Deita:有限高质量数据在LLM的潜力是真的大
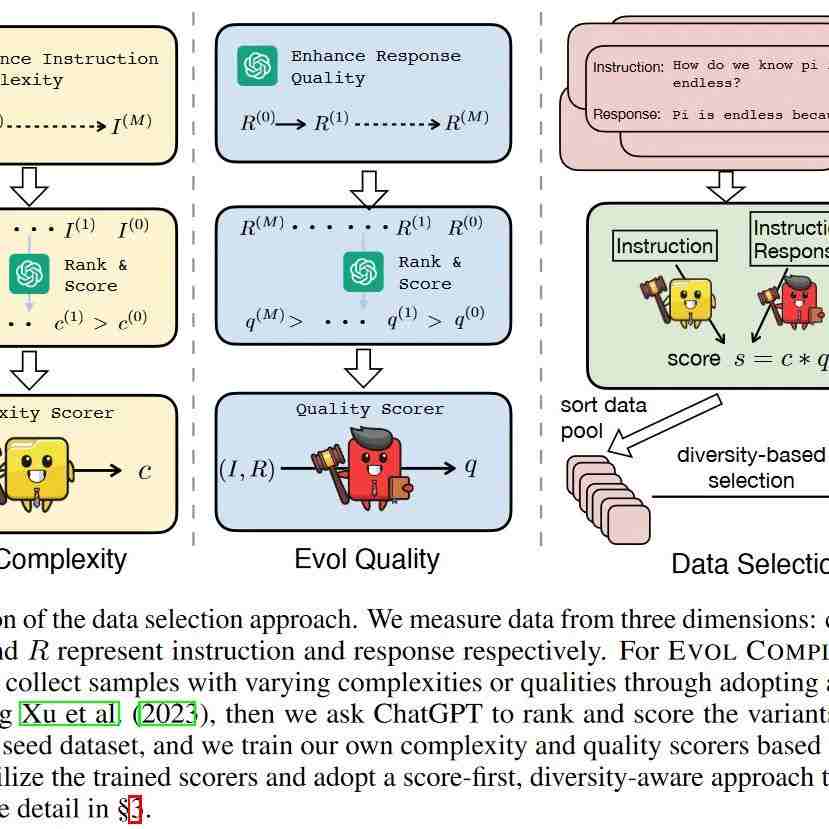
数据工程在指令调优中的有着关键作用。当选择适当时,只需要有限的数据就可以实现卓越的性能。然而,什么是良好的指令调优数据以进行对齐,以及如何自动有效地选择数据仍需研究。本文深入研究了对齐的自动数据选择策略。在复杂性、质量和多样性三个维度上评估数据。并提出DEITA(Data-Efficient Instruction Tuning for Alignment),一个从LLaMA和Mistral模型中微调的模型。
深度学习自然语言处理 原创
作者:cola
作者:cola
论文:What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning
链接:https://arxiv.org/abs/2312.15685
介绍
使LLM与人类偏好保持一致是模型准确理解人类指令并生成相关响应的必要步骤。LLM对齐的标准方法包括人工反馈的指令微调和强化学习(RLHF)。指令微调,或监督式微调(SFT),使用标注的教学数据细化预训练模型,通常作为RLHF之前的基础步骤,以促进模型的初始对齐。另一方面,RLHF利用强化学习来根据其生成的响应的注释反馈来训练模型。
一个相对较小的高质量数据集已被证明足以很好地对齐LLM,数据集大小从数十万到仅仅1000个样本。然而,在早期研究中,这些数据集的构建主要依赖于启发式自动化(例如从ChatGPT提取)或人工选择,并且仍然不清楚什么是用于指令微调的良好数据示例,以及如何系统地规划有效的数据集,以确保用最少的数据量实现有竞争力的性能。
本文试图定义用于指令微调的"好数据"的特征,并在此基础上以自动的方式进一步推动指令调优的数据效率。探索了各种方法,从三个关键维度定量评估数据样例:复杂性、质量和多样性。我们引入了EVOL复杂性和,然后用ChatGPT对其中的一小部分样本进行评分并训练一个评分者来预测这些分数,结果如图1所示。结合基于模型嵌入距离的多样性度量,设计了一种简单的策略,以从大型数据池中选择最有效的数据示例。
什么是好的数据对齐?
