ACL 2019 | 清华等提出ERNIE:知识图谱结合BERT才是「有文化」的语言模型

选自arXiv
作者:Zhengyan Zhang等
机器之心编译
BERT 等预训练语言模型只能学习语言相关的信息,它们学习不到「知识」相关的信息。最近,清华大学与华为的研究者提出用知识图谱增强 BERT 的预训练效果,让预训练语言模型也能变得「有文化」。
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一。例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 NLP 任务的性能。因此,我们获取 BERT 隐藏层表征后,可用于提升自己任务的性能。
但是,已有的预训练语言模型很少考虑知识信息,具体而言即知识图谱(knowledge graphs,KG),知识图谱能够提供丰富的结构化知识事实,以便进行更好的知识理解。简而言之,预训练语言模型只知道语言相关的「合理性」,它并不知道语言到底描述了什么,里面是不是有什么特殊的东西。
来自清华大学的张正彦、韩旭、刘知远、孙茂松和来自华为诺亚方舟实验室的蒋欣、刘群最近发布了一项研究,他们认为知识图谱中的多信息实体(informative entity)可以作为外部知识改善语言表征。
该研究结合大规模语料库和知识图谱训练出增强版的语言表征模型 (ERNIE),该模型可以同时充分利用词汇、句法和知识信息。实验结果表明 ERNIE 在多个知识驱动型任务上取得了极大改进,在其他 NLP 任务上的性能可以媲美当前最优的 BERT 模型。
论文:ERNIE: Enhanced Language Representation with Informative Entities

- 论文地址:https://arxiv.org/pdf/1905.07129.pdf
- 目前该研究代码已开源:https://github.com/thunlp/ERNIE
预训练语言模型怎么了?
预训练语言表征模型包括基于特征的和基于精调(fine-tuning)的两种方法,它们能从文本捕捉到丰富的语言信息,并用于不同的 NLP 任务。2018 年提出的 BERT 可能是最受关注的预训练语言模型之一,它提出时在各种 NLP 任务中都能获到当前最优的效果,而且不同的任务只需要简单地精调就行了。
尽管预训练语言表征模型已经获得了很好的效果,并且在很多 NLP 任务中都可以作为常规模块,但它却忽略了将知识信息整合到语言理解中。如下图 1 所示,如果不知道「Blowin' in the Wind」和「Chronicles: Volume One」分别是歌曲与书籍,那么模型很难识别它们是 Bob Dylan 的两个工作。即在实体类型任务中,模型识别不出 Bob Dylan 同时是歌曲作家和书籍作者。

图 1:为语言理解嵌入外部知识的示例。其中实线表示已存在的知识事实,红色虚线表示从红色句子中抽取的事实,蓝色虚线表示从蓝色句子抽取的事实。
对于现有的预训练语言表征模型,上面例子的两句话在句法上是有歧义的,例如可以理解为「UNK wrote UNK in UNK」。因此使用丰富的知识信息能构建更好的语言理解模型,也有益于各种知识驱动的应用,例如实体类型和关系分类等。
但如果要将外部知识组合到语言表征模型中,我们又会遇到两大主要挑战:
- 结构化的知识编码:对于给定的文本,如何高效地抽取并编码对应的知识图谱事实是非常重要的,这些 KG 事实需要能用于语言表征模型。
- 异质信息融合:语言表征的预训练过程和知识表征过程有很大的不同,它们会产生两个独立的向量空间。因此,如何设计一个特殊的预训练目标,以融合词汇、句法和知识信息就显得非常重要了。
这是一个「有文化」的预训练语言模型
为了克服上面提到的这些挑战,清华大学等研究者提出一种名为「通过多信息实体增强语言表征(ERNIE)」的模型。重要的是,ERNIE 能同时在大规模文本语料库和知识图谱上预训练语言模型。总体而言,ERNIE 分为抽取知识信息与训练语言模型两大步骤,下面将简述 ERNIE 到底是怎样构建的。
1) 对于抽取并编码的知识信息,研究者首先识别文本中的命名实体,然后将这些提到的实体与知识图谱中的实体进行匹配。
研究者并不直接使用 KG 中基于图的事实,相反他们通过知识嵌入算法(例如 TransE)编码 KG 的图结构,并将多信息实体嵌入作为 ERNIE 的输入。基于文本和知识图谱的对齐,ERNIE 将知识模块的实体表征整合到语义模块的隐藏层中。
2) 与 BERT 类似,研究者采用了带 Mask 的语言模型,以及预测下一句文本作为预训练目标。除此之外,为了更好地融合文本和知识特征,研究者设计了一种新型预训练目标,即随机 Mask 掉一些对齐了输入文本的命名实体,并要求模型从知识图谱中选择合适的实体以完成对齐。
现存的预训练语言表征模型只利用局部上下文预测 Token,但 ERNIE 的新目标要求模型同时聚合上下文和知识事实的信息,并同时预测 Token 和实体,从而构建一种知识化的语言表征模型。
最后,研究者针对两种知识驱动型 NLP 任务进行了实验,即实体分型(entity typing)和关系分类。实验结果表明,ERNIE 在知识驱动型任务中效果显著超过当前最佳的 BERT,因此 ERNIE 能完整利用词汇、句法和知识信息的优势。研究者同时在其它一般 NLP 任务中测试 ERNIE,并发现它能获得与 BERT 相媲美的性能。
模型架构
如图 2 所示,ERNIE 的整个模型架构由两个堆叠的模块构成:(1)底层的文本编码器(T-Encoder),负责获取输入 token 的词法和句法信息;(2)上层的知识型编码器(K-Encoder),负责将额外的面向 token 的知识信息整合进来自底层的文本信息,这样我们就可以在一个统一的特征空间中表征 token 和实体的异构信息了。我们用 N 表示 T-Encoder 的层数,用 M 表示 K-Encoder 的层数。

