全球首颗忆阻器芯片,清华团队突破了什么? | 陈经
近日,清华大学集成电路学院教授吴华强团队研制出一颗新型芯片,能高效“片上学习”不少人工智能任务。这颗芯片的核心元器件是“忆阻器”,架构是“存算一体”,创新点在于能耗只有常规系统的3%,研究水平很高,2023年9月14日在线发表在《科学》上。
美国芯片产业出口管制的背景下,芯片话题自带热度,清华的这个高水平芯片成果,引发了不少人的兴趣,希望看到中国芯片技术的新突破,但又感觉看不懂,这里我们需要关注“存算一体”、“忆阻器”以及“片上学习”这三个点,以及它们的协同一体化。
日常的编程,大多是在软件层面进行,其中“软硬件结合”、“嵌入式编程”指的是开发者能够对传感器、相机之类的硬件外设进行连接、SDK调用,但不需要知道硬件细节。
再深入,编程可以延伸到操作系统、指令集层面,这要求开发者对整个计算系统更为了解,用汇编语言之类的办法或者绕开普通编程与界面工具的限制,直接对系统进行深层调用,进而提高效率,但这还是在软件层面,思维都是基于0-1数值逻辑的。
继续深入,就涉及到到芯片层面。由于芯片和系统架构决定了计算系统的特性,有一定实力的公司会直接使用芯片进行开发,甚至自研复杂的芯片。目前阶段,制造芯片与传统IT产业01逻辑有区别,更像是一个在硅片上以纳米尺度绣花的物理化学过程,它的基础是半导体元器件。所以,芯片设计,是IT业真正“软硬兼修”的连接环节。它一头要理解指令集、操作系统、程序逻辑、人工智能等软件知识,一头又要和元器件、芯片架构等底层硬件知识打交道。
近年来,由于神经网络、深度学习的流行,业界在芯片设计层面对神经网络的研究也很热门。清华的忆阻器芯片,就是把以上各类知识综合到一起,深入理解之后的创新。在这个层面,如何存储、更新数据,都需要深入思索,并作出创新。
01 存储的逻辑
一个计算过程,不一定是0-1数值逻辑的,而是还原到物理信号在器件之中传导的层面来理解,涉及电流、电压、功耗等物理数值。
例如,芯片中一种存储数据的元器件叫SRAM,有电就能保持数据不变,基本单元由6个晶体管(Transistor)构成,即6T。
作为对比,清华新型芯片用来存储数据的元器件叫“忆阻器”(Memristor,是Memory和Resistor,即内存和电阻的组合词),其“秘密武器”基本单元(Cell)由晶体管和忆阻器构成,比如1T1R、2T2R,即一个晶体管、一个忆阻器或者两个晶体管、两个忆阻器。
把这些元器件的特性弄清楚了,就能看明白清华的忆阻器芯片怎么回事。
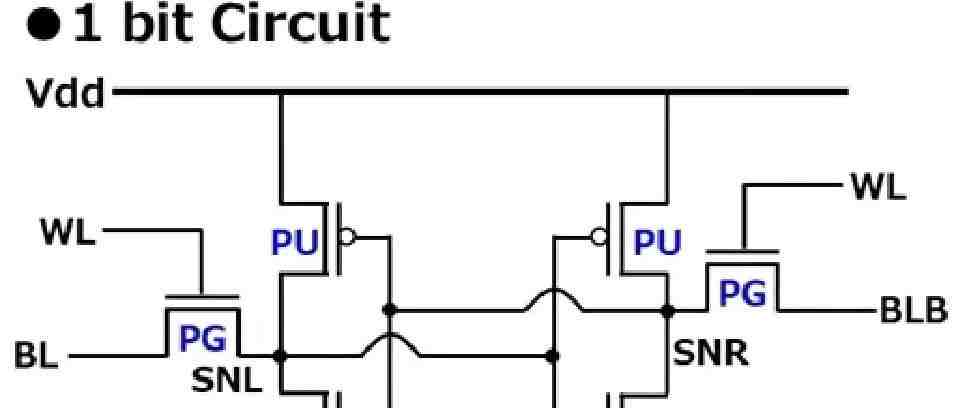
图为存储1个bit的6T SRAM结构
上图就是一个典型的6T结构SRAM的基本单元的电路图,其中上方两个PU代指PMOS晶体管,下方两个PD代指NMOS晶体管,其导通状态由gate——PU与PD边上的竖线——的高低电平控制。PMOS晶体管是低电平导通,高电平阻断。NMOS晶体管导通状态正好相反,即低电平阻断,高电平导通。
两个PU和两个PD,这4个晶体管存储了1个bit的信息,由SNL与SNR两点的高低电平状态代表,其中任意一个点与电源Vdd导通,就是高电平,与接地GND导通,就是低电平。在这个架构中,SNL与SNR状态必然相对,一高一低。
假设SNL与VDD导通,SNL是高电平,此时SNR会与GND导通,SNR是低电平,在这个前提条件下:
● 左PU连到SNR低电平导通,右PU连到SNL高电平阻断(PMOS特性)
● 左PD连到SNR低电平阻断,右PD连到SNL高电平导通(NMOS特性)
此时,就有一个“电源VDD-左PU-SNL”的通路(SNL与VDD导通,与高电平的状态相符),以及“SNR-右PD-GND”的通路(与SNR的低电平状态相符),把它叫状态1。
假设SNL与GND导通,SNR与Vdd导通,SNL为低电平,SNR为高电平。在这个前提条件下类似推理,导通的电路变成“VDD-右PU-SNR”(所以SNR是高电平),以及“SNL-左PD-GND”(所以SNL是低电平),叫它状态0。
