如何在谷歌云平台上部署可解释性模型





图片来自 Pixabay
现代机器学习和人工智能在解决复杂的问题方面取得了令人印象深刻的成果。然而,复杂的问题往往意味着复杂的数据,这必然导致更复杂的模型。真正理解一个模型为什么会做出某种预测,可能会和原来的问题本身一样复杂!
这可能是有问题的,因为这些 ML 系统中已经影响到从医疗、交通运输、刑事司法、风险管理和其他社会生活领域。在许多情况下,这些人工智能系统的有用性和公平性受到我们理解、解释和控制它们的能力的限制。因此,相当大的努力被投入到打开强大而复杂的 ML 模型的黑匣子,比如深度神经网络的工作中。
可解释的人工智能是指一系列使人们能够理解为什么一个模型会给出特定的结果的方法和技术。模型可解释性是我们在 Google 云高级解决方案实验室教给客户的一个关键话题,在本文中,我们将展示如何使用 Google 云的可解释性人工智能来部署可解释和包容的机器学习模型。
本文中使用的所有代码都可以在这里找到:https://github.com/GoogleCloudPlatform/training-data-analyst/tree/master/blogs/explainable_ai 。
可解释性方法分类
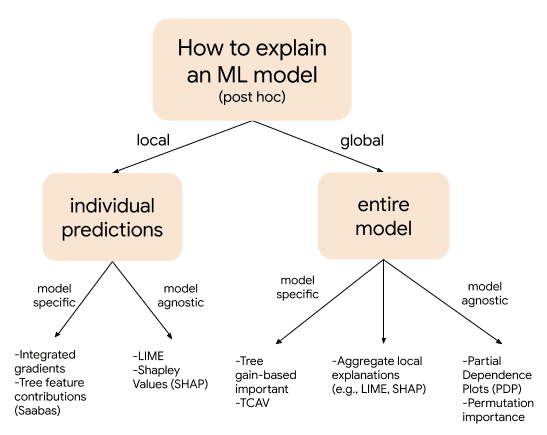
模型可解释性方法概述和不同技术的示例
大多数可解释性方法可以分为下面三类:
- 内在的还是后组织的。所谓内在,我们指的是内在可解释的模型。也就是说,它们的结构足够简单,我们可以通过简单地观察模型本身来理解模型是如何进行预测的。例如,线性模型的学习权重或用决策树学习的分割可以用来解释模型做出预测的原理。后组织方法包括使用经过训练的模型和数据来理解为什么要进行某些预测。在某些情况下,后组织方法也可以应用于具有内在可解释性的模型。在这篇文章中,我们将重点讨论后自组织模型的可解释性,因为许多先进的方法,如梯度增强和神经网络,都是用这种方法最容易理解。
- 模型不可知与模型特定。模型不可知意味着可解释性方法可以应用于任何模型,而特定于模型的方法只能用于特定的模型类型。例如,如果该方法只适用于神经网络,则将其视为特定于模型。相反,如果可解释性方法将训练的模型视为一个黑盒,那么它将被视为模型不可知的。
- 本地与全局。局部可解释性方法旨在解释单个数据点或预测,而全局方法则试图全面解释模型在整体上的表现。通过使用本地结果的聚合,所有本地方法都可以转换为全局技术。
在 Google 云上部署可解释模型
你可以使用可解释的 AI 在 GCP 上部署可解释模型,并使用 gcloud beta ai-platform explain 命令进行预测。
训练、预测的步骤如下:
- 训练模型并将其部署到 GCP 上。
- 将包含基线特征值的 JSON 文件上传到云存储桶。
- 使用此 JSON 文件创建模型版本并指定 explanation-method。
- 请求 gcloud beta ai-platform explain 获取解释。
下面我们将更详细地展示这些步骤。
首先,你需要一个在 Google 云 AI 平台(CAIP)上经过训练和部署的模型。我们将查看纽约市出租车数据集(https://bigquery.cloud.google.com/table/nyc-tlc:yellow.trips?tab=details&pli=1)。你可以看看这篇博文(https://towardsdatascience.com/how-to-train-machine-learning-models-in-the-cloud-using-cloud-ml-engine-3f0d935294b3),看看如何在 CAIP 上轻松地训练一个模型。在编写本文时,AI 的解释性只支持 TensorFlow 1.x,因此无论你构建什么模型,请确保使用 TensorFlow 1.x。一旦你的模型采用 SavedModel 格式(https://www.google.com/search?q=tensorflow+model+format&oq=tensorflow+model+format&aqs=chrome.0.0l2j69i61j69i65j69i60l4.2431j0j7&sourceid=chrome&ie=UTF-8),我们将在 CAIP 上创建一个新模型:
gcloud ai-platform models create taxifare在部署我们的模型之前,我们必须配置一个 explanations_metadata.json 文件并将其复制到模型目录。在这个 JSON 文件中,我们需要告诉 AI 解释我们的模型期望的输入和输出张量的名称。
另外,在这个文件中,我们需要设置 input_baselines,它的作用是告诉解释服务模型的基线,输入应该是什么。了解基线对于有效使用许多模型解释技术非常重要。这两种支持技术——Shapley 采样和梯度综合,将预测结果与基线特征值进行比较。选择适当的基线是很重要的,因为本质上,你是在对比模型的预测与基线值的比较方式。要了解更多关于基线的信息,请查看可解释的 AI 白皮书(https://storage.googleapis.com/cloud-ai-whitepapers/AI%20Explainability%20Whitepaper.pdf)。
一般来说,对于数字形式的数据,我们建议选择一个简单的基线,例如平均值或中值。在本例中,我们将使用每个特征的中值——这意味着此模型的预测基线将是我们的模型使用数据集中,每个特征的中值预测的出租车费用。