图 2:左部分是 ERNIE 的架构。右部分是用于 token 和实体的互相融合的聚合器。信息融合层的输入有两类:一是 token 嵌入,二是 token 嵌入和实体嵌入连接起来的结果。信息融合完成后,它会为下一层输出新的 token 嵌入和实体嵌入。
针对具体任务进行精调

图 3:针对具体任务修改输入句子。为了对齐不同类型输入的 token,这里使用了点线构成的矩形作为占位符。彩色矩形表示具体的标记(mark)token。
如图 3 所示,对于不同类型的常见 NLP 任务,ERNIE 可以采用类似于 BERT 的精调过程。研究者提出可将第一个 token 的最终输出嵌入(其对应于特有的 [CLS] token)用作特定任务的输入序列的表征。针对某些知识驱动型任务(比如关系分类和实体分型),可以设计出针对性的精调过程:
关系分类任务需要系统基于上下文分类给定实体对的关系标签。要针对关系分类任务精调 ERNIE,最直接的方法是将池化层应用于给定实体提及的最终输出嵌入,并将它们的提及嵌入的连接结果用于表征给定的实体对,以便进行分类。
这篇论文设计了另一种方法,即通过添加两个标记(mark)token 来凸显实体提及,从而修改输入 token 序列。这些额外的标记 token 的作用类似于传统的关系分类模型(Zeng et al., 2015)中的位置嵌入。然后,也取其 [CLS] token 嵌入以便分类。注意,研究者分别为头部实体和尾部实体设计了不同的 token [HD] 和 [TL]。
针对实体分型的特定精调过程是关系分类的一种简化版本。因为之前的分型模型对上下文嵌入和实体提及嵌入都进行了充分的利用 (Shimaoka et al., 2016),所以研究者认为经过提及标记 token [ENT] 修改过的输入序列可以引导 ERNIE 关注将上下文信息与实体提及信息两者结合起来。
实验
这一节将介绍预训练 ERNIE 的细节以及在五个 NLP 数据集上的精调结果,其中既有知识驱动型任务,也有常见的 NLP 任务。
实体分型
下表给出了实体分型数据集 FIGER 和 Open Entity 的统计情况。

下表是不同模型在 FIGER 数据集上的结果。FIGER 是一个使用广泛的远监督实体分型数据集。
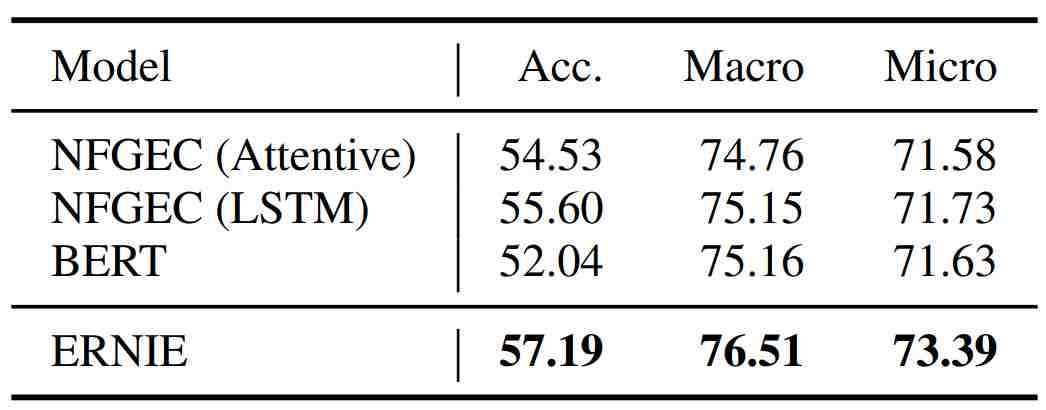
根据这些结果可以得知:(1)BERT 在 macro 和 micro 指标上的结果与 NFGEC 相当。但是,BERT 在准确度(Acc.)方面逊于最佳的 NFGEC 模型。因为严格准确度(strict accuracy)是指预测结果等同于人类标注的实例的比例,所以 BERT 强大的拟合能力能使其学习到一些来自远监督(distant supervision)的错误标签。(2)相比于 BERT,ERNIE 在严格准确度上提升显著,这说明外部知识能为 ERNIE 设置规范,能使其避免拟合有噪声标签,从而助益实体分型。
下表给出了不同模型在 Open Entity 数据集上的结果。

