琼恩·雪诺和龙母的孩子会长啥样?让StyleGAN告诉你

选自blog.nanonets
作者:Ajay Uppili Arasanipalai
机器之心编译
参与:张倩、shooting
你有没有好奇过自己喜欢的电影或电视剧里的人物性别变换后是长啥样的?比如说,下面这位?

权游里「弑君者」转换性别的效果图
咦……长得真不咋样,还是男性的詹姆斯好看。不过,托英伟达 StyleGAN 的福,你可以用 GAN 尽情探索神奇的维斯特洛大陆了。
StyleGAN 还可以生成下面这种令人毛骨悚然的笑脸:

根据单张图像生成的笑脸
不过别急。在用神经网络预测丹妮莉丝和琼恩孩子长啥样之前,我们得稳住,确保没干下面这种蠢事。

图源:https://imgs.xkcd.com/comics/machine_learning.png
本文的目的是利用 StyleGAN 预测龙母和雪诺的孩子长啥样,因此我将简单概述一下 GAN。
如果你想深入了解 GAN,那我建议你去读 Ian Goodfellow 2016 年发表在 NeurIPS 大会的论文。这是了解 GAN 的最好来源之一(参加:深度|NIPS 2016 最全盘点:主题详解、前沿论文及下载资源(附会场趣闻))。
闲言少叙,进入正题。
生成对抗网络
大部分人喜欢将 GAN 的生成器和判别器比作造假者和警察。
但我不认为这种方式最好,尤其是如果你已经沉迷在训练神经网络的狂热里。
我认为,生成对抗网络最重要的部分在于生成图像的东西,即生成器。
生成器
生成器是一种神经网络,但不是普通的那种。
它使用一种特殊的层,称为转置卷积层(有时也叫解卷积)。
转置卷积有时也被称为 fractionally strided convolutions(我也不知道为啥叫这个名),它可以提升图像质量。
要真正理解转置卷积以及为什么深度学习社区似乎难以为它定名,我建议你去看看 Naoki Shibuya 的这篇文章:
- https://towardsdatascience.com/up-sampling-with-transposed-convolution-9ae4f2df52d0?source=search_post---------0
简而言之,下面这个动画总结了如何使用转置卷积将 2x2 矩阵提升为 5x5 的矩阵:
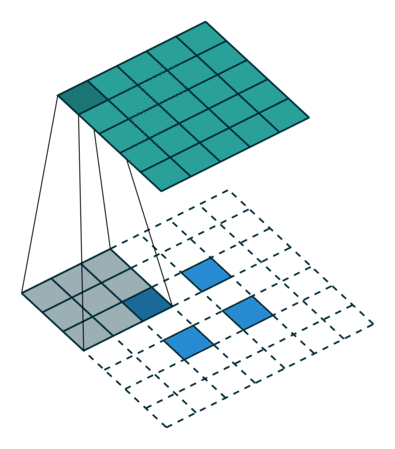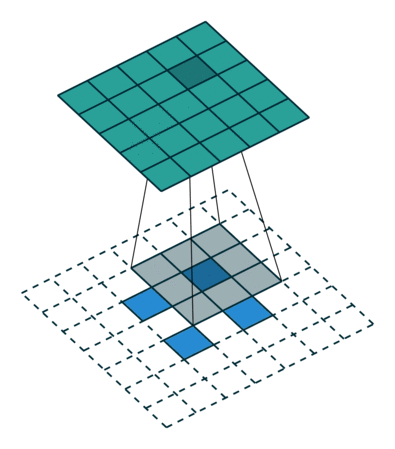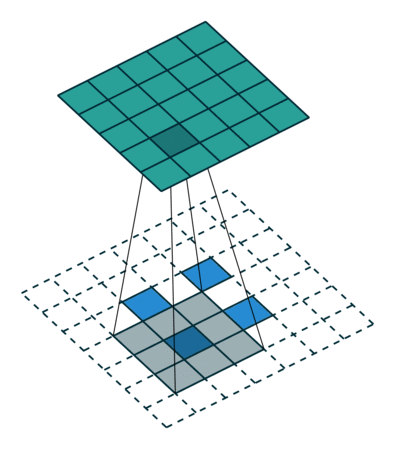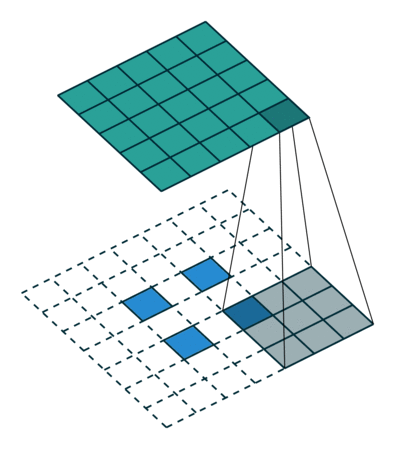
滤波器大小为 3,步长为 2 的转置卷积。来源:https://arxiv.org/abs/1603.07285
图像生成器的最终架构如下所示:
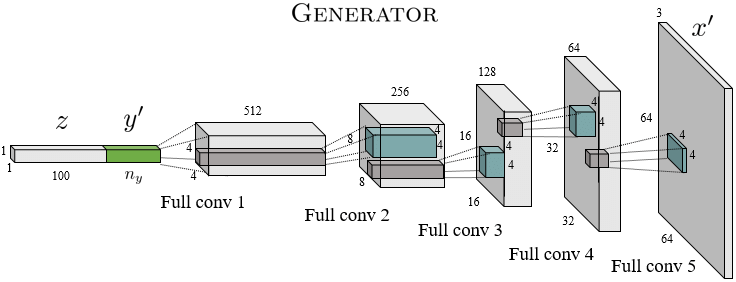
当然,如果没有任何关于卷积滤波器权重的合理概念,我们的生成器模型目前只能发出随机噪声。那可就糟糕了。
现在,我们需要一个损失函数,而不是装满图像的硬盘。
我们需要有个东西来告诉生成器它是对是错,也就是一个老师。
对于图像分类,下面这个损失函数就很好。当我们配对好图像和标签后,可以这样做:

