【速览】TIP2020 | 基于通道交互损失函数的细粒度图像分类方法

学会“成果速览”系列文章旨在将图像图形领域会议期刊重要成果进行传播,通过短篇文章让读者用母语快速了解相关学术动态,欢迎关注和投稿~
◆ ◆ ◆ ◆
基于通道交互损失函数的细粒度图像分类方法
常东良、丁逸枫、谢吉洋、Ayan Kumar Bhunia、李晓旭、马占宇、吴铭、郭军、Yi-Zhe Song
TIP 2020
撰稿人:常东良
推荐理事:林宙辰
原文标题:The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification
◆ ◆ ◆ ◆
细粒度图像分类的关键是找到对应细微视觉特征的有判别力的局部区域。当前已有许多网络结构在挖掘局部特征上取得了极大的进展,然而它们往往具有复杂的网络结构。在本文中,我们证明,无需过于复杂的网络结构和复杂的训练机制,仅仅通过一个损失函数即可挖掘图像中细微的特征。
相较于传统方法中把特征图看成一个整体,我们将不同通道(channel)的特征进行区分,并通过损失函数制约它们的分布。所提出的损失函数,称为Mutual-Channel Loss(MC-Loss),包含两个通道相关的组件:一个判别力组件和一个多样性组件。
判别力组件通过一种特殊的特征通道注意力机制,将特征通道按类别进行划分,并使得属于同一类别下的特征具有判别力。多样性组件约束所有属于同一类别的特征通道在空间维度上变得互斥,即关注不同的局部区域。因此,每类拥有一组特征通道,每组特征通道内的特征学习到了不同的且有判别力的局部区域。
MC-Loss能够被端到端的训练,不需要任何的bounding-box等额外标注信息,并且能够在推理阶段产生高质量的有判别力的局部特征。我们在四个细粒度图像分类数据集(CUB-200-2011、FGVC-Aircraft、Stanford Cars和Flowers-102)上的实验结果证明了所提方法的优越性。
细粒度图像分类解决的问题是:识别一个常见类别的子类(如鸟类的品种、 车辆型号等)。由于这些子类之间的视觉差异通常非常微小,且通常包含在局部区域中,所以该任务相比于传统的图像分类任务更加困难。因此,研究高效的方法用于提取图像中有判别力的区域,进而挖掘类别间细微的差异被认为是解决细粒度图像分类问题的关键。
早期工作主要依赖于手工标注的bounding-box,对有判别力的区域进行有监督的学习。尽管取得了较好的识别效果,但是该类方法在实际应用中不可拓展。这是因为专家级别的标注很难获得,费时费力且容易出错。近来,更多的研究关注如何用弱监督的方式挖掘图像中有判别力的区域,而且已经展示出与依赖bounding-box的方法相当甚至更好的识别性能,这归功于弱监督的方法能够挖掘出人类标注错误或遗漏的区域。为了弥补标注数据(bounding-box)的不足,越来越多的复杂网络被设计用来进行局部特征学习。
这些方法通常包含两个部分:(1)一个用于局部区域定位的网络组件,(2)一个用于约束找到的局部区域有判别力的网络组件。大量的工作通过同时探索这两个组件,并探索他们的互补性,在多个细粒度数据集上获得了较好的性能。
本文受以上思路启发,与之前方法不同的是我们不再尝试引入复杂的网络结构挖掘有判别力的局部区域。取而代之的是,我们思考:仅仅用一个损失函数,是否能够使网络同时完成局部区域定位和判别力特征学习?
这样的设计模式与之前的方法相比有几个明显的优势:(1)它没有引进任何额外的网络参数,使得网络更容易训练,(2)它能够应用到任何现存或将来出现的网络结构中。解决这个问题的关键点在于我们应该如何更好地研究特征通道,而不是直接在特征图上学习细粒度的组件级别的特征。
具体地,我们假设用一组固定通道数的特征表示一个类别。这样我们便可摆脱必须施加在整个特征图上的约束限制,我们直接在每一个特征通道上施加约束,进而使得属于同类的特征通道同时具备:(1)判别性,即每一个特征通道都能够将本类与其它类区别开,(2)多样性,即每一个特征通道学习到了不同的局部区域。因此,最终结果是,一组按照类别对齐的特征通道,这些特征通道间是关注不同的局部且均是有判别力的。图1用可视化揭示了所提方法的特性。

