Q-Learning 在 Agent 的应用
作者:周舒畅,AI 工程师 来自:青稞AI
OpenAI 宫斗告一段落,现在到处都在猜 Q* 是什么。本文没有 Q* 的新料,但是会探讨一下 Q-Learning 在 Agent 方面的可能应用。
实现 tool 自动选择和参数配置
经典的文字模型我们已经很熟悉了:训练时,模型不停的预测下一个 token 并与真实语料比较,直到模型的输出分布非常接近于真实分布。
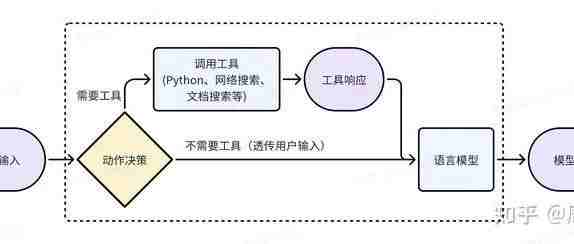
因为语言模型的局限性(比如搞不定大数计算),所以多家大模型公司走上了语言模型 + 工具的道路。比如 GPT4-turbo 就可以灵活调用网络搜索、Analysis(某种 Python) 这些 tools,来生成 tool response(即网络搜索结果、Python 执行结果),来帮助回答文字问题。
这就引入了一个决策问题,对于一个用户表达(utterance),到底要不要做网络搜索或者调用 Python 来帮助回答呢?如果决策错误,则结果不最优:
•工具的响应结果(tool response)可能无济于事甚至产生误导。比如有一些网络上的玩梗会影响模型对一些基本概念的知识。•工具的调用引入了额外的时间消耗。
因此,好好搞一些标注,训一个“动作决策”模型,能拿到第一波好处。这是有监督学习的思路。这里动作决策模型的输出,是具体的含参数的动作,比如调用网络搜索时,需要给出“是否搜索”和“搜索关键字”两部分信息。因此动作决策模型最好也是个大模型。这么搞的问题,是上限不高,受制于“动作决策模型”的标注质量,并且并没有直接优化“模型输出”,需要人绞尽脑汁来针对模型调整“动作决策模型”的标注来达到最优。比如对于网络搜索,当搜索引擎不同时,需要为“动作决策模型”使用不同的搜索关键字作为标注。
但从另一个角度,虚线框内的部分,仍然是一个文字进文字出的"模型",所以理论上可以用降低输出结果的困惑度的方法,按强化学习(RL)去训练这个复合了工具的“语言模型”。这里因为“动作的决策”不可微,所以来自“模型输出”的梯度只能用 RL 往回传。使用 RL 的具体步骤为:
•利用标注训练“动作决策模型”,使得整体有一定效果,即完成行为克隆(behavior cloning)这一启动步。•用强化学习继续训练整体,即复合了工具的“语言模型”。
Reward 由几项组成:
•利用<用户输入、模型输出>这样的成对数据(格式上接近 SFT 数据),计算困惑度•如果有用户偏好数据,也可以仿照 DPO 构造不同动作间的对比数据项。•把调用工具的时间和成本代价,折算进 Reward
实际,以上相当于使用了 Q-learning 的一个简单变体 DDPG,即假设存在函数映射μ使得μ(当前状态) = 最优工具调用动作与参数 如果不做这个假设,还是使用 Q(s, a) 的形式,则更接近 Reward Model 的搞法。
这里一个附送的好处,是可以做层级强化学习(hierarchical RL),就是说可以在工具调用中嵌套工具调用,比如一个网络搜索中嵌套网络搜索。因为上面在 Reward 里计入了“调用工具的时间和成本代价”,所以优化后的模型不太会出现盲目使用工具的情况。同时 RL 天然能处理多步决策,所以不特别需要研究“多轮交互时的动作决策模型标注“。
引入动态拆分任务
以上的 tool 调用,特别是网络搜索和 Python 执行,主要是为模型输出产生一些参考,因此本质上没有互斥性,就是说各个动作间没有强依赖。我们下面考虑一个动作间有强烈互相影响的场景:“任务拆分”。
当用户输入复杂到一定程度,我们需要引入拆分。静态拆分不需要特殊处理,但是如果希望子任务是跟据动态执行时获得的信息动态调整的,则要引入一个任务栈来进行管理。之前 AutoGPT 即引入了动态拆分子任务,基于语言模型实现了一定的 Agent 能力。但是一直以来 AutoGPT 并没有通过“训练”来加强能力的方法。下面,我们先把 AutoGPT 搬到 RL 里,一个搞法是借助 MCTS(蒙特卡洛搜索树)。
根结点是当前任务。各个叶子结点有 expandable 和 terminal 两个属性,其中 expandable 结点可以进一步被展开成子任务。注意
•MCTS 里 sibling 结点之间是或关系,选一即可。•MCTS 的 Policy Network 对应上文中的“动作决策”模型。•MCTS 里的 Value Network 可以用一大模型实现,描述当前结点的价值。比如发现当前子任务是死胡同时(如发现模型在用穷举法证明“偶数加偶数还是偶数”时)可以喊停。•上文的工具调用“模型”可以自然地嵌入到这里使用
子任务拆分没什么可用的数据,可以先靠语言模型天赋能力开始。训练数据可以选有明确答案的题,以答对为 Reward。MCTS 的形式特别适用需要回溯的任务(把某种任务分解推倒重来),比如数学计算。
(到这,我们得到了一个用 Q-learning 整体驱动的,自动学习如何拆任务调工具的框架,似乎和 Q* 公开的一些线索对上了一些。)
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。