大模型知识蒸馏概述
平均阅读时长为 5分钟
进NLP群—>加入NLP交流群
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。而大模型压缩主要分为如下几类:
剪枝(Pruning) 知识蒸馏(Knowledge Distillation) 量化(Quantization) 低秩分解(Low-Rank Factorization)
本文将讲述当前大模型蒸馏相关的一些工作。
知识蒸馏简介
知识蒸馏是一种机器学习模型压缩方法,它用于将大型模型(教师模型)的知识迁移到较小的模型(学生模型)中。
知识蒸馏(KD),也被称为教师-学生神经网络学习算法,是一种有价值的机器学习技术,旨在提高模型性能和泛化能力。
它通过将知识从复杂的模型(称为教师模型)转移到更简单的模型(称为学生模型)来实现这一点。KD背后的核心思想是将教师模型的综合知识转化为更精简、更有效的表示。
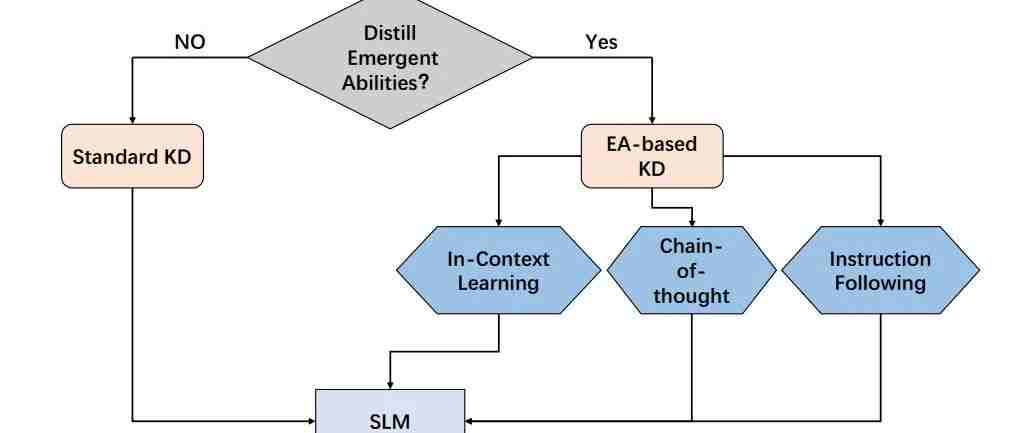
本文,我们将概述利用LLM作为教师的蒸馏方法。根据这些方法是否将LLM的涌现能力(EA)提炼成小语言模型(SLM)来对这些方法进行分类。因此,我们将这些方法分为两个不同的类别:标准 KD 和基于 EA 的 KD。为了直观地表示,下图提供了LLM知识蒸馏的简要分类。
标准知识蒸馏
Standard KD旨在使学生模型学习LLM所拥有的常见知识,如输出分布和特征信息。这种方法类似于传统的KD,但区别在于教师模型是LLM。比如:MINILLM 和 GKD。
MINILLM (论文:Knowledge Distillation of Large Language Models)深入研究了白盒生成LLM的蒸馏。它观察到最小化前向 Kullback-Leibler 散度 (KLD) 的挑战(这可能会导致教师分布中不太可能的区域出现概率过高,从而在自由运行生成过程中导致不可能的样本)。为了解决这个问题,MINILLM 选择最小化逆向 KLD。这种方法可以防止学生高估教师分布中的低概率区域,从而提高生成样本的质量。
GitHub:https://github.com/microsoft/LMOps/tree/main/minillm 教师/学生模型:GPT2、GPT-J、OPT、LLaMA 来源:清华和微软研究院
GKD(论文:GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models) 探索了自回归模型的蒸馏,这里白盒生成 LLM 是一个子集。该方法确定了两个关键问题:训练期间的输出序列与学生在部署期间生成的输出序列之间的分布不匹配,以及模型under-specification,其中学生模型可能缺乏与教师分布相匹配的表达能力。GKD 通过在训练期间对学生的输出序列进行采样来处理分布不匹配,它还通过优化替代散度(逆向 KL)来解决模型under-specification的问题。
来源:Google DeepMind
基于涌现能力的知识蒸馏
基于 EA 的 KD 不仅仅迁移 LLM 的常识,还包括蒸馏他们的涌现能力。
与 BERT(330M)和 GPT-2(1.5B)等较小模型相比,GPT-3(175B)和 PaLM(540B)等 LLM 展示了独特的行为。这些LLM在处理复杂的任务时表现出令人惊讶的能力,称为“涌现能力”。涌现能力包含三个方面,包括上下文学习 (ICL)、思维链 (CoT) 和指令遵循 (IF)。如图三所示,它提供了基于EA的知识蒸馏概念的简明表示。
上下文学习蒸馏
ICL 采用结构化自然语言提示,其中包含任务描述以及可能的一些任务示例作为演示。通过这些任务示例,LLM可以掌握并执行新任务,而无需显式梯度更新。
In-context Learning Distillation: Transferring Few-shot Learning Ability of Pre-trained Language Models 论文中引入了 ICL 蒸馏,它将上下文小样本学习和语言建模功能从 LLM 转移到 SLM。这是通过将上下文学习目标与传统语言建模目标相结合来实现的。
为了实现这一目标,他们在两种小样本学习范式下探索了 ICL 蒸馏:元上下文调优 (Meta-ICT) 和多任务上下文调优 (Multitask-ICT)。
在 Meta-ICT 中,语言模型使用上下文学习 objectives 在不同任务中进行元训练。这使其能够通过上下文学习来适应看不见的任务,从而扩展其解决问题的能力。
另一方面,Multitask-ICT 使用 ICL objectives 和 target 任务中的一些示例对模型进行微调。随后,它采用上下文学习来对这些任务进行预测。
比较这两种范式,Multitask-ICT 表现出优于 Meta-ICT 的性能。然而,它在任务适应过程中确实需要更多的计算资源,使其计算加强。