从上表可以观察到:(1)BERT 和 ERNIE 能实现比之前的实体分型模型更高的召回率(R),这意味着为了实现更好的实体分型,预训练语言模型能够同时充分地利用无监督预训练和人工标注的训练数据。(2)ERNIE 在精度(P)和召回率方面都比 BERT 高 2% 左右,这意味着有信息的实体有助于 ERNIE 更精确地预测标签。
总结一下,ERNIE 能通过注入知识图谱的信息而有效降低 FIGER 中有噪声标签的难度。此外,在有优质标注的 Open Entity 数据集上,ERNIE 也优于基线水平。
关系分类
下表给出了关系分类数据集 FewRel 和 TACRED 的统计情况。
下表给出了不同模型在 FewRel 和 TACRED 上的结果。

从上表中可以看到:(1)因为训练数据没有足够的实例来从头开始训练 CNN 编码器,所以 CNN 的 F1 分数仅有 69.35%。然而,BERT 和 ERNIE 这两个预训练模型的 F1 分数至少高出 15%。(2)ERNIE 的 F1 分数比 BERT 的高 3.4%,优势明显,这说明融合外部知识非常有效。
总而言之,研究发现,相比于单纯的编码器 CNN 和 RNN,预训练后的语言模型能为关系分类提供更多信息。ERNIE 在实验所用的两个关系分类数据集上都优于 BERT,而且尤其值得一提的是 FewRel 有远远更小的训练集。这表明额外的知识有助于模型充分利用小规模训练数据,这对于大多数 NLP 任务而言都很重要,因为大规模有标注数据并不容易获得。
GLUE
下表给出了研究者提交的 ERNIE 的结果与 GLUE 排行榜中 BERT 的结果。

BERT 和 ERNIE 在 GLUE 的不同任务上的结果
可以看到,ERNIE 在 MNLI、QQP、QNLI、SST-2 这些大型数据集上与 BERT_BASE 结果一致。而在小型数据集上的结果则不很稳定:ERNIE 在 CoLA 和 RTE 上优于 BERT,在 STS-B 和 MRPC 上则更差。总体来看,ERNIE 在 GLUE 上与 BERT_BASE 结果相当。
模型简化测试
下表给出了在 FewRel 上的模型简化测试结果。
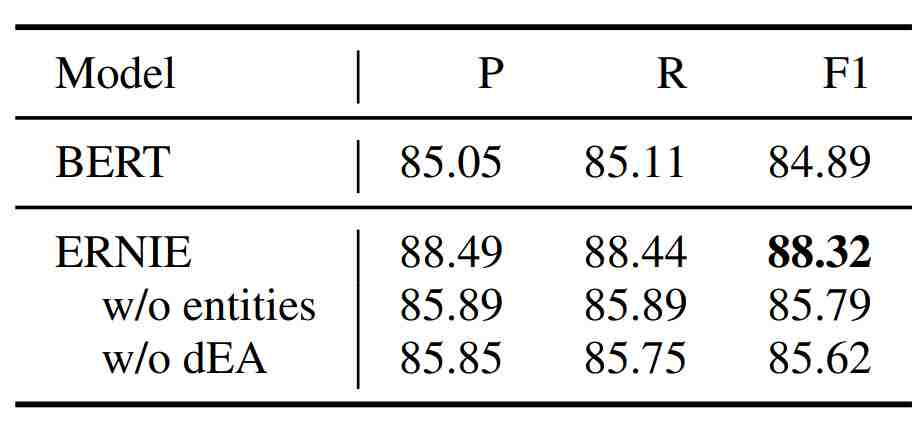
在 FewRel 上的模型简化测试结果。w/o entities 和 w/o dEA 分别表示「无实体序列输入」和「无去噪实体自动编码器」。
从上表可以看到:(1)就算没有实体序列输入,dEA 仍然可在预训练阶段将知识信息注入语言表征,这仍能在 F1 分数上优于 BERT 0.9%。(2)尽管有信息的实体能够引入大量直观上看有助于关系分类的知识信息,但没有 dEA 的 ERNIE 只能略微利用这些信息,从而将 F1 分数提升 0.7%。
总结
这篇论文提出了 ERNIE,可将知识信息整合进语言表征模型中。为了更好地融合来自文本和知识图谱的异构信息,这篇论文还提出了知识型聚合器和预训练任务 dEA。实验结果表明,ERNIE 在去除远监督的数据的噪声和在有限数据上精调方面的能力都胜过 BERT。研究者认为还有三个有待未来研究的重要方向:
- 将知识注入 ELMo 等基于特征的预训练模型;
- 将形式各异的结构化知识引入 ConceptNet 等语言表征模型,其不同于世界知识数据库 Wikidata;
- 为更大规模的预训练数据启发式地标注更多真实世界语料。


本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。