IJCAI2023 | 实现跨域NER的协同领域前缀微调策略
论文题目:One Model for All Domains: Collaborative Domain-Prefx Tuning for Cross-Domain NER
本文作者:陈想(浙江大学)、李磊(浙江大学)、乔硕斐(浙江大学)、张宁豫(浙江大学)、谭传奇(阿里巴巴)、蒋勇(阿里巴巴达摩院)、黄非(阿里巴巴达摩院)、陈华钧(浙江大学)
发表会议:IJCAI2023
论文链接:https://www.ijcai.org/proceedings/2023/0559.pdf
代码链接:https://github.com/zjunlp/DeepKE/tree/main/example/ner/cross
来自:ZJUKG
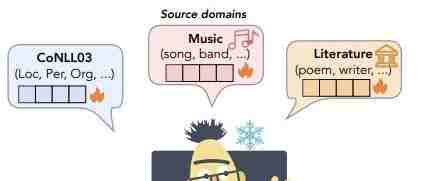
图1:One Model for All Domains示意图
一、引言
跨域命名实体识别(Cross-domain NER)是知识图谱和自然语言处理领域中的一项重要任务,其面临着数据稀缺和资源限制的挑战。为了解决这些问题,先前的研究提出了一些方法,包括增加辅助模块、设计新的模型结构以及对源领域和目标领域数据进行训练,例如NER-BERT [1]通过在目标领域数据上进行进一步预训练来提升模型在目标领域数据集上的性能。另一些方法则建立了源领域和目标领域数据标签之间的关系,以帮助标签信息的迁移;例如目前CrossNER[2]测试基准上的SOTA模型LANER [3]设计了专门的模块来利用领域之间的语义关联,以提高模型在跨领域任务中的性能。然而,现有的跨域NER的发展存在一些局限性,主要有三个方面:(1)之前的方法通常依赖于具有不同实体类别的各个领域的特定于任务的架构,从而限制了模型的实用性;(2)大多数当前方法的计算效率较低,并且需要调整 PLM 的所有参数,最终会为每个域提供一个全新的 NER 模型,这会大大消耗计算资源;(3)对于跨域NER而言,领域间的知识迁移至关重要,而之前的方法通常只能从一个源领域迁移到目标领域,缺乏从多个源领域迁移到目标领域的能力。
基于以上问题,本篇论文提出了CP-NER模型,其主要贡献体现在以下三个方面:(1) 本文重新定义了NER任务,将其定位为基于域相关的文本生成指导器(text-to-text generation grounding domain-related instructor)。这种新定义的形式能够激发PLM模型生成与NER任务相关的通用知识,并能够处理不同实体类别,而无需修改PLM参数以适应不同领域,为实现一个适用于所有领域的单一模型打下了基础。(2) 本文提出了协同域前缀调优(collaborative domain-prefix tuning)的方法,旨在将知识迁移到跨领域NER任务中。本文应该是首次提出将多个源领域的知识进行迁移的工作,对于跨领域信息抽取领域具有重要贡献。(3) 本文所提出的方法在CrossNER基准测试中,通过从单一源领域迁移到目标领域的设定下,取得了最先进的性能。此外,进一步的实验结果表明CP-NER能够高效地利用少量参数进行知识迁移,并且对所有领域保持一致的模型框架。
图2:CP-NER模型框架
二、方法
2.1 任务定义
给定句子,NER的目的是从长度为的句子中抽取出所有的实体,我们定义第个实体为为,其中指的是实体类型,和指的是实体的边界下标。source和target domain的数据分别表示为和。本文既考虑One Source for Target,又包括Multiple Source for Target设定。
本研究将跨领域命名实体识别(NER)任务处理为序列生成任务,并采用了固定参数的T5模型。模型的输入由以下三个部分组成:
最终模型的输出可表示为:
本文使用基于领域相关指令的文本生成具有两个优点:(1)指导T5模型生成特定领域的命名实体序列,无需更改模型结构即可适应新的领域;(2)激发预训练语言模型在处理不同领域NER任务时的潜力,为引导冻结的预训练语言模型通过前缀微调生成实体序列奠定基础。
2.4 协同领域前缀微
2.4.1 领域前缀预热
为了灵活使用不同领域中包含的前缀知识,本研究首先使用领域语料对前缀进行训练。对被固定的T5模型的所有层设置新的初始化训练参数矩阵,最终第层的prefix来自参数矩阵,训练过程中使用训练集对每一层的参数矩阵进行优化以得到最终的prefix,具体的优化目标如下:
其中采用了softmax函数来将输出映射到词汇表上的向量分布,表示第层中第个标记的中间向量。通过预热得到的领域控制器作为最终结果。
2.4.2 双查询领域选择器
当源领域和目标领域的实体类型相同时,直观上利用具有相似语义信息的共享标签来适应目标领域是有益的。此外,领域前缀可以提供领域特定的语法风格和知识。基于上述考虑,本研究提出了双查询领域选择器,通过标签相似度和前缀相似度两个方面来确定不同源领域对目标领域的重要程度。Entity Similarity:本文使用T5模型对实体标签词进行嵌入来计算实体相似度。对于第个源领域的标签语义编码和目标领域的标签语义编码,标签相似度表示为:
Prefix Similarity:给定源领域的前缀和目标领域的前缀,计算它们之间的余弦相似度:
第个源领域与目标领域的总相似度根据实体相似度和前缀相似度计算如下:
为了灵活地融合源领域和目标领域的前缀知识,本文提出了领域前缀的内在协作方法。通过对源领域和目标领域前缀进行加权平均,可以得到融合的前缀表示:
其中,表示从多个领域聚合的矩阵。我们按照公式4的目标函数更新,同时保持不变。
Remark2: 从最优控制(OC)的角度来看,前缀调整可以被形式化为寻找针对特定领域的预训练的最优控制。而我们的协作领域前缀调整可以解释为寻找闭环控制,以利用来自多个源领域的知识,增强目标领域的命名实体识别性能。
三、方法
本实验使用CrossNER数据集进行评估,对比的基准模型包括DAPT、COACH、CROSS-DOMAIN LM、FLAIR、BARTNER、LST-NER、LANER和LightNER。为了保证公平性,所有基准模型都使用了基础级别的预训练语言模型(PLM)。
如表1所示,CP-NER在不同目标领域上的性能全面超过了SOTA模型LANER,F1-score平均提升了3.56%。尤其值得注意的是,在science和music两个数据集上,性能提升分别达到了6%和8%。实验结果充分证明了CP-NER技术在CrossNER基准测试中的出色表现。
三、方法
本研究使用CP-NER模型来处理跨领域NER任务,该模型利用领域前缀的协同调优来更好地利用多个领域的知识。实验证明,CP-NER模型在CrossNER基准测试中的性能全面超过了一系列基准模型和SOTA模型。本文提出的CP-NER方法实现了"one mode for all domains"的目标,在实际应用中具有很大的潜力。未来我们可以进一步研究如何进一步提升CP-NER模型的性能,探索更有效的领域前缀协同调优策略。此外,我们也可以考虑将CP-NER模型应用于其他自然语言处理任务,如命名实体识别(NER)和关系抽取(RE),以拓展其适用范围。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。