获取豆瓣电影 top250 的内容(附完整代码)

功能需求
需要对豆瓣网站https://movie.douban.com/top250?start=0的top250的电影名,导演,评分和经典语录等信息进行爬取下来并且保存到excel文档中。
分析网页:查看网页源码 ,F12
1、通过网页分析,发现第一页的请求地址如下
2、第二页的请求地址如下:
以此类推。发现如下规律:每次请求发现 url 参数 start 都是以 25 数量网上进行依次递增,因此进行网页请求的时候我们可以通过循环和控制参数的值(有 10 页循环 10 次,start 从 0 开始依次递增到 225
接下来开始代码实践
首先,我用到第三方库 requests 库
通过以下代码,会发现返回状态码是 418,这个是因为该网站有反爬机制 因此我们需要注意,请求的时候,带上请求头,且请求头的部分参数是必备的,cookie、请求代理等参数,保险起见,可以把请求头的所有参数都带上
因此我们需要注意,请求的时候,带上请求头,且请求头的部分参数是必备的,cookie、请求代理等参数,保险起见,可以把请求头的所有参数都带上 带上所有请求头参数后,会发现返回状态码为 200,此时表示网页请求成功了,可以开始准备获取网页的内容
带上所有请求头参数后,会发现返回状态码为 200,此时表示网页请求成功了,可以开始准备获取网页的内容 使用请求到的返回内容进行 text 属性转换,发现报错 UnicodeEncodeError: 'gbk' codec can't encode character '\ufffd' in position 3: illegal multibyte sequence,发现是编码格式的问题
使用请求到的返回内容进行 text 属性转换,发现报错 UnicodeEncodeError: 'gbk' codec can't encode character '\ufffd' in position 3: illegal multibyte sequence,发现是编码格式的问题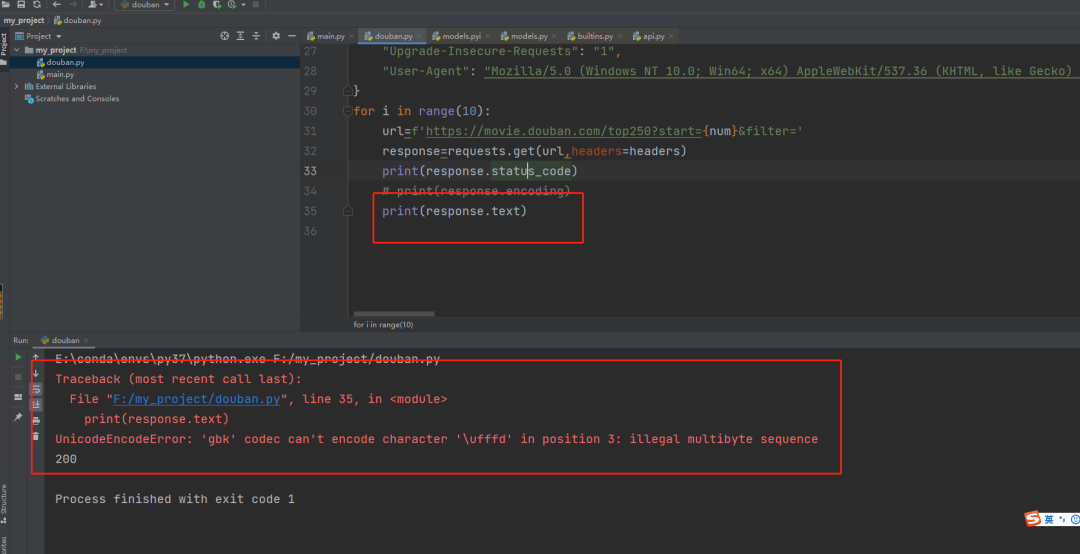 查看当前 response 的编码格式是 utf-8,按道理编码格式没问题了,情况如下:
查看当前 response 的编码格式是 utf-8,按道理编码格式没问题了,情况如下: 猜测是不是编码格式要改成 gbk,因此,我们考虑是不是需要将 utf-8 编码格式改成 gbk 编码格式。改完后发现还是报错,解决方法无效。
猜测是不是编码格式要改成 gbk,因此,我们考虑是不是需要将 utf-8 编码格式改成 gbk 编码格式。改完后发现还是报错,解决方法无效。 最后发现是编码器也有问题,把编译器编码格式需要改成 utf-8