4个晶体管就是这样存储一个bit的,要点是四个晶体管组成两个“反相器”交叉连接。
SRAM的基本单元是6T结构,包含6个晶体管,前面只提到4个,剩下两个就是NMOS的PG晶体管。
WL是字线(Word Line),一般是低电平,让两个NMOS的PG晶体管阻断,让存储切断外界连接保持数据。WL设成高电平,PG就导通了,外界通过BL与BLB两个位线(Bit Line)进行读写。
读操作时,BL与BLB都设置成1,与SNL和SNR连接“分压”。SNL为0时,BL的电压会下降,BLB的电压不变,二者产生一个“电压差”,经过信号放大输出,就读出了0。SNL为1,BL与BLB会产生相反方向的电压差,读出为1。
写操作时原理类似。写入1,就将BL设置成1,BLB设置成0,反相器受到影响,SNL会变成1,SNR变成0,存入bit数据1。写入0时,BL为0,BLB为1,反相器也会相应调整状态。
一个现象是,SRAM的读操作相对简明,反相器的状态不变,不管如何BL与BLB总会产生电压差,0和1的反向区别明显,输出不会搞混。但是写操作就要复杂一些,反相器的状态会从0变1(或者1变0),这有一个过程。
可以看出,即使是最基本的一个bit的存储,基于CMOS晶体管的元器件架构也不简单(C是Complementary互补,指PMOS和NMOS配合)。它需要接上电源才能保持存储,读写有一些特性,各类存储的读写速度差异很大。实际应用,需要冯·诺依曼体系架构,即程序指令和数据一起存储在CPU之外的内存里,经总线调入CPU中执行。
图为冯·诺依曼瓶颈,CPU和内存之间的总线,成了“内存墙”,限制了CPU计算性能的发挥
02 冯·诺依曼瓶颈与忆阻器
近年来,因深度学习而超级火爆的神经网络计算中,人们发现了“冯·诺依曼瓶颈”。
在神经网络概念中,Neurons是神经元节点,而神经元之间的连接叫“突触”(Synapses),其连接的数量远多于神经元节点数,CPU的高速缓存中可以放下神经元的数据,突触数据就放不下了,只能放在内存中。
然而,随着神经网络规模变得极为庞大,在训练与推导中,需要频繁更新神经元与突触的状态,导致海量数据在内存与CPU之间搬运,往往是算得快、搬得慢,经低速总线(Bus)的数据通信成为架构瓶颈。虽然有多CPU(或者说Processor)并行的方案,但由于模型越来越大,会导致CPU之间的通信需求爆炸,所以并不能彻底解决问题。
用传统计算机的CPU架构进行神经网络运算,能耗高、速度慢,GPU用超级多的计算核心加速,能解决慢速的问题,但能耗不低,需要散热。英伟达告诉人们,价格也不便宜——核心难点就是数据在处理器芯片与分离的内存(off-chip memory)之间搬运太多,占了训练的大部分能耗与时间。云计算可以解决部分问题,堆资源能耗先不管了,但是不少边缘计算(edge computing)任务,如手机平板,是对能耗敏感的。
面对这种问题,一个自然的想法是“存算一体”,让CPU直接抓取存储,算了又存回,消除中间的总线瓶颈。
“存算一体”的概念显然需要纳米级的新型半导体元器件支持,一个看上去很好的候选是忆阻器交叉阵列(Memristor Crossbar)。
Memristor就是忆阻器,它的出现有些离奇。1971年伯克利的蔡少棠根据理论推导提出,在电阻、电容、电感之外,可能存在第四种基本元器件,取名忆阻器,其基本特性是电阻随着电流改变,电流消失了,电阻停留不动,直到反向电流将电阻推回原值。这能简单实现高电阻1低电阻0的存储状态,而且尺寸小、能耗低,掉电也还是保持存储。如果能用它当计算机的基本存储单元,电脑关机再开机,瞬间就还原了,掉电不损失信息。
这种听上去性质很优秀的元器件,长期只是理论探讨,没有现实对应的物质。突破一直要等到2008年5月《自然》报导,惠普Stanley Williams团队真的找到了有忆阻器性质的物质:二氧化钛。