图1. MC-Loss与传统细粒度方法的对比
我们提出的MC-Loss包含两个组件,协同工作学习细粒度特征。首先,判别力组件用于约束使得属于某一类的特征通道拥有对其分类有益的判别区域,而不是像传统的方法那样将所有特征混合在整个特征图中。此外,我们引入了一个新的通道注意力机制,在训练过程中在每一组特征通道中随机丢弃一定概率的特征通道,使得属于某一类的多个特征通道均具有判别性。之后,我们应用跨通道池化(cross-channel pooling)将每组特征在空间维度上进行混合,并产生最终的特征图,最终的特征图是类别对齐的并且拥有显著的判别性。
尽管通过判别力组件,属于每一类的特征组内的每一个特征通道均具有判别性,但是不能证明已经定位到了多个有判别力的区域。这启发我们对我们的损失函数引入了第二个组件:多样性组件。该特别设计的组件使得每个特征组内的特征通道变得互斥,进而学习到更多的有判别力的局部区域。我们通过约束使得每一个特征组内的特征通道在空间维度上的获得最大的空间相关性达到这一目的。
具体操作为:为每一个特征组再次应用跨通道池化,之后求解最大空间和。最终,可以使得模型关注到尽可能多的有判别力的区域,有助于细粒度特征学习。值得注意的是,多样性组件脱离了判别力组件是无法工作的,因为如果特征通道不是有判别力的,局部定位将更加困难。
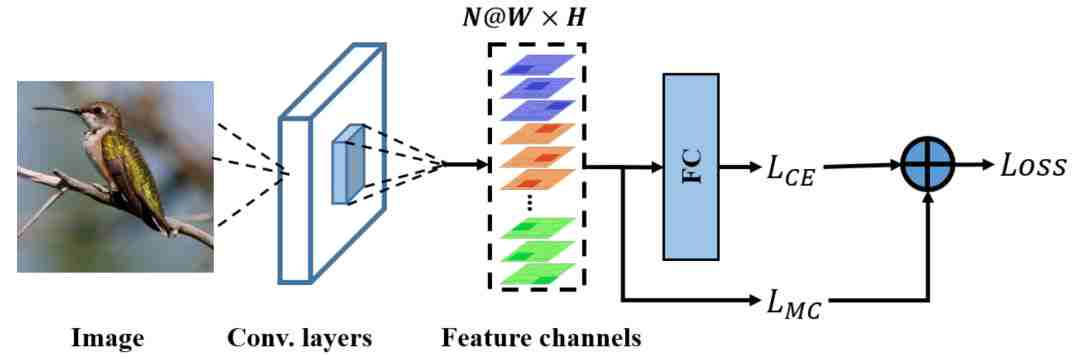
图2. 应用MC-Loss的细粒度模型分类框架
搭配MC-Loss的模型框架如图2所示。输入一张图片,首先通过一个特征提取器(如VGG16或ResNet50)提取特征。特征提取步骤中,使用在数据集ImageNet预训练的网络作为特征提取的基础网络,可选择的常用的图像分类网络如VGG、ResNet、DenseNet等,并对其进行微调(fine-tune)使模型适应特定的任务。将输入图像  作为基础网络的输入,提取图像对应的深度特征
作为基础网络的输入,提取图像对应的深度特征 , 其中,N表示深度特征的通道数,W和H分别表示每一个特征图(feature map)的宽度和高度。此外,要求深度特征的通道数N等于c×ξ, 其中,c 表示训练数据集中总的类别数,ξ 表示为每一个类别分配的特征图的数目。因此,深度特征F的第n维特征图可以被表示为:
, 其中,N表示深度特征的通道数,W和H分别表示每一个特征图(feature map)的宽度和高度。此外,要求深度特征的通道数N等于c×ξ, 其中,c 表示训练数据集中总的类别数,ξ 表示为每一个类别分配的特征图的数目。因此,深度特征F的第n维特征图可以被表示为: ,n = 1,2,...,N。且属于第i类的深度特征可以被表示为
,n = 1,2,...,N。且属于第i类的深度特征可以被表示为 ,i = 0,1,2,...,c-1,即
,i = 0,1,2,...,c-1,即