数据选择
形式上,给定一个大型指令微调数据池,其中表示以指令-响应对形式存在的单个数据样本。采用表示的选择策略,从中选择一个大小为的子集。是子集大小,与指令调优消耗的计算成比例相关,因此我们也将称为数据预算。我们定义一个指标来评估数据,并基于该指标选择数据样本。表示指令微调后的对齐性能,最优数据选择策略,数据预算满足: 在接下来的实证研究中,将探索不同范围的数据评估指标及其相应的数据选择策略,根据一定的指标选择并对其进行指令微调。
在接下来的实证研究中,将探索不同范围的数据评估指标及其相应的数据选择策略,根据一定的指标选择并对其进行指令微调。
实验设置
我们对单个指标进行对照研究以一次评估数据,过程为:
基于给定指标从数据池中选择一个子集 使用对预训练模型进行指令调优 评估所获得模型的指令遵循能力。
给定一个数据度量指标,本文保持选择算法尽可能简单,以保持其实用性(例如,选择具有最大复杂度分数的示例)。
数据池为了研究大型数据池中的数据选择,构建了两个具有不同属性的数据池:
:通过集成最先进的对齐LLM的训练数据集来构建。 :它模拟了可用数据池整体质量较低且冗余的场景。
表1总结了两个数据池的统计数据: 训练和评估我们假设数据预算为6K个样本。对所有训练使用相同的超参数。为了评估对齐性能,我们使用MT-Bench,这是一个具有挑战性的基准,通常被用于评估LLM的指令跟随能力。MT-bench由跨不同领域的多轮对话组成,如写作、推理、数学和编码。使用GPT-4作为裁判对MT-bench中的模型响应进行评分,发现与人类产生了很高的一致性。
训练和评估我们假设数据预算为6K个样本。对所有训练使用相同的超参数。为了评估对齐性能,我们使用MT-Bench,这是一个具有挑战性的基准,通常被用于评估LLM的指令跟随能力。MT-bench由跨不同领域的多轮对话组成,如写作、推理、数学和编码。使用GPT-4作为裁判对MT-bench中的模型响应进行评分,发现与人类产生了很高的一致性。
从复杂性的角度
人们通常认为,长的、难的和复杂的数据样本更有利于指令微调。我们系统地研究了各种指标,以评估数据样本的复杂性,并旨在确定对模型指令跟随能力贡献最大的复杂性概念。具体地,我们只考虑复杂度维度,并将选择策略复杂度定义为选择复杂度得分最高的个样例。
基线:
Random Selection:随机选择示例; Instruction Length:以指令长度作为复杂度的指标; Perplexity:使用预训练模型以零样本方式计算的答案的困惑度作为指标; Direct Scoring:直接提示ChatGPT对指令的难度和复杂度进行评分; Instruction Node:使用ChatGPT将指令转换为语义树,然后以语义树的节点数作为复杂度度量; Instag复杂度 IFD
直接评分和指令节点是不可扩展的,因为它们需要ChatGPT来注释整个数据池,而这是昂贵的。为了节省成本,我们首先从每个池中随机采样50K个示例,并应用这两个基线。
Evol复杂度:提出了一种基于进化的复杂性度量方法
EVOL COMPLEXITY。收集了一个小规模的种子数据集,,其中表示一个指令-响应对。对于每个指令样本,通过添加约束、深化、具体化和增加推理步骤等技术来提高复杂性。经过次迭代,我们得到一组的不同复杂度的指令。我们将设为5,总共得到6个变量。如图1左侧所示,然后我们让ChatGPT对这6个样本进行排序和评分,得到与指令相对应的复杂度分数。与直接评分不同,ChatGPT在一个提示框内给出全部6个样本。在获得小种子数据集上的ChatGPT分数后,我们使用分数来训练LLaMA-1 7B模型,以在给定输入指令的情况下预测复杂度分数。在多轮对话的情况下,我们分别对每轮进行评分,并将它们的总和作为最终得分。实验中,我们使用从Alpaca数据集随机抽样的2K个示例作为种子数据集。