惠普的发现是,将一块极薄的二氧化钛分成两半,一半正常。另一半“掺杂”,少了一些氧原子带正电,电流通过时电阻较小。当电流再流向正常的一半时,在电场影响下缺氧的“掺杂物”也往这边游移,整体的电阻就降低了。反过来,电流从正常侧流向“掺杂”侧时,电场又会把“掺杂物”住回推,电阻就增加了,这正是理论中忆阻器的特性。
之后这方面的研究开始兴起,主要应用就是寻找冯·诺依曼之外的新架构,如神经形态处理器(Neuromorphic Processor),它有仿生学的优点,功耗低、自学习、自修复、鲁棒性等等,比神经网络的思想更为深刻。
神经网络架构简单模仿人类神经元连接,功耗高、堆砌规模,而基于忆阻器的神经形态处理器,更为深入地模拟人类神经元的运作机制,表现出来的计算特性更接近人。
03 忆阻器交叉阵列与神经网络
现在我们可以如介绍6T的SRAM结构那样,对神经形态处理器的基本元器件忆阻器交叉阵列进行解释了。
忆阻器突触原理图
上图为忆阻器最基本的突触连接图,一前一后两个神经元(实际应用中还是用CMOS晶体管来实现),中间的突触连接经过一个忆阻器。两个神经元发出尖峰电流经过忆阻器,两边的峰值差异,会让忆阻器的电阻值升高或者降低。
忆阻器交叉阵列
上图为忆阻器应用的元器件“忆阻器交叉阵列”的示意图,这个结构就如6T SRAM一样可以存储数据,进行读写操作,但远不止一个bit,功能要强大得多。它分为交叉的上下两层导线,每个交叉点中间都有一个忆阻器连接。BP、CNN等神经网络数据结构,网络是从输入层到中间层(隐藏层)再到输出层,一层层前后连接的,熟悉的人一看就明白,这个Crossbar很象是用一个矩阵存储了两层之间的全连接权重。
BP神经网络结构,一个隐藏层
简单介绍,神经网络分为“前向推导”和“反向传播训练”两个过程。
以清华团队论文中用的,MINST数据集中的28*28的手写数字图像识别为例,神经网络节点是3层的,784*100*10,输入层是784(它等于28*28)个节点,中间层是100个节点,输出层是10个节点,对应0-9。应用时是前向推导,784个输入节点的数值乘上连接权重,中间层某结点的所有784个连接乘数相加,就是这个节点的状态数值。这相当于用784维的向量乘以784*100的矩阵,得到100维的向量。再用中间层的向量,乘以100*10的权重矩阵,得到10维的向量。
例如某种理想情况下,输出层0-7的节点上数值为0,8节点上的数值为1,9节点的数值为0,那么识别结果就是数字“8”。
应用之前,要根据标注好的样本反复训练,才能实现成功的前向推导。这就是著名的,几乎所有神经网络架构都用的反向传播(Back Propagation)训练。
开始时,权重是乱的,单步训练对标准样本的输入,先前向推导得到输出层向量,但结果可能是错误的。如对样本“8”,算出来输出层9节点的数值为1,其它节点数值为0。将输出层的数值与样本数值比较,算出一个误差向量(8和9节点有误差了),将这个误差向中间层、输入层反向传播,用“梯度下降”的原则更新经过的连接的权重。
多次训练后,前向推导的结果就与样本数值基本一致了,也就是误差接近于0了,网络就有模式识别功能了。
在常规理解中,权重数据是以矩阵形式存在常见的内存的,存算是分离的。忆阻器交叉阵列用忆阻器来存储权重,它也有具体的读写过程。与SRAM相比,一个特别的优点是,不用通电,数据就以电阻的形势保存在忆阻器里了。而且,忆阻器交叉阵列具有“存算一体”的特性。
训练其实就是更新突触连接的权重,最终目标是将误差降到最小,其实里面一堆权重具体数值人们也看不懂了,但是最后的状态输出是看得懂的。忆阻器交叉阵列的训练也是如此,反向传播去更新交叉点的电阻值,具体值人们并不关心,只要减小误差就行了。
权重更新时,不是一下变一大步(开始误差大,步子可以大点),而是会小步小步地挪,逐渐减小误差。对电阻值的更新也是如此,有一个精细微调的感觉。
