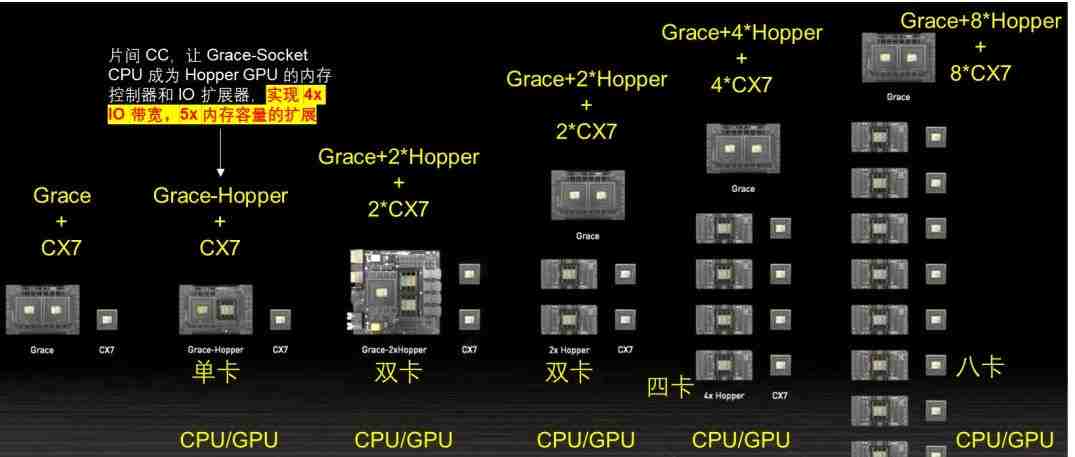
NVLink 和 NVLink C2C 技术提供了更灵活设计,实现了 CPU 和 GPU 灵活配置,可以构建满足不同应用需求的系统架构。NVLink C2C 可以提供灵活的CPU、GPU算力配比,可组成 1/0,0.5/1,0.5/2,1/4,1/8 等多种组合的硬件系统。NVLink C2C支持Grace CPU和Hopper GPU芯片间内存一致性操作 (Cache-Coherency),让 Grace CPU 成为 Hopper GPU 的内存控制器和 IO 扩展器,实现了 4倍 IO 带宽和5倍内存容量的扩展。这种架构打破了HBM的瓶颈,实现了内存超发。对训练影响是可以缓存更大模型,利用ZeRO等技术外存缓存模型,带宽提升能减少Fetch Weight的IO开销。对推理影响是可以缓存更大模型,按需加载模型切片推理,有可能在单CPU-GPU超级芯片内完成大模型推理 [23]。
有媒体测算Nvidia的H100利润率达到90%。同时也给出了估算的H100的成本构成,Nvidia向台积电下订单,用 N4工艺制造 GPU 芯片,平均每颗成本 155 美元。Nvidia从 SK 海力士(未来可能有三星、美光)采购六颗 HBM3芯片,成本大概 2000 美元。台积电生产出来的 GPU 和Nvidia采购的 HBM3 芯片,一起送到台积电 CoWoS 封装产线,以性能折损最小的方式加工成 H100,成本大约 723 美元 [24]。
先进封装成本高,是逻辑芯片裸Die成本的3 到4倍以上, GPU内存的成本占比超过 60%。按照DDR: 5美金/GB,HBM: 15美金/GB以及参考文献 [25][26] 中给出的GPU计算Die和先进封装的成本测算,H100 GPU HBM成本占比为62.5%;GH200中HBM和LPDDR的成本占比为78.2%。
虽然不同来源的信息对各个部件的绝对成本估算略有不同,但可以得出明确的结论:内存在AI计算系统中的成本占比可高达60%到70%以上;先进封装的成本是计算Die成本的3到4倍以上。在接近Reticle面积极限的大芯片良率达到80%的情况下,先进封装无法有效地降低成本。因此,应该遵循非必要不使用的原则。
Nvidia与AMD和Intel GPU 架构对比
AMD的GPU相对于Nvidia更加依赖先进封装技术。MI250系列GPU采用了基于EFB硅桥的晶圆级封装技术,而MI300系列GPU则应用了AID晶圆级有源封装基板技术。相比之下,Nvidia并没有用尽先进封装的能力,一方面在当前代际的GPU中保持了相对较低的成本,另一方面也为下一代GPU保留了一部分工程工艺的价值发挥空间。
Intel Ponte Vecchio GPU将Chiplet和先进封装技术推向了极致,它涉及5个工艺节点(包括TSMC和Intel两家厂商的不同工艺),47个有源的Tile,并同时采用了EMIB 2.5D和Foveros 3D封装技术。可以说,它更像是一个先进封装技术的试验场。Intel 的主力AI芯片是Gaudi系列AI加速芯片 [27][28][29]。值得注意的是Gaudi系列AI芯片是由TSMC代工的Gaudi 2采用的是TSMC 7nm工艺,Gaudi 3采用的是TSMC 5nm工艺。
未完待续…
作者:陆玉春
来源:
https://www.chaspark.com/#/hotspots/950120945305616384
更多GPU技术细节,请参考文章“最新版:GPU显卡天梯图(2023年11月)”,“全球GPU呈现“一超一强”竞争格局”,“2023年GPU显卡词条报告”,“HBM崛起:从GPU到CPU”,“英伟达GPU龙头稳固,国内逐步追赶(2023)”,“英伟达L40S GPU架构及A100、H100对比”,“AI芯片第一极:GPU性能、技术全面分析”,“主流国产GPU产品及规格概述(2023)”,“新型GPU云桌面发展白皮书”,“国内外GPU现状:海外龙头领跑,国产差距明显”,“GPGPU流式多处理器架构及原理”等等。
相关阅读:
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
全店内容持续更新,现下单“架构师技术全店资料打包汇总(全)”一起发送“服务器基础知识全解(终极版)”和“存储系统基础知识全解(终极版)”pdf及ppt版本,后续可享全店内容更新“免费”赠阅,价格仅收249元(原总价399元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
关键词
英伟达
性能
算力
技术
架构
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。