当然,这取决于你的任务,有时你可能想要用交叉熵损失或类似的其它函数。
重点是,标注的数据要让我们可以构建一个可微分的损失函数。
我们的生成器网络也需要类似的东西。
理想情况下,损失函数应该能够告诉我们生成的图像有多逼真。因为一旦我们有了这种损失函数,就可以根据已知的方法将其最大化(即反向传播和梯度下降)。
但不幸的是,在对数函数和余弦函数看来,珊莎·史塔克和高斯噪声几乎是一回事。

在图像分类的例子中,我们有简洁的损失函数数学方程,但是这里我们没有类似的方程,因为数学不能构建可微函数来告诉我们生成的图像是真实的还是虚假的。
我再说一遍:就是输入一张图像,然后返回一个数字来表明生成图像是真是假(返回 1 即为真,返回 0 即为假)。
输入:图像;输出:二进制值。
明白了吧?这不是一个简单的损失函数问题,而是一个完全不同的神经网络。
判别器
区分生成图像真假的模型被称为判别器网络。

判别器是一个卷积神经网络,被训练用来预测输出的图像是真还是假。如果它认为图像是真,即输出「1」,否则,输出「0」。
所以从生成器的角度来看,判别器的作用相当于损失函数。
生成器需要以这种方式更新参数:当生成的图像被传输至判别器时,输出的值会接近 0,然后生成器相应地更新其参数。

图源:Yatheesh Gowda 发自 Pixabay
最后,你的 GAN 看起来是这样的:
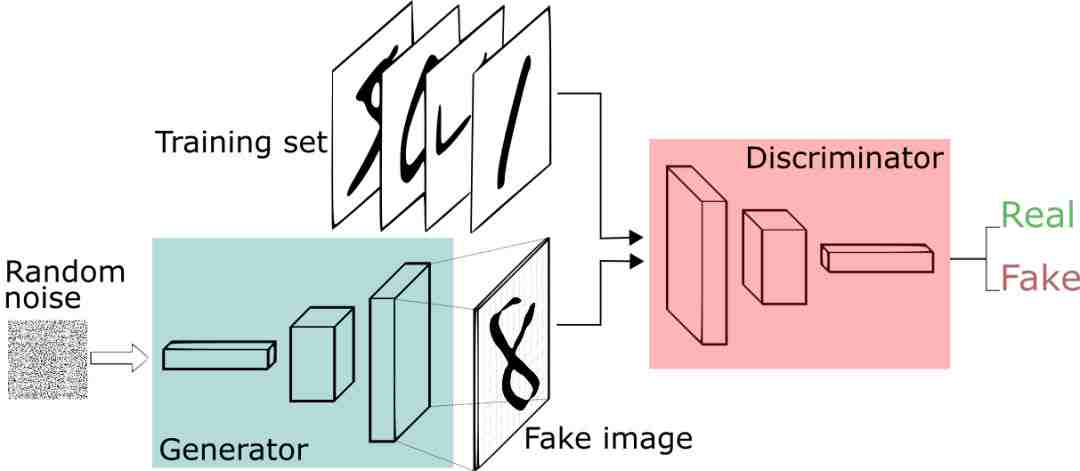
图源:https://skymind.ai/images/wiki/GANs.png
小结
总而言之,一步步创建基于 GAN 的图像生成器的过程如下:
- 生成器(带有转置卷积层的神经网络)生成图像,其中大部分图像看起来像垃圾。
- 判别器接收一堆图像,其中有些是真图像(来自大型数据集),有些是假图像(来自生成器)。
- 判别器执行二元分类,以预测哪张图像为真(输出「1」),哪张为假(输出「0」)。这时候,判别器的准确率和提利昂用弓箭的准头差不多。
- 判别器更新其参数,以便更好地对图像进行分类。
- 生成器将判别器当损失函数用,并相应地更新其参数,以便更好地生成逼真图像来欺骗判别器。即让判别器判断伪造图像为 0 来更新生成器。
- 这个过程继续,直到生成器和判别器达到一个平衡点,这时判别器无法判断生成器生成的图像是真还是假。
- 现在,你可以扔掉判别器,并有了一个不错的生成器,它生成的大部分图像看起来不像垃圾。
StyleGAN
深度学习领域发展迅猛,自 2014 年以来,GAN 方面的创新甚至比权游中死掉的角色都多。
即便用了上述 GAN 训练框架,你生成的图像充其量也就像个灰色的油炸牛油果(?)。
要想让 GAN 真正派上用场,我们需要一套好用的技术。
如果你想征服 GANseteros 的七个王国,可以参考一个 GitHub repo,该 repo 列出了过去几年主要的 GAN 创新。但除非你像伊蒙学士一样闲,否则你连其中的一半都看不完。