从而分组后的特征F可以被表示为
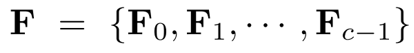
将其输入两个不同的分支中,可以计算并优化两个目的不同的优化目标。在图2中,交叉熵损失(cross-entropy loss)分支将特征作为输入,经过一个全连接层,计算得到传统的分类损失 。交叉熵损失能够驱使网络提取道德判别力信息更关注全局判别力区域。此外,MC-Loss分支监督网络,使其习得的特征关注不同的局部判别力区域。之后MC-Loss以权重μ与相加得到最终的损失函数。因此,整个网络的损失函数为
。交叉熵损失能够驱使网络提取道德判别力信息更关注全局判别力区域。此外,MC-Loss分支监督网络,使其习得的特征关注不同的局部判别力区域。之后MC-Loss以权重μ与相加得到最终的损失函数。因此,整个网络的损失函数为

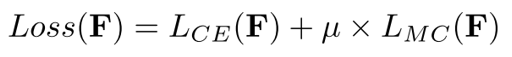
此外,MC-Loss是由一个判别力组件损失 和一个多样化组件损失
和一个多样化组件损失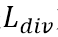 加权得到。因此,将MC-Loss定义为
加权得到。因此,将MC-Loss定义为

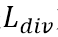

A. 判别力组件
在我们的框架中,每一个类别被确定数目并分组的特征通道表示。判别力组件能有约束使得特征通道变得类别对齐,并且对应拥有足够的判别力。判别力组件表示为,

其中,g(⋅) 定义为

其中,GAP,CCMP,和CWA分别是全局平均池化(global average pooling),跨通道最大池化(cross-channel max pooling)和通道维度的注意力机制(channel-wise attention)的简写。 ,其中,
,其中,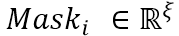 ,是一个只包含0、1的掩模矩阵,由一半的0和一半的1组成。diag(⋅) 是一个点成操作。图3(a)的左支展示了判别力组件的计算流程。
,是一个只包含0、1的掩模矩阵,由一半的0和一半的1组成。diag(⋅) 是一个点成操作。图3(a)的左支展示了判别力组件的计算流程。

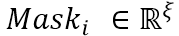

图3. (a) MC-Loss整体结构 (b) 使用MC-Loss前后特征图的对比
B. 多样性组件
多样性组件用于对特征通道间的相似性进行度量。如图3(a)的右支所示,多样性组件能够驱使属于同一组的特征通道变得不同。换句话说,属于同一类别的多个特征通道需要关注图像的多个区域,而不是关注统一的区域。因此,该组件通过对每个组的特征通道进行多样化处理,减少了冗余信息,有助于发现图像中属于每个类的不同的判别区域。该操作可以看作为了从图像的不同显著区域捕获细节,而进行的跨通道去相关。在对特征通道归一化之后,通过引入CCMP直接对特整图进行监督。多样性组件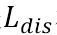 定义为
定义为
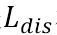
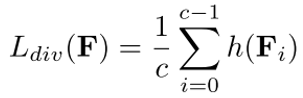
其中,h(⋅)定义为

A. 数据集
我们在四个广泛使用的细粒图图像分类数据集上对所提MC-Loss进行了验证,分别是UCSD-Birds (CUB-200-2011)、FGVC-Aircraft、Stanford Cars、和Flowers-102数据集。
B. 与SOTA方法的对比
我们在不同的backbone中应用MC-Loss,所提方法相比其它SOTA方法有稳定的性能提升。从表1可以看到,所提方法在数据集FGVC-Aircraft和Stanford Cars获得了最好的分类准确率:分别达到92.90% 和94.40%。在数据集CUB-200-2011获得了有竞争力的结果。各个方法的构成也列在表中,A、B、C、D和E分别表示随机初始化的分类层、预先训练的VGG16(去除分类层)、预先训练的VGG19(去除分类层)、预先训练的ResNet50(去除分类层)和预先训练的DenseNet161(去除分类层)。大多数方法都修改了基础的网络结构,而MC-Loss在没有引入任何额外参数的情况下,在多个数据集取得了最好的分类性能。
表1. 在三个细粒度分类数据集上与其它SOTA方法的分类准确率对比。我们使用预训练的VGG16和ResNet50作为backbone。其中,最好结果和第二好结果分别用黑体和斜体表示。

