EMNLP2023 | LLMs也许不擅长少样本信息提取,但可以为候选答案重新排序!
大型语言模型(LLMs)在各种任务上展现出卓越的能力。近期的研究抛出了一个挑战性的问题:在执行少样本信息提取(Information Extraction, IE)任务时,LLMs是否真正胜过了小型语言模型(SLMs)?这个问题看似简单,却引起了激烈的争论。不同的研究,依赖于不同的IE子任务、使用的数据集和实验设置,呈现了完全对立的视角和结论。这些分歧正是我们在这里要深入探讨的焦点。
今天介绍的这篇研究系统评估了LLMs在各种少样本IE任务上的竞争力,并提出了一个结合了LLMs和SLMs的新框架。让我们来一起了解一下吧🧐!
深度学习自然语言处理 原创
作者:Winnie
作者:Winnie
Paper:
Link:
Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples!
Link:
https://arxiv.org/pdf/2303.08559.pdf
进NLP群—>加入NLP交流群
前言
针对信息提取(IE)的研究有的强调LLMs是出色的少样本提取器,而有的却持反对意见。究竟什么导致了这些不同的观点呢?
最近的一篇研究进行了一番系统评估,探寻在多种少样本IE任务中LLMs是否真的表现优秀,并且这样的评估将对进一步的研究发挥关键作用。研究人员尝试回答以下几个问题:
LLMs在少样本IE任务中是否真的比SLMs更出色? 增加更多的注释是否能优化LLMs和SLMs的表现? 从财务和时间的角度来看,哪个模型更划算? LLMs和SLMs是否各自在处理不同类型的样本时有所擅长?
实验设置和初步结果
任务和数据集
带着这些问题,这篇研究进行了一场系统的探究,在三大IE任务上开展了实验——命名实体识别(NER)、关系提取(RE)和事件检测(ED),涉及以下八个相关的数据集:
命名实体识别:CONLL’03、OntoNotes 5.0 和 FewNERD; 关系抽取:TACRED 和 TACREV; 事件检测:ACE05、MAVEN 和 ERE。
小模型的选择
在实验中选择了RoBERTa-large作为基于抽取的方法的核心,选择了T5-large作为基于生成的方法的核心。调查了以下4种方法:
Fine-tuning (FT):仅需在SLMs上增加一个分类器头,即可为每个句子/词预测标签。 FSLS:目前在少样本NER任务中表现最佳的基于抽取的方法。 KnowPrompt:目前为止,在少样本RE任务中最顶尖的基于抽取的方法。 UIE:这是一种在少样本IE任务中表现出色的统一的基于生成的方法。
大模型的选择
大模型选择CODEX而不是InstructGPT。两者的规模和功能都非常接近,最近的研究表明CODEX在ICL方面的能力要么就是更好,要么至少与InstructGPT相当。此外,
使用API调用InstructGPT的费用是天文数字,而CODEX现在是免费的。
Vanilla ICL:简单地使用包含指示、示例和问题的提示。 ICL w. AutoCoT :从初始示例中引导出论据,然后在示例中使用这些论据作为推理步骤。 ICL w. DS :为测试示例寻找相似的训练示例,使用了一个无监督的方法,通过句子的嵌入来评估它们的相似度。 ICL w. SE:通过多次预测来评估每个测试示例。然后,通过多数投票整合这些预测,得出最终结果。
初步实验结果
下图展现了8个数据集上各模型的表现:
初步结果有以下发现:
当样本超级少时,LLMs确实能胜过SLMs,但加入更多样本后,SLMs开始发挥出色。 SLMs在简单样本上表现亮眼,但LLMs更擅长处理难度较大的样本。
初步的结果展现出LLMs只有在注释非常稀缺的情况下才能超过SLMs。而当提高样本数量时(比如数量增至几百),SLMs的表现开始大幅领先。这一现象可能与ICL的某些局限性有关。由于ICL的输入长度的最大限制,只有少数可用样本能够作为示范来提示LLMs。此外,提示中更多的样本并不一定能带来更好的性能提升。
但是!LLMs在处理难度较大的样本时却展现出了出色的能力,这可能因为这些复杂样本(例如,置信度较低的样本)需要更多的外部知识或复杂推理,而这恰恰超出了SLMs的能力范围,但对LLMs来说不在话下。
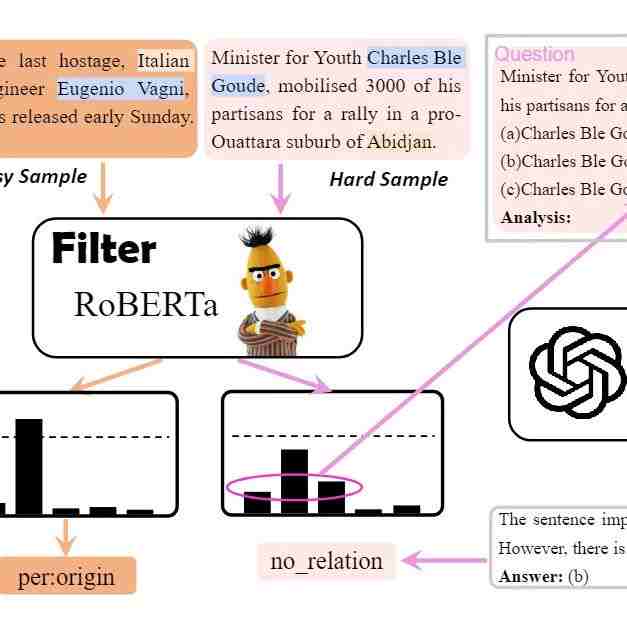
Filter-then-rerank
基于这些发现,研究人员设计了Filter-then-rerank框架,融合了SLMs和LLMs的优势。简单说,就是让SLMs先进行筛选,再让LLMs做决策。
仅通过对0.5% - 13.2%的样本进行重新排序,Filter-then-rerank框架就超过了先前的最先进方法,平均提高了2.1%的F1分数。
结语
在进行的广泛实证研究中,研究团队对三个任务的八个数据集上的大型语言模型(LLM)和小型语言模型(SLM)进行了深入分析。研究揭示了一个显著的现象:尽管LLM携带了巨大的潜力,但由于任务格式、有限的样本容量和模型的庞大规模,它们未能成为理想的少镜头信息提取工具。相较于SLM,LLM引入了显著的时间和财务成本。
令人注目的是,研究团队发现LLM能在相当大的程度上协助SLM,尤其是在重新排列和纠正硬样本方面。基于这些发现,他们提出了一个自适应Filter-then-rerank范式。这种方法精巧地利用了LLM和SLM各自的优势,同时巧妙地避开了它们的局限性。
在这种新方法中,首先利用SLM进行初始样本的过滤,然后仅在挑战性的样本上部署LLM进行重新排序。这种策略不仅在多个小样本IE任务上实现了平均F1增益达2.1%的显著效果,而且极大地减小了因调用LLM API而产生的延迟和预算成本。
该团队的研究呈现了一个探索和平衡的故事——一方面是利用更强大的模型来提高性能,另一方面是在实际应用中保持经济效益和实用性的考虑。通过精明地整合两种模型的优点,他们为研究者和开发者在小样本学习领域打开了一扇新的大门,同时保留了务实的观点。在未来的研究中,探索这一范式的其他应用和扩展将是一个引人入胜的研究方向。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。