最后发现是编码器也有问题,把编译器编码格式需要改成 utf-8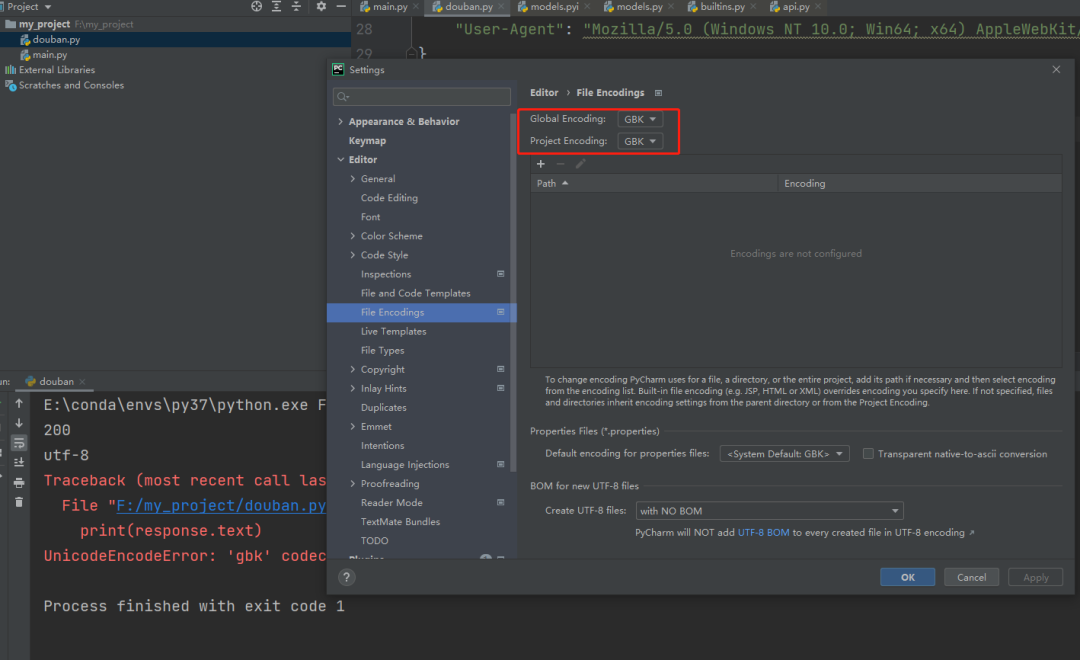 再次运行代码,发现不会报错,但是还是乱码
再次运行代码,发现不会报错,但是还是乱码 最后找到根本原因,请求的可接收编码格式出现问题,需要把可接收编码格式注释掉/把,br 字符删掉,即可解决该乱码问题。SUCESS!!!!!!
最后找到根本原因,请求的可接收编码格式出现问题,需要把可接收编码格式注释掉/把,br 字符删掉,即可解决该乱码问题。SUCESS!!!!!!
 思考为什么,br 删除后可以正常:注意看下,服务器接收到前端请求的时候,编码格式是 br 格式压缩,因此,我们会发现,把,br 压缩格式删掉也是能得到正常的源码的。
思考为什么,br 删除后可以正常:注意看下,服务器接收到前端请求的时候,编码格式是 br 格式压缩,因此,我们会发现,把,br 压缩格式删掉也是能得到正常的源码的。 再把这个问题总结一下:普通浏览器访问网页,之所以添加"Accept-Encoding" = “gzip,deflate,br”,那是因为,浏览器对于从服务器中返回的对应的 gzip 压缩的网页,会自动解压缩,所以,其 request 的时候,添加对应的头,表明自己接受压缩后的数据。
再把这个问题总结一下:普通浏览器访问网页,之所以添加"Accept-Encoding" = “gzip,deflate,br”,那是因为,浏览器对于从服务器中返回的对应的 gzip 压缩的网页,会自动解压缩,所以,其 request 的时候,添加对应的头,表明自己接受压缩后的数据。
而在我们编写的代码中,如果也添加此头信息,结果就是,返回的压缩后的数据,没有解码,而将压缩后的数据当做普通的 html 文本来处理,当前显示出来的内容,当然是乱码了。
接下来,开始进行网页源码解析,提取自己想要的数据,有非常多的库能解决这个问题,比如常见的第三方 lxml 库,第三方库 beautifulsoup 等,beautifulsoup 我比较少用,为了突破下思维,本次我就使用 beautifulsoup 进行解析。注意一下:导入是从 bs4 导入
复习一下解析器的知识,
解析器 使用方法 条件
bs4 的 HTML 解析器 BeautifulSoup(mk, 'html.parser')
安装 bs4 库
lxml 的 HTML 解析器 BeautifulSoup(mk, 'lxml')
pip install lxml
lxml 的 XML 解析器 BeautifulSoup(mk, 'xml')