explanation_metadata = { "inputs": { "dayofweek": { "input_tensor_name": "dayofweek:0", "input_baselines": [baselines_mode[0][0]] # Thursday }, "hourofday": { "input_tensor_name": "hourofday:0", "input_baselines": [baselines_mode[0][1]] # 8pm }, "dropofflon": { "input_tensor_name": "dropofflon:0", "input_baselines": [baselines_med[4]] }, "dropofflat": { "input_tensor_name": "dropofflat:0", "input_baselines": [baselines_med[5]] }, "pickuplon": { "input_tensor_name": "pickuplon:0", "input_baselines": [baselines_med[2]] }, "pickuplat": { "input_tensor_name": "pickuplat:0", "input_baselines": [baselines_med[3]] }, }, "outputs": { "dense": { "output_tensor_name": "output/BiasAdd:0" } }, "framework": "tensorflow" }我们可以将此 Python 字典写入 JSON 文件:
# Write the json to a local filewith open(‘explanation_metadata.json’, ‘w’) as output_file: json.dump(explanation_metadata, output_file) # Copy the json to the model directory.然后在 bash 中,我们使用 gsutil 将 JSON 文件复制到模型目录中。
$ gsutil cp explanation_metadata.json $model_dir现在我们已经创建了 explaintations_metadata.json 文件,我们将部署新版本的模型。此代码与使用 gcloud 创建模型版本的一般过程非常相似,但有一些附加标志:
gcloud beta ai-platform versions create $VERSION_IG \ -- model $MODEL \ --origin $model_dir \ --runtime-version 1.15 \ --framework TENSORFLOW \ --python-version 3.5 \ --machine-type n1-standard-4 \ --explanation-method ‘integrated-gradients’ \ --num-integral-steps 25使用「explanation method」标志指定解释方法——当前支持综合梯度和 Shapley 采样。
注:当在综合梯度和 Shapley 采样之间进行取舍时,我们引用白皮书上的内容:
对于神经网络和一般可微模型,推荐使用综合梯度。它提供了计算优势,特别是对于大的输入特征空间(例如,具有数千个输入像素的图像)来说很有用。对于不可微模型,我们推荐使用 Shapley 采样,这是由树和神经网络的元集合组成的 AutoML Tables 模型的情况。
此外,对于那些想知道 Shapley 抽样方法与流行的 SHAP 库有何不同的人,白皮书中有如下内容:
有很多方法可以应用 Shapley 值,它们在引用模型、训练数据和解释上下文的方式上有所不同。这导致了用于解释模型预测的 Shapley 值的多样性。考虑到 Shapley 的唯一性,这有点不幸。Mukund Sundararajan 和 Amir Najmi 在「 The many Shapley values for model explanation」中对此主题进行了深入的讨论。我们的方法属于基线 Shapley 类别,可以同时支持跨各种输入数据模式的多个基线。
现在我们的模型已经部署,我们可以从 Jupyter notebook 获取本地属性:
resp_obj = !gcloud beta ai-platform explain — model $MODEL \ — version $VERSION_IG — json-instances=’taxi-data.txt’response_IG = json.loads(resp_obj.s)# Analyze individual example.explanations_IG = response_IG[‘explanations’][0][‘attributions_by_label’][0]我们可以将这些内容加载到 Pandas DataFrame 中,并为各个示例绘制属性:
df = pd.DataFrame(explanations_IG)df.head()
row = df.iloc[0] # First example.row.plot(kind=’barh’)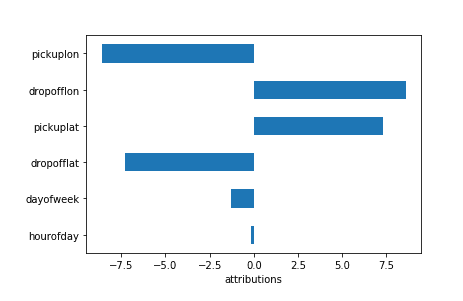
最后,我们可以通过聚合本地属性来获得全局模型的可解释性:
df.mean(axis=0).plot(kind=’barh’, color=’orange’)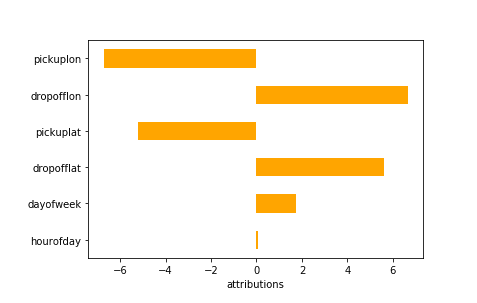
有关使用 Shapley 抽样全局属性的更多信息,请参阅这篇文章:https://arxiv.org/pdf/1908.08474.pdf。
结论
就到这里了!在本文中,我们展示了如何使用可解释的人工智能在 Google 云平台上部署可解释模型。可解释的人工智能工具允许用户从已部署的模型中获取本地解释。这些解释可以结合在一起,以提供全局解释性。除了上述步骤之外,你还可以查看 What-If 工具(https://pair-code.github.io/what-if-tool/index.html#features)来检查和解释你的模型。
via:https://towardsdatascience.com/how-to-deploy-interpretable-models-on-google-cloud-platform-8da93f2e131d
封面图来源:https://www.publicdomainpictures.net/cn/view-image.php?image=262884




最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。