来源:哥伦比亚大学
思维链蒸馏
与 ICL 相比,CoT 采用了不同的方法,它将中间推理步骤(可以导致最终输出)合并到提示中,而不是使用简单的输入输出对。
MT-COT (论文:Explanations from Large Language Models Make Small Reasoners Better) 旨在利用 LLM 产生的解释来加强小型推理机的训练。它利用多任务学习框架使较小的模型具有强大的推理能力以及生成解释的能力。
来源:加州大学圣塔芭芭拉分校、腾讯人工智能实验室、微软等
Fine-tune CoT (论文:Large language models are reasoning teachers)更进一步,通过随机采样从 LLM 生成多个推理解决方案。训练数据的增强有助于学生模型的学习过程。
GitHub:https://github.com/itsnamgyu/reasoning-teacher 来源:韩国科学技术院
Fu 等人的研究(论文:Specializing Smaller Language Models towards Multi-Step Reasoning)发现语言模型多维能力之间的权衡,并提出微调指令调整模型。他们从大型教师模型中提取 CoT 推理路径,以提高分布外泛化能力。
来源:爱丁堡大学、艾伦AI研究所
Hsieh 等人的研究(论文:Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes)使用 LLM 论据作为在多任务框架内训练较小模型的额外指导。
来源:华盛顿大学、谷歌 GitHub:https://github.com/google-research/distilling-step-by-step 学生模型:T5 教师模型:PaLM
SOCRATIC CoT(论文:Distilling Reasoning Capabilities into Smaller Language Models)训练两个蒸馏模型:问题分解器和子问题求解器。分解器将原始问题分解为一系列子问题,而子问题求解器负责解决这些子问题。
来源:苏黎世联邦理工学院计算机科学系
DISCO(论文:DISCO: Distilling Counterfactuals with Large Language Models)引入了一种基于 LLM 的全自动反事实知识蒸馏方法。它通过工程化的提示使用 LLM 生成短语扰动,然后通过特定于任务的教师模型过滤这些扰动,以提取高质量的反事实数据。
来源:洛桑联邦理工学院自然语言处理实验室、艾伦人工智能研究所 GitHub:https://github.com/eric11eca/disco
为了形成更好的监督,SCOTT(论文:SCOTT: Self-Consistent Chain-of-Thought Distillation)通过对比解码从大型 LM(老师)那里得到支持标准答案的论据,这鼓励老师生成只有在考虑答案时才变得更加可信的Token。为了确保可信的蒸馏,我们使用教师生成的基本论据来学习具有反事实推理目标的学生 LM,这可以防止学生忽略基本论据而做出不一致的预测。
来源:南加州大学计算机科学系,亚马逊公司 GitHub:https://github.com/wangpf3/consistent-CoT-distillation
指令遵循蒸馏
IF 致力于仅基于阅读任务描述来增强语言模型执行新任务的能力,而不依赖于少数样本。通过使用一系列以指令表示的任务进行微调,语言模型展示了准确执行以前未见过的指令中描述的任务的能力。
例如,Lion (论文:Lion: Adversarial Distillation of Closed-Source Large Language Model)利用LLM的适应性强的特点来提高学生模型的表现。它提示LLM识别并生成“hard”指令,然后利用这些指令来增强学生模型的能力。这种方法利用了LLM用途广泛的特性来指导学生模型的学习,以解决复杂的指令和任务。
来源:香港科技大学 GitHub:https://github.com/YJiangcm/Lion 学生模型:LLaMA-7B 教师模型:ChatGPT(GPT-3.5)
结语
本文简单讲述了目前大模型知识蒸馏方向的一些工作,在大模型参数量越来越大的今天,该方向(通过相对较小量级的模型蒸馏大模型的知识)的研究显得格外有意义。
加下方微信(id:DLNLPer),
备注:昵称-学校(公司)-方向,进入技术群;
昵称-学校(公司)-会议(eg.ACL)
,进入投稿群。
方向有很多:LLM、模型评测、CoT、多模态、NLG、强化学习等。
记得备注呦
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。