pip install lxml
html5lib 的解析器 BeautifulSoup(mk, 'html5lib')
pip install html5lib
我使用第一种方式,第一参数表示要解析的内容,第二个参数表示,解析方式。
注意:如果使用别的方式,注意要提前下载第三方库。
开始提取各类信息
先拿到电影名称,有 2 种方式,一种使用 text 属性值获取,也可以使用 string 属性值获取,任选其一,即可。使用 find_all 函数对所有符合条件提取到列表中,但是发现有我不需要的电影名称信息(比如/开头的名称),在网页查看源码会发现 class 属性值里面除了 title 值还有别的值,因此会把所有这个也提取到列表中
 下面问题就是需要把所有符合我想要文本内容使用 if 语句过滤一下
从源代码看,字符串如果是以空格空格\开始就过滤掉,但是使用以下语句会发现还是没有过滤掉
下面问题就是需要把所有符合我想要文本内容使用 if 语句过滤一下
从源代码看,字符串如果是以空格空格\开始就过滤掉,但是使用以下语句会发现还是没有过滤掉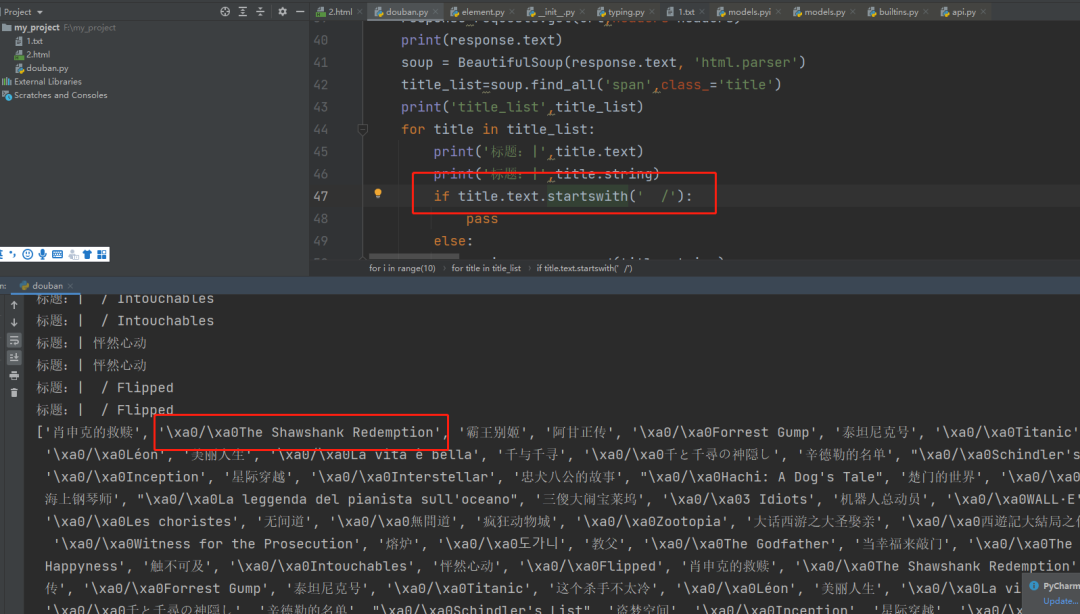 因此,考虑使用打印出来的内容放到 startswith()函数里面去,如下
SUCESS!!!!!!
因此,考虑使用打印出来的内容放到 startswith()函数里面去,如下
SUCESS!!!!!! 接下来就把剩余所要的各类信息,以此类推的方式进行提取,但是发现怎么多了和少了,导演名称多了、影评少了。分析原因 1、查找的方式不够准确或者代码写的有问题 2、网页内容可能部分信息是缺失的,所以导致会出现比 250 还少的情景。
接下来就把剩余所要的各类信息,以此类推的方式进行提取,但是发现怎么多了和少了,导演名称多了、影评少了。分析原因 1、查找的方式不够准确或者代码写的有问题 2、网页内容可能部分信息是缺失的,所以导致会出现比 250 还少的情景。 经过分析,我们可以看到每个 li 标签就是一个小盒子(有 250 个小盒子),我们可以使用选择器方法进行层层筛选比较合理,当不存在的时候影评的内容的时候,就写入空的字符串,这样输出列表长度,就一定是 250 了,这样对我们检查准确性有帮助,当然你想写入空字符串也是可以的。
经过分析,我们可以看到每个 li 标签就是一个小盒子(有 250 个小盒子),我们可以使用选择器方法进行层层筛选比较合理,当不存在的时候影评的内容的时候,就写入空的字符串,这样输出列表长度,就一定是 250 了,这样对我们检查准确性有帮助,当然你想写入空字符串也是可以的。
上 代码
影评信息提取,SUCESS!!!!!!