表2. 在三个细粒度分类数据集上与其它损失函数的分类准确率对比。我们使用VGG16和ResNet18作为backbone,并且不做预训练。

C. 与其它损失函数的对比
表2在四个细粒度分类数据集上将MC-Loss与其它损失函数作了对比。斜线的左右两侧分别是使用VGG16和ResNet18作为backbone的分类结果。当使用VGG16作为特征提取器时,MC-Loss分别在四个数据集取得了65.98%、89.20%、90.85%和83.23%的分类准确率。当使用ResNet18作为特征提取器时,所提方法仍然在四个数据集上获得了最好的性能。
D. 可视化
为了进一步从直觉上证明所提方法的优势,我们应用Grad-CAM对特征通道进行课可视化。图4的第一行展示了用完整的MC-Loss训练的VGG16定位到的有判别力的局部区域。能够明显观察到,三个特征通道分别关注到了鸟的不同的有判别力的区域,例如:头部、脚部以及翅膀。我们也能观察到,如果我们不使用MC-Loss中的多样化组件(第二行),这三个特征通道取向于关注同一区域。这暗示了如果没有多样性组件,学习到的特征图将不能关注不同的局部区域,这减弱了模型的分类性能。

图4. 特征通道可视化。第一列是原图;第二到四列分别展示了该样本对应的三个特征通道的局部定位可视化;最后一列是三个特征通道合并后对应的特征可视化。
图4的最后一行展示了去除MC-Loss中的通道维度的注意力机制之后,训练模型得到的特征的可视化。可以看到,当去除通道维度的注意力机制之后,这三个特征通道仅仅有一个能关注到正确的有判别力的区域(feature map 1)。而另外两个特征通道(feature map 2&3)尽管非常的不同,但是都没有学习到任何有判别力的区域。
本文展示了仅仅通过一个损失函数是如何使网络习得对细粒度图像分类有益的有判别力且具有多样性的局部特征。所提出的MC-Loss能够在没有bounding-box标注信息的情况下,高效的驱使特征通道变得有判别性并且关注不同的区域。此外,本文展示了所提出方法可以应用到不同的网络结构中,并且不引入任何额外的参数。我们在四个细粒度数据集上的实验结果均证明了所提方法的优越性。在未来的工作中,我们会探索将MC-Loss应用到其它需要局部信息的任务中,并且将之拓展到不同模态的任务当中,例如:基于草图的细粒度图像检索。
Dongliang Chang, Yifeng Ding, Jiyang Xie, Ayan Kumar Bhunia, Xiaoxu Li, Zhanyu Ma, Ming Wu, Jun Guo, and Yi-Zhe Song, “The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification”, IEEE Transactions on Image Processing (TIP), 2020.
DOI链接:https://doi.org/10.1109/TIP.2020.2973812
https://github.com/dongliangchang/Mutual-Channel-Loss
[1] T.-Y. Lin, A. RoyChowdhury, and S. Maji. Bilinear cnn models for fine-grained visual recognition. In proceeding of IEEE ICCV, pages 1449–1457, 2015.
[2] H. Zheng, J. Fu, T. Mei, and J. Luo. Learning multi-attention convolutional neural network for fine-grained image recognition. In proceeding of IEEE ICCV, 2017.
[3] Y. Wang, V. I. Morariu, and L. S. Davis. Learning a discriminative filter bank within a cnn for fine-grained recognition. In proceeding of IEEE CVPR, 2018.
[4] H. Zheng, J. Fu, Z.-J. Zha, and J. Luo. Looking for the devil in the details: Learning trilinear attention sampling network for fine-grained image recognition. In proceeding of IEEE CVPR, 2019.
往期精选
通知
NCIG 2020 诚招赞助
征文
第二十届全国图象图形学学术会议(NCIG2020)征文通知
通知
2020年“CSIG图像图形中国行”承办方征集
通知
中国图象图形学学会关于延期召开近期相关学术活动的通知
倡议
中国图象图形学学会致全体会员的倡议书



-长按注册会员-
-立享会员优惠-
最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。