而且交叉阵列有一个很大的优点,计算时天然有并行功能。神经网络运算主要就是在干矩阵乘法,CPU和GPU优化就是对矩阵忙活。Crossbar可以将所有节点的电阻并行读出,用欧姆定律和基尔霍夫定律——进入某节点的电流总和等于离开节点的电流总和——稍加处理,就能并行加速矩阵乘法。
实践说明,忆阻器交叉阵列真的可以实现神经网络的功能,可以模拟CNN、RNN等多种神经网络结构,以及现在最流行的深度神经网络DNN。如CNN的卷积操作,可以用交叉阵列里的一行来实现。
上面介绍的交叉阵列只是简单的结构示意,用于存储权重。
研究者们应用忆阻器交叉阵列时,要外接软件算法、处理器、内存,来真正实现BP反向传播训练算法,需要很多周边电路。它本身不能算是“神经形态处理器”,是在传统计算机架构里,加入了一个有特色的存储结构,展现了潜力。它需要传统的CMOS晶体管以及CPU、内存配合,也有一些缺陷。
一个重大缺陷是,电阻的写入需要验证(write verification),反复地读写,因为忆阻器作为元器件并非完美。这让训练过程不是那么顺畅,额外开支很大,能耗不低,并没有摆脱“冯·诺依曼瓶颈”。
清华团队开发的忆阻器芯片架构叫STELLAR,有两个忆阻器交叉阵列数组,大一些的是2T2R的,有1568*100个忆阻器,在神经网络模型中代表784*100的权重矩阵。小一些的是1T1R的,有100*20个忆阻器,代表100*10的权重矩阵(注意不是100*20)。两个忆阻器交叉阵列组合成了784*100*10的一个三层神经网络结构,用于完成一些小型的人工智能算法任务。
这两个Crossbar各有特性。大的是2T2R的,里面的权重是“off-chip”离线训练好的,然后上传到交叉阵列里面,它的特点是可以并行计算矩阵乘法,节点数多,展现了“存算一体”的优良特性。小的是1T1R的,规模小,但是后面附带权重更新逻辑,可以在芯片内训练更新网络权重,展现了“片上学习”(on-chip learning)的功能。
两个忆阻器交叉阵列结合CMOS芯片制造工艺,真的造出来了,上图是2T2R Crossbar的局部切片图。这个生产工艺良率接近100%,切片图像清晰。忆阻器元器件的制造应该不是难题了,材料也从二氧化钛变成了几种物质复合,元器件性能应该还有提升空间。
芯片上面也是有许多CMOS晶体管的,有辅助核心模块的周边电路,处理神经网络前向推导、反向传播学习的逻辑。还有ADC转换,将两个忆阻器交叉阵列的模拟物理量输出转换成数字。应用这颗芯片,其实就是用里面两个权重矩阵的推理与训练功能。
这芯片可以独立地作为一个神经网络运作,也可以在外面再加上一些层,作为网络的一部分。如实现CNN网络时,前面需要在外接电脑上实现一些卷积层,用这两个矩阵当最后的全连接层输出。
测试与训练时,需要外接的设备对这芯片传入数据、接收结果。整个测试体系搭建起来后,就是一个完整的系统,可以对芯片的性能进行完整的测试。测试的神经网络功能相对简单但能展现特性,例如,输出是10个节点,正好对应0-9的10个数字,可以用来测MINST数据集里的手写数字识别。
芯片架构叫STELLAR,是“sign- and threshold-based learning”的简称,指的是训练中的创新。如上图,W1是大的交叉阵列,输入向量X进来,乘以矩阵W1,再用激活函数(Activation function)ReLU变换——其实很简单,负数变0,正数不变——变成向量Y1。Y1再乘以矩阵W2,再ReLU变换,成为输出向量Y2。Y2与训练样本T比较,生成误差向量E。
清华团队的创新是,对W2的训练,先将Y1、Y2、E三个向量的符号抽出来,实施更好的权重更新办法。其出发点是,一个权重是用一正一负两个忆阻器存储的,可以选择性根据符号,一列一起更新。这是深入思考反向传播的权重更新算法,结合元器件架构,实现了忆阻器潜在的并行功能。如图,权重更新分为SET和RESET两个步骤,SET步骤只对正的符号更新正Cell,对负的符号更新负Cell,而RESET正相反。这样SET和RESET分别都可以按列并行加速了。