 导演信息提取
导演信息提取 出现个意外报错,
requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
原因是:requests 发生了太多的重定向,已超过了 30 个。解决办法:把 cookie 修改改成最新的 cookie 就可以了。
出现个意外报错,
requests.exceptions.TooManyRedirects: Exceeded 30 redirects.
原因是:requests 发生了太多的重定向,已超过了 30 个。解决办法:把 cookie 修改改成最新的 cookie 就可以了。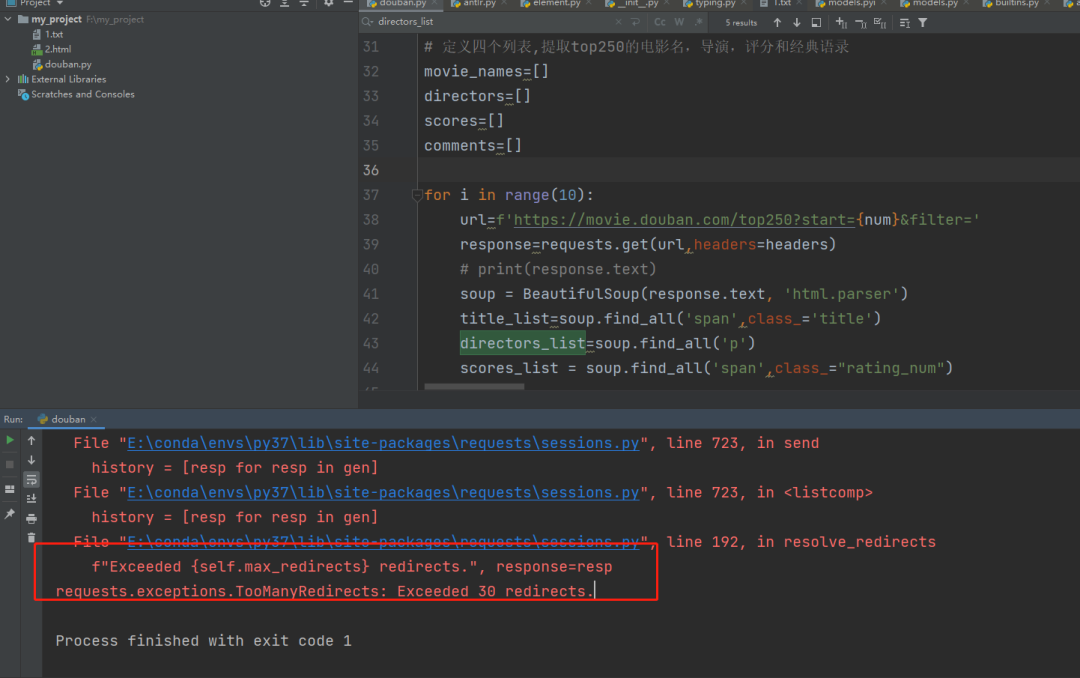 最后一步,就是把这四列数据写入 excel 表格中,如下
使用 openpyxl 库,可支持.xlsx 后缀的 excel 表格,数据正好是 250 条数据。
最后一步,就是把这四列数据写入 excel 表格中,如下
使用 openpyxl 库,可支持.xlsx 后缀的 excel 表格,数据正好是 250 条数据。
try:
woorbook = openpyxl.load_workbook('信息.xlsx') # 存在打开
except Exception as e:
woorbook = openpyxl.Workbook() # 不存在就创建
sheet_name = woorbook.active
# 写入表头信息
my_title = ['电影名称', '导演', '评分', '评论']
sheet_name.append(my_title)
# 把电影名称写入第一列
for i in range(4):
if i==0:
for j, value in enumerate(movie_names):
sheet_name.cell(row=j + 2, column=i + 1, value=value)
if i==1:
for m, value in enumerate(directors):
sheet_name.cell(row=m + 2, column=i + 1, value=value)
if i==2:
for n, value in enumerate(scores):
sheet_name.cell(row=n + 2, column=i + 1, value=value)
if i==3:
for o, value in enumerate(comments):
sheet_name.cell(row=o + 2, column=i + 1, value=value)
woorbook.save('信息.xlsx')
woorbook.close()
