小模型怎么扩大参数?SOLAR: “自我嫁接”就行!
作者:张俊林,新浪微博新技术研发负责人编辑:青稞AI
SOLAR 这种“模型嫁接”很有意思!
最近的Huggingface LLM榜单都快被SOLAR这种“嫁接模型”刷烂了,Top 10模型都是10.7B,很明显是SOLAR的魔改版。
SOLAR是模型嫁接的代表,主要利用Mistral 7B来进行自我嫁接,目前榜单上的嫁接模型应该都是用同一个模型自我嫁接的,这个方向挺有意思的,应该还可以做很多更有趣的事情,比如用不同预训练模型嫁接到一起,会是什么效果?我对这个答案很感兴趣。
现在面临的问题是:我们已经有较小且强的基座模型比如Mistral 7B,现在希望把它参数稍微扩大一点,以进一步提升模型能力,该怎么做?
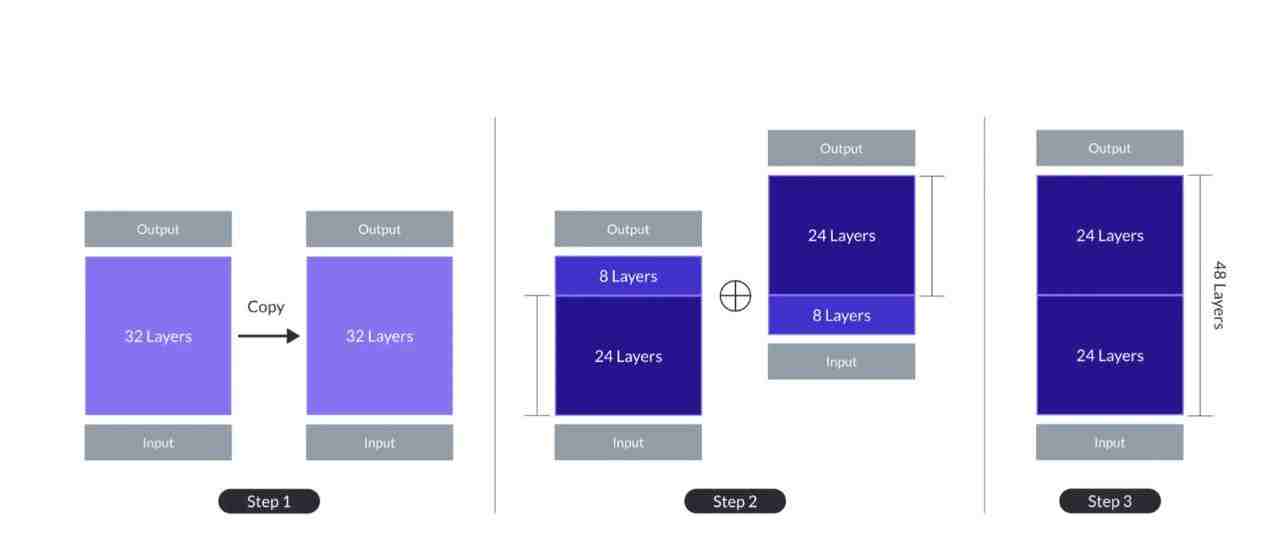
SOLAR 就是干这个的,问题是个好问题,SOLAR给自己的做法起了个很玄乎的名字,“Depth Up-Scaling”,其实做法很简单,就类似植物嫁接:训练好的Mistral 7B模型Transformer结构有32层,把Mistral的32层从第24层掰成两段(底层24层,高层8层),之后高层那段的8层上移,中间留出16层的参数空间,接下来把Mistral的第9层到25层这16层插入中间,通过这种嫁接形成48层的SOLAR模型,参数规模由Mistral 7B拓展到了10.7B(图2)。因为嫁接过程都是用的Mistral,所以是自我嫁接。
嫁接完之后效果如何?比Mistral差,这个很正常,因为嫁接的两个部分参数还没有融合成为一个整体,第25层附近是个断层。于是用了3Trillion[注1]的数据进行“继续预训练”,这步应该主要是对嫁接模型参数进行融合的(不过貌似用的数据量有点大,很多人有这个数据量和算力,都能自己from scratch训一个新模型了),形成了SOLAR-base基座模型。盲猜经过继续预训练后,掰断处25层和41层附近层的中间层模型参数变化是最大的,底层和最上层可能变化不大。
在继续预训练之后,又引入两个阶段:
一个是instruct tuning,这个环节采用开源instruct数据并改造出一个数学专用instruct数据,以增强模型的数学能力,这个环节对应常规的SFT阶段;
另一个是alignment tuning,也是开源+数学增强数据,采取DPO,这个环节对应传统的RLHF阶段。这样形成了SOLAR-chat版本。
从实验对比看,可以得到如下结论:
1、SOLAR-base基座模型和Mistral 7B 基座模型相比,6项测试任务中,只有数学测试GSM8K有大幅度提高(+18分),另外一个任务增加5分,其它四个任务增长都不太大(<3分),这些增长应该来自3T数据的继续预训练,数学能力增长巨大很可能在训练数据里增加了不少数学相关内容,但考虑到模型规模从7B增长到接近11B,数据量也比较大,其实这个指标增长一般般。
2、SOLAR-chat模型相对SOLAR基座模型测试效果有大幅提升(6项任务平均分+8分多),这说明大模型Post-training阶段是可以注入新知识的(之前也有不少研究可以证实这一点)。尤其夸张的是TruthfulQA,经过SFT和DPO后,单项任务增加了超过26分,单单这一项任务就把榜单平均分提高了接近5分,这说明如果想要刷榜,用少量Instruct数据就够了,成本并不高(不是说SOLAR刷榜,是说刷榜应该比较容易)。
3、SOLAR-base基座模型比其它基座模型(LLAMA2-70B/Yi-34B/Mixtra 8*7B)效果是不如的(SOLAR模型规模最小,所以不如也正常),但是也比较接近差不太多(平均分差1到4分之间),但是此类模型能够霸榜Huggingface,应该主要靠的是Post-Training阶段的数据质量好(OpenOrca/DeepFeedback/Alpaca-GPT4,都是最好的instruct数据)。这说明想要榜单排名好,高质Instruct数据少不了。只要找个最强的底座,你也可以作出最强模型,因为instruct成本并不太高。
总而言之,SOLAR这种,找个最强基座,通过自我嫁接模型还是有效的,当然建立真正的优势还是在Post Training阶段。不过,我觉得追求更好的嫁接方法、甚至是不同模型的相互嫁接,是个很有意思的方向。
注1:https://en.upstage.ai/newsroom/solar10b-huggingface-no1
这个PR稿早期版本说了继续预训练用了3Trillion的数据,不过现在的版本已经把这句话删掉了,从这个删除操作看,貌似透漏出了一些信息。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。