【Github】100+ Chinese Word Vectors 上百种预训练中文词向量
(给机器学习算法与Python学习加星标,提升AI技能)
该项目提供了不同表征(密集和稀疏)上下文特征(单词,ngram,字符等)和语料库训练的中文单词向量。开发者可以轻松获得具有不同属性的预先训练的向量,并将它们用于下游任务。
此外,该库还提供了一个中文类比推理数据集CA8和评估工具包,供用户评估他们的单词向量的质量。
格式
预先训练好的向量文件是 text 格式,每行包含一个单词和它的向量,每个值由空格分隔。第一行记录元信息:第一个数字表示文件中的字数,第二个表示维度。
除了密集的单词矢量(用 SGNS 训练)之外,我们还提供稀疏矢量(用 PPMI 训练)。它们与 liblinear 的格式相同,其中“:”之前的数字表示维度索引,“:”之后的数字表示该值。
Github:
https://github.com/Embedding/Chinese-Word-Vectors
预训练中文词向量
基础设置

不同的领域
用不同的表示法,上下文特征和语料库训练的中文单词向量。
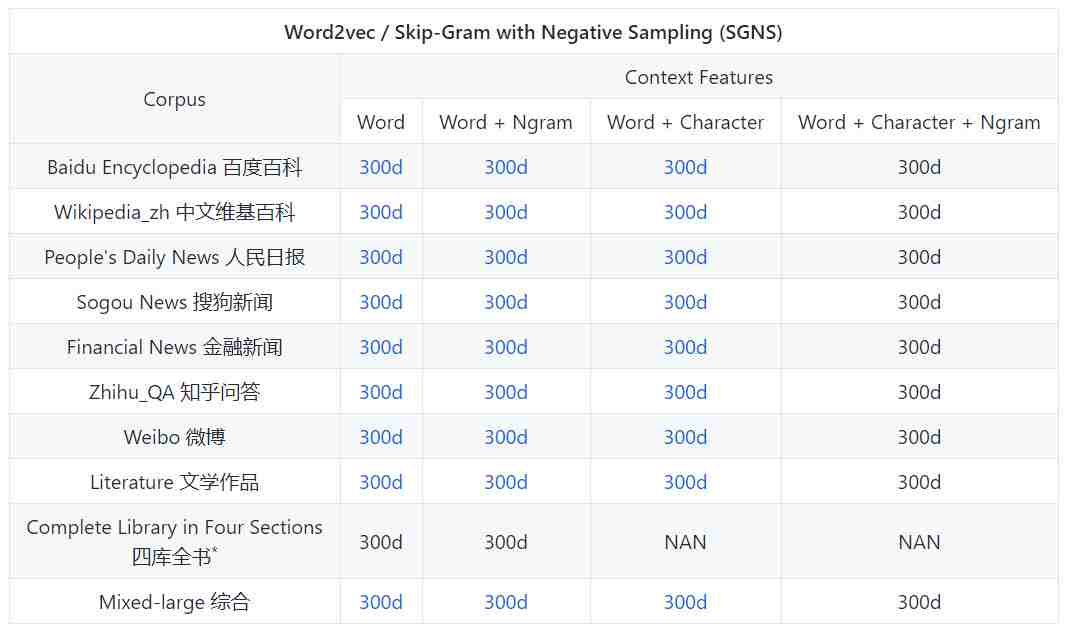
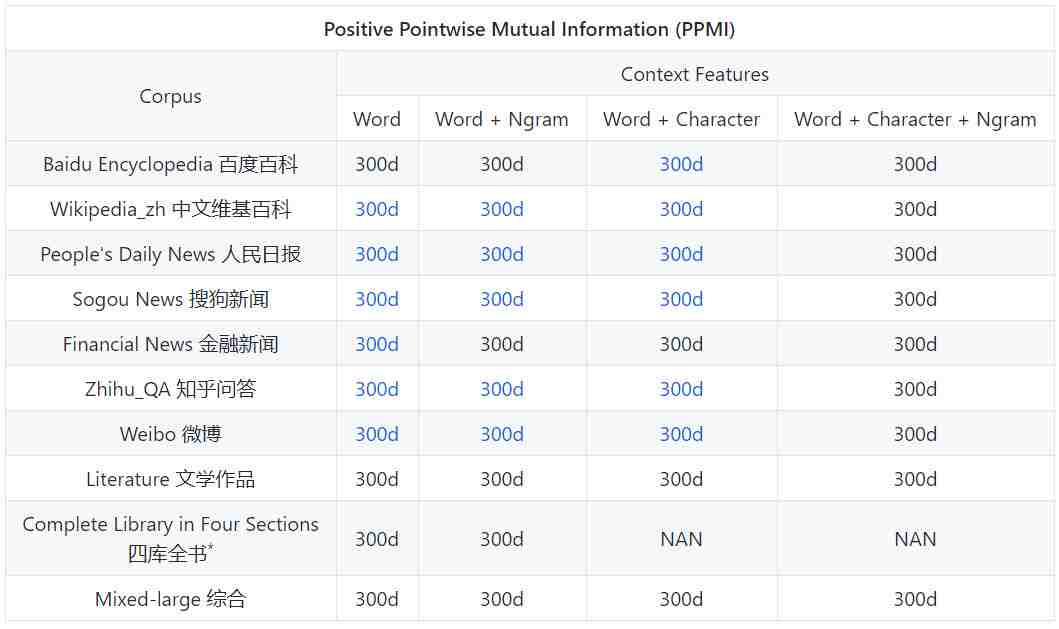
*本库提供了字符嵌入,因为大部分古汉字都是独立的字符。
各种共现信息
本库根据不同的共现信息发布单词向量,目标向量和上下文向量在相关论文中被称为输入和输出向量。
这一部分,可以获取词层面之上的任意语言单元向量。例如,汉字向量包含在词-汉字的上下文向量中。所有向量都在百度百科上使用 SGNS 训练。
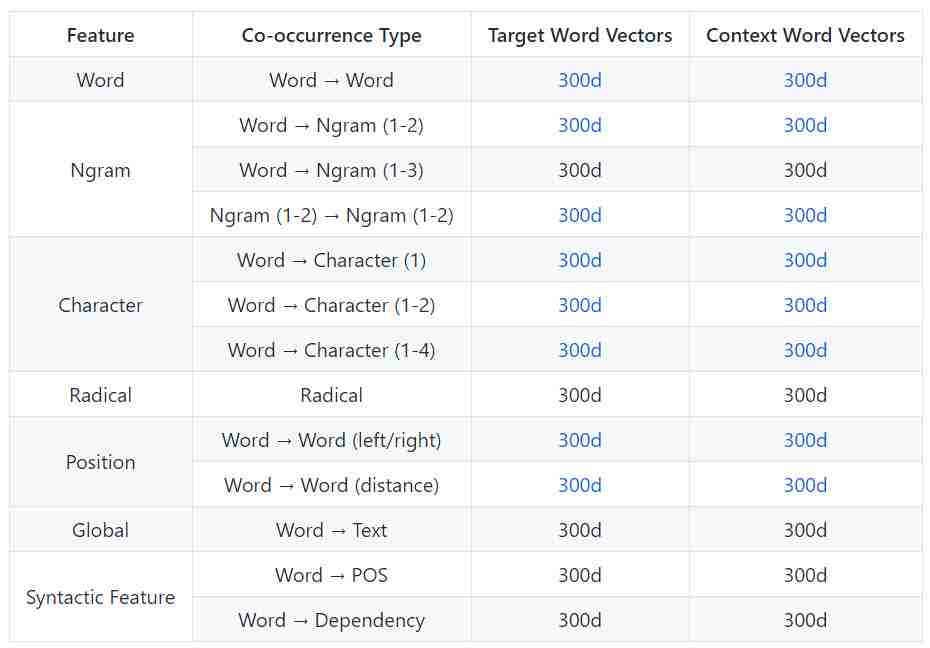

关键词
向量
单词向量
字符
上下文向量
预先训练
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。