大模型知识增强trick--关键信息记得放两端
来自:NLP日志
提纲
1 简介
2 实验介绍
3 实验结论
4 总结
参考文献
进NLP群—>加入NLP交流群(COLING/ACL等投稿群)
1 简介
通过知识增强的方式,往大模型输入中添加相关的知识文档可以有效提高大模型事实类问答的准确性,缓解模型幻视的问题。但是关于大模型是如何利用这些长文本的,斯坦福大学对此做了进一步研究,发现了把相关信息放在开头或者结尾,模型准确性更高,而把相关信息放在中间的话会得到最糟糕的效果。同时,发现了随着知识文档长度的增强,模型准确性也会相应下降,即便是支持长输入的大模型。
2 实验介绍
研究人员选用了多个开源或者闭源模型,包括MPT-30B-Instruct, LongChat-13B(16K), GPT-3.5-Turbo, GPT-3.5-Turbo(16K)等模型,在多文档问答跟一个人工合成的key-value检索任务上进行测试。在多文档任务中,模型prompt包括三个部分,任务描述,问题以及对应的从搜索引擎检索得到的多个文档,从而让模型从中寻找问题相关信息并用于生成回复。在key-value检索任务中,模型prompt也包括三个部分,任务描述,一个字符串的json类(包括k个key-value,每个key跟value都是人工生成的,都是唯一的),以及一个key的字符串(这个key需要包含在前面提及的json类中),让模型去寻找第三部分的key所对应的value。两个任务的具体示例可以见下图,这里有人可能会有疑问,为什么还要单独做一个key-value检索任务呢?这是因为多文档问答任务中,模型是有可能利用自身内部的知识回答问题,而并非来自于外部的知识增强,这会有实验结果有所干扰,而key-value检索任务的数据都是人工合成的,模型想要准确生成回复,就只能从外部的知识中去寻找。
图1:多文档问答示例
图2:key-value检索任务示例
3 实验结论
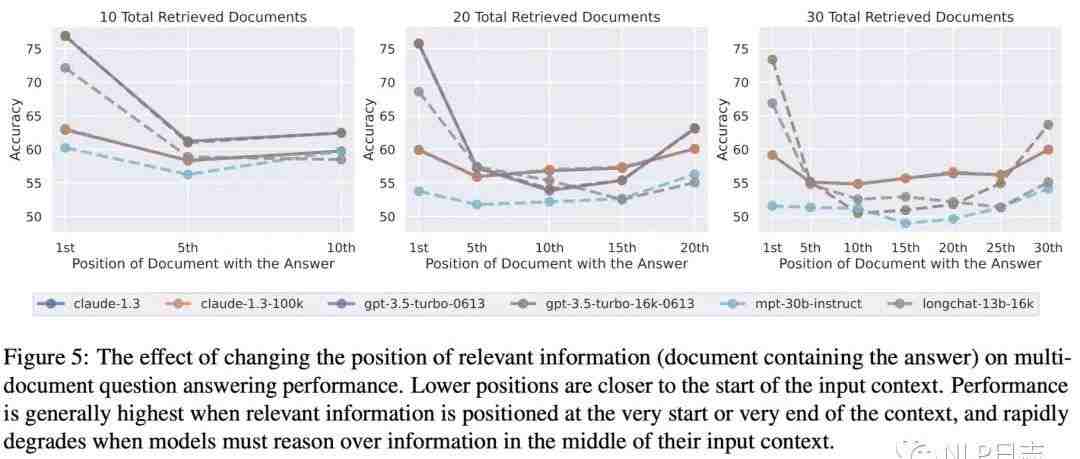
a) 当相关信息放在两端时模型准确率最高,模型准确率跟相关信息位置呈现一个U形图,并且左端明显高于右端,当相关信息位于中间位置时,模型回复效果最差,甚至不如不使用知识增强的方式。也就是说模型更善于把握住开始跟结束位置的信息,而容易忽略掉中间内容。换言之,目前大模型不能有效地利用整个窗口里的文本进行推理。
图3:多文档问答准确率的上限(只给正确文档)跟下限(不给任何文档)
图4:模型准确率跟正确文档位置关系
b) 随着输入长度增加,模型准确率也会对应下降。这里的模型准确率是相关文档在各个位置的平均准确率,所以下降是合理的。例如总共就召回5个文档,无论相关信息在哪个文档里模型效果都会比较好,整体效果就比较好了,但是如果召回30个文档,当相关信息在10-20个文档中时模型准确率就很差了,所以平均准确率也会受此拖累也变差。
图5:模型平均准确率跟召回文档数的关联
c) 扩展输入长度的大模型并没有优于原始的模型,在不超过长度限制条件下,GPT-3.5-Turbo跟GPT-3.5-Turbo(16K)表现接近。
d) 不考虑相关信息所处的位置,直接利用检索模块召回相应文档,会发现模型准确率会随着召回文档数的增加而有所提升。召回文档数一开始增加时,由于召回率的提升,会带来模型准确率的快速增加,但到后期时,即便召回率有所提升,但是由于输出长度的急剧增加也会带啦不少损耗,所以后期的准确率曲线会趋于平缓。
图6:召回文档数对于模型准确率的提升
4 总结
知识增强确实可以提高大模型回复的准确性,但并不是一味增加召回文档数从而提高召回率怎么简单,也需要考虑到相关信息的位置。如果能把关键信息置于正确位置,可以事半功倍,反之,则有可能画蛇添足。在实际使用过程中,我们需要在召回文档数跟模型准确率直接寻找一个合适的位置,既能保证大模型的效果,又能兼顾大模型成本。
关于大模型更能关注到开始跟结尾位置的信息,而忽略了中间的信息,这里面的原因文中并没有尝试去解释。我认为这种现象跟人类的阅读习惯是一致的,大模型学习的是人类的思维方式,训练语料也都来源于真实世界,对于人类而言,当看一篇长文章时,往往一开始会很认真,但是会渐渐消磨了耐性,中间部分会粗略过下,等到发现快要看完时,兴致会有所回升,就会再认真些许。整个阅读过程,看起来很符合这里提及的大模型的U形曲线。
参考文献
1. Lost in the Middle: How Language Models Use Long Contexts
https://arxiv.org/pdf/2307.03172.pdf
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。