顶刊TIP2022!领域迁移Adaboost,让模型“选择”学哪些数据!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达作者:郑哲东 | (源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/593571554论文:https://zdzheng.xyz/files/TIP_Adaboost.pdf备份:https://arxiv.org/abs/2103.15685作者:Zhedong Zheng,Yi Yang代码:github.com/layumi/AdaBoost_SegWhat:- “难”样本对于Domain Adaptation 语意分割模型来说特别重要,比如 Cityscapes中 “train”这种类别出现的场景比较少,自然在“Cityscapes”上的火车预测也特别差。这就导致,每次训练,模型的抖动特别大, 有时候不同epoch(如data shuffle顺序不同等因素),就会在测试集上 就有 较大的performance gap。
- 所以考虑到 难样本挖掘,一个很自然的想法就是 用Adaboost, 这个是我的人脸检测老本行中一个最work的策略。具体可见(郑哲东:AdaBoost 笔记) 大概意思是,每次根据之前的“弱分类器”决定下一轮 我们应该学什么。在人脸检测上,就是根据前一个分类器分错的样本,做针对性的优化。
- 故本文基于Adaboost 的概念,做了一个很简单的事情,针对 Domain Adapation 这个任务 做 Adaptative Boosting。根据训练过程中的snapshot(可以看成弱分类器),来针对性“选择”难样本,提高他们采样到的概率,如下图。

- 其实思路是 还是按照以前模型训练方式,有source domain上的 Segmentation loss 和 一些正则 Regularization (比如 adversarial loss 拉近两个 domain的gap)
- 通过这种方法 我们可以每轮训练一个模型,得到weak models (这都是在一次训练中的),我们通过 weight moving average的方式 得到 Student Aggregation 也就是 “臭皮匠们组成的诸葛亮”。
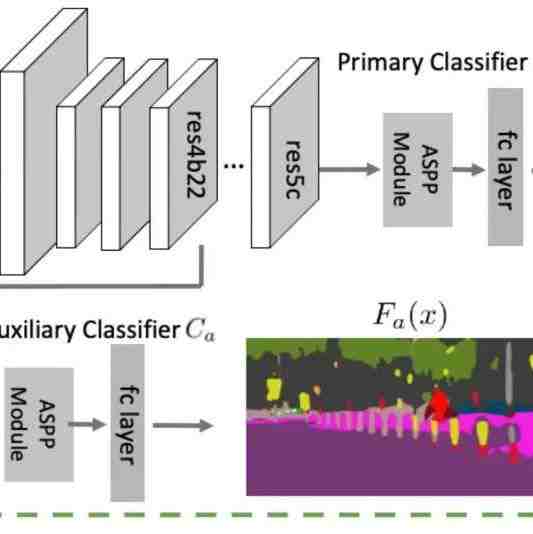
- 我们根据“诸葛亮” 主分类器和辅助分类器意见不同的样本来估计 样本难度。如下图,


 实验:
实验:- 要注意的是:单纯使用 难样本采样策略,是不能保证单个模型能训练得更好的。因为就像Adaboost一样,我们让模型overfit难样本,为了获得一个互补的模型,这个单模型在单独使用的情况下,不一定能更好。我们得到了一个类似的结论,单用难样本只能到 48.1,但结合了模型组合 可以到 49.0 。同时如果只能模型组合嫩到 48.4左右的 准确率。








点击进入—>CV微信技术交流群 CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF目标检测和Transformer交流群成立扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群 ▲扫码或加微信号: CVer222,进交流群CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码或加微信号: CVer222,进交流群CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人! ▲扫码进群
▲扫码进群▲点击上方卡片,关注CVer公众号 整理不易,请点赞和在看
阅读原文 作者:郑哲东 | (源:知乎)编辑:CVer
“难”样本对于Domain Adaptation 语意分割模型来说特别重要,比如 Cityscapes中 “train”这种类别出现的场景比较少,自然在“Cityscapes”上的火车预测也特别差。这就导致,每次训练,模型的抖动特别大, 有时候不同epoch(如data shuffle顺序不同等因素),就会在测试集上 就有 较大的performance gap。
所以考虑到 难样本挖掘,一个很自然的想法就是 用Adaboost, 这个是我的人脸检测老本行中一个最work的策略。具体可见(郑哲东:AdaBoost 笔记) 大概意思是,每次根据之前的“弱分类器”决定下一轮 我们应该学什么。在人脸检测上,就是根据前一个分类器分错的样本,做针对性的优化。
故本文基于Adaboost 的概念,做了一个很简单的事情,针对 Domain Adapation 这个任务 做 Adaptative Boosting。根据训练过程中的snapshot(可以看成弱分类器),来针对性“选择”难样本,提高他们采样到的概率,如下图。
其实思路是 还是按照以前模型训练方式,有source domain上的 Segmentation loss 和 一些正则 Regularization (比如 adversarial loss 拉近两个 domain的gap)
通过这种方法 我们可以每轮训练一个模型,得到weak models (这都是在一次训练中的),我们通过 weight moving average的方式 得到 Student Aggregation 也就是 “臭皮匠们组成的诸葛亮”。
我们根据“诸葛亮” 主分类器和辅助分类器意见不同的样本来估计 样本难度。如下图,
要注意的是:单纯使用 难样本采样策略,是不能保证单个模型能训练得更好的。因为就像Adaboost一样,我们让模型overfit难样本,为了获得一个互补的模型,这个单模型在单独使用的情况下,不一定能更好。我们得到了一个类似的结论,单用难样本只能到 48.1,但结合了模型组合 可以到 49.0 。同时如果只能模型组合嫩到 48.4左右的 准确率。
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载ECCV 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。