另一个创新是,在误差向量E上加一个threshold,预先将一些微小的误差过滤掉,这样给出的符号向量,训练性能更优。这个threshold是可配置的,对不同的网络模型可以设置相应的过滤门限值,这应该是结合SET和RESET特性的进一步优化。
另一个实验是,事先将识别数字0、2-9的9个数字的网络训练好,784*100*10的网络权重转移到忆阻器芯片里(正好全用上了),故意不训练数字1。之后再把1的样本放上来,对后一个忆阻器交叉阵列进行训练,只要100个样本,1也能认了,识别率从7%提升到93%,老的数字识别率只是从95.3%微降到93.2%,这说明芯片能适应新类型的学习样本。
还有语音识别演示,女声提前训练好,男声在片上学习,也能学成。还通过ResNet网络的例子,展示了架构的可扩散性。这些人工智能任务,以及网络架构,按现在的深度学习进展来看,都是较为基础的(都还算是实用),但是用忆阻器芯片来演示展现特性,是文章的创新。
在字符识别测试时,清华团队还用48天进行了重复测试,结果是稳定的。这说明忆阻器芯片里的权重是稳定的,这是芯片能实用的重要特性。
可以看出,这颗忆阻器芯片是真的有“存算一体”的特性。矩阵权重就在芯片里,计算过程也是在芯片里完成的,而且还有神经形态处理器的仿生特性。
通过STELLAR架构并行加速等创新,相对专用集成电路(ASIC)加速的常规系统,清华团队实现了35倍的能耗效率,这是芯片架构的突出亮点。STELLAR架构里,不需要高能耗的write verification,在能耗效率上非常有优势。而且这是一颗相对完整独立的忆阻器芯片,较为系统地展示了忆阻器在神经网络计算方面的潜力,对于边缘计算有突破性意义。
通过以上的介绍,我们再看新闻通稿的内容,就会明白多了(以下为通稿原文):
● 全球首颗全系统集成的、支持高效片上学习(机器学习能在硬件端直接完成)的忆阻器存算一体芯片,在支持片上学习的忆阻器存算一体芯片领域取得重大突破。
● 该芯片有望促进人工智能、自动驾驶、可穿戴设备等领域发展。
● 芯片包含支持完整片上学习所必需的全部电路模块,成功完成图像分类、语音识别和控制任务等多种片上增量学习功能验证,展示出高适应性、高能效、高通用性、高准确率等特点,有效强化智能设备在实际应用场景下的学习适应能力。
● 相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的3%,展现出卓越的能效优势,极具满足人工智能时代高算力需求的应用潜力,为突破冯·诺依曼传统计算架构下的能效瓶颈提供了一种创新发展路径。
通过以上的讨论也能看出,清华忆阻器芯片主要还是在性能探索层面,大规模进入工业实用还需要进一步优化。因为基于常规芯片的人工智能系统已经大规模应用了,深度学习取得突破后,识别性能相当好,一些应用成本很低。
目前来看,忆阻器芯片能够承载的网络规模还是有限,识别的准确率只是90%多,离100%还有不小的距离,和工业应用的高可靠性标准还是有点差距。一些复杂应用使用了规模很大的深度神经网络DNN,忆阻器交叉阵列只能在里面占部分环节,整个应用还是需要以传统的冯·诺依曼结构为基础。
也就是说,简单的神经网络应用,传统的架构已经够好,能耗和成本都够低。复杂的应用,传统架构是有“冯·诺依曼瓶颈”,能耗高很需要改进,忆阻器芯片现阶段还不足以在复杂应用中充分发挥作用。但是,忆阻器芯片确实展现出了并行加速与高效存储的特性,这让人很感兴趣,相信未来会有更多进展。
如需联系作者或转载文章,请发信至[email protected]
■ 扩展阅读
■ 作者简介
陈经
中国科学技术大学计算机科学学士,香港科技大学计算机科学硕士,科技与战略风云学会会员,《中国的官办经济》作者。
风云之声
科学 · 爱国 · 价值
关键词
数据
网络
特性
架构
交叉阵列
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。