最后附上完整的代码
# -*- coding: utf-8 -*-
# @Time : 2022/10/23 22:36
# @Author : cxt
# @Email : [email protected]
# @File : douban.py
# @Software: PyCharm
# 大概就是我需要爬取豆瓣电影top250的电影名,导演,评分和经典语录,把爬出来的内容保存为xlsx文件.
import openpyxl
import requests
from bs4 import BeautifulSoup
num = 0
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": 'll="118200"; bid=if7o-u5rpLw; _vwo_uuid_v2=D42BF118CA0CFBF33DE8D94435B90D555|8925bd17a31f8b7058e92337ffcb5018; __gads=ID=4dc7fd39de72a642-22ad1e0315d700a5:T=1666015161:RT=1666015161:S=ALNI_MYaFQPlEV9oanRAwTzfwojslL387A; dbcl2="263719242:cdu+tcWOYSA"; __utmz=30149280.1666020617.4.3.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmz=223695111.1666020617.3.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0; ct=y; __yadk_uid=YjGciSzXayZFWFJ5s9NkPcW5sv8CoJWw; ck=c-17; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1666700334%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; __utma=30149280.1094459905.1662650904.1666623522.1666700335.9; __utmc=30149280; __utma=223695111.1141913362.1662650905.1666623522.1666700335.8; __utmc=223695111; __gpi=UID=00000b6478645c88:T=1666015161:RT=1666700335:S=ALNI_MarpFDTt2lvlUo2-EkBJy3V-uPMsA; _pk_id.100001.4cf6=6be088305e22e180.1662650904.8.1666700967.1666625362.',
"Host": "movie.douban.com",
"sec-ch-ua": "\"Chromium\";v=\"106\", \"Google Chrome\";v=\"106\", \"Not;A=Brand\";v=\"99\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"
}
# 定义四个列表,提取top250的电影名,导演,评分和经典语录
movie_names = []
directors = []
scores = []
comments = []
for i in range(10):
url = f'https://movie.douban.com/top250?start={num}&filter='
response = requests.get(url, headers=headers)
# print(response.text)
soup = BeautifulSoup(response.text, 'html.parser')
title_list = soup.find_all('span', class_='title')
directors_list = soup.find('p', attrs={"class": ""})
scores_list = soup.find_all('span', class_="rating_num")
for title in title_list: # 获取标题
# print('标题:|',title.text)
# print('标题:|',title.string)
if title.text.startswith('\xa0/\xa0'):
pass
else:
movie_names.append(title.string)
for movie in soup.select('.item'):
director_list = movie.find('p', attrs={"class": ""})
if director_list:
my_director = director_list.get_text().strip().split(' ')[1]
directors.append(my_director)
for score in scores_list:
scores.append(score.text)
for movie in soup.select('.item'):
if movie.select('.bd .quote') == []:
comments.append('空')
else:
comment = movie.select('.bd .quote')[0].text # 影评
comments.append(comment.strip())
num += 25
# print(movie_names)
# print(directors)
# print(scores)
# print(comments)
try:
woorbook = openpyxl.load_workbook('信息.xlsx') # 存在打开
except Exception as e:
woorbook = openpyxl.Workbook() # 不存在就创建
sheet_name = woorbook.active
# 写入表头信息
my_title = ['电影名称', '导演', '评分', '评论']
sheet_name.append(my_title)
# 把电影名称写入第一列
for i in range(4):
if i==0:
for j, value in enumerate(movie_names):
sheet_name.cell(row=j + 2, column=i + 1, value=value)
if i==1:
for m, value in enumerate(directors):
sheet_name.cell(row=m + 2, column=i + 1, value=value)
if i==2:
for n, value in enumerate(scores):
sheet_name.cell(row=n + 2, column=i + 1, value=value)
if i==3:
for o, value in enumerate(comments):
sheet_name.cell(row=o + 2, column=i + 1, value=value)
woorbook.save('信息.xlsx')
woorbook.close()
总结
学习的过程肯定会遇到很多问题,想要简化代码,就需要把每个基础知识掌握熟透,代码就会越来越简洁,通过这位老师让 python 学习越来越简单。
关键词
数据
代码
方式
utf-8
参数
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。