结果:表2给出了使用各种复杂度指标从Xsota和Xbase中选取6K个数据样本的结果。实验结果表明,指令长度并不是对齐首选数据的良好指标。
从质量的角度
通常来说,提供准确、详细和有帮助的回答的LLM会受到人们的青睐。我们进行一项对照研究,以检查用于评估样本质量的各种指标。与EVOL复杂度相似,设计了一种选择策略,使我们能够根据不同的测量选择个具有最高质量分数的样本。基线:
随机选择。 响应长度 直接评分
Evol质量:以类似于EVOL复杂性的方式,引入EVOL质量来增强质量测量的分辨力。对于给定的数据样本,我们提示ChatGPT以一种进化的方式提高响应的质量。这主要包括增强有用性、增强相关性、丰富深度、培养创造力和提供额外的细节。经过次迭代后,对于相同的指令,我们获得了一组Rk的不同质量的响应,记为。与EVOL复杂度类似,我们将设置为5。如图1中间部分所示,我们指示ChatGPT根据回复质量对这些回复进行排序和评分,从而得到每个回复对应的质量分数。
结果: 表3给出了分别从和中选取前6K数据的实验结果。所提出的Evol质量方法始终表现出优越的比对性能。我们注意到,具有更高质量方差的池受指标的影响更大,这是很直观的,因为在这些池中存在许多低质量的示例,并将显著损害性能。
从多样性角度
作为一般原则,高级LLM应该善于处理来自人类的各种请求。因此,用于指令调优的数据需要保持最大的多样性。我们提出了一种简单而有效的策略来保持所选数据子集的多样性和简洁性。
设置: 提出一种迭代方法来保证所选数据的多样性。当对有多样性贡献时,迭代方法从池中逐个选择样本到所选数据集,该过程持续到达到预算或中所有都被枚举为止。
基线: 除了随机选择外,还进一步评估了Instag多样性,该多样性是迭代设计的,以确保所选数据集内的多样性。
结果: 表4展示了不同多样性策略的结果。将随机选择与其他两种确保多样性的策略进行比较,用随机选择的数据训练的模型的性能明显低于其他策略,这表明了多样性的关键作用。
DEITA
方法
分数优先,多样性感知的数据选择: 提出一种分数优先、多样性感知的数据选择策略。该策略纳入了一个新的Evol分数,通过将复杂性分数与质量分数乘以来结合复杂性和质量。
对于多轮对话,我们计算每个回合的分数,将它们相加以获得整个对话的最终分数。接下来,我们使用对中的所有样本进行排序,得到排序后的集合,其中表示Evol分数最高的样本。从开始,遵循REPR过滤策略,迭代地从依次选取数据,并丢弃冗余样本。通过整合Evol分数和REPR过滤器,该方法保证了结果数据集的复杂性、质量和多样性。我们的数据选择方法如图1的右侧所示,并在算法1中进行了总结。
实验设置
分别用6K和10K个样本训练DEITA模型。我们从数据池中选择数据样本。采用MT-Bench、AlpacaEval和Open LLM Leaderboard作为自动评估的基准。
实验结果
总结
在三个维度上进行了什么是好的对齐数据的研究:复杂性,质量和多样性。提出了自动数据选择的新方法,并在选择的数据样本上训练模型DEITA。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。