所以,本文将重点介绍 StyleGAN。
StyleGAN 是英伟达的研究团队于 2018 年底提出的。英伟达在这篇论文中表明,他们没有创建一种新奇的技术来稳定 GAN 的训练,也没有引入新的架构。他们的技术不同于当下有关 GAN 损失函数、正则化和超参数的讨论。
也就是说,到 2045 年人们发明巨大无比的 BigGAN 时,我将要展示的这些依然不会过时。
映射网络
通常来讲,GAN 中的生成器网络会将随机向量作为输入,并使用转置卷积将这个随机向量变为一个真实的图像,如前所述。
这个随机向量叫做潜在向量。
潜在向量有点像图像的风格说明。该向量描述了它想让生成器绘制的图像。
如果你在向法医艺术家描述一个嫌疑人,你会告诉他/她嫌疑人的一些「特征」,比如头发的颜色、面部毛发特征以及眼睛之间的距离。

图源:Kelly Sikkema
唯一的问题在于,神经网络不理解「头发颜色、面部毛发特征以及眼距。」它们只理解 CUDA 张量和 FP16.
潜在向量是用神经网络语言对图像的一种高级描述。
如果你想生成一幅新的图像,那么你就要选择一个新的向量,也就是说改变输入才能改变输出。
然而,如果你想精确控制生成图像的风格就没那么容易了。因为你无法控制生成器如何选择在可能的潜在向量上建模分布,所以你也无法精确控制生成图像的风格。
由于 GAN 学习将潜在向量映射到图像需要……被 GAN 学习,这一问题由此产生。GAN 可能不太乐意遵守人们的准则。
你可以尝试通过小幅改变潜在向量中的一个数字来改变生成人脸图像的头发颜色,但输出的图像可能会有眼镜,肤色甚至人种都会出现差别。
这一问题叫做特征纠缠(feature entanglement)。StyleGAN 旨在减少特征纠缠。
理想情况下,我们想要的是干净整洁的潜在空间表征。它允许我们对输入潜在向量做细微改变,同时保证输出的图像/人脸不发生较大变化。
StyleGAN 试图采用的方式是包含一个神经网络,该神经网络将一个输入向量映射到 GAN 用到的第二个中间潜在向量。
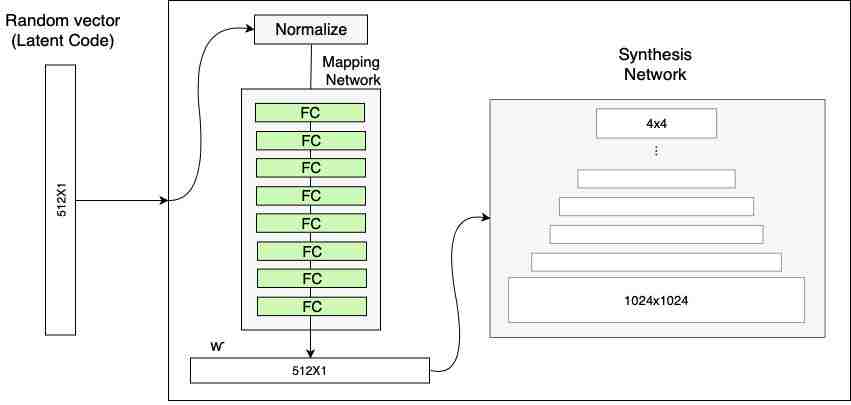
图源:https://www.lyrn.ai/wp-content/uploads/2018/12/StyleGAN-generator-Mapping-network.png
具体来说,英伟达选择使用一个 8 层的网络,该网络以一个 512 维的向量作为输入,另外一个 512 维的向量作为输出。这些选择都是任意的,你可以选择自己的参数。
假设添加这个神经网络来创造一个中间隐藏向量可以让 GAN 知道自己想如何利用向量中的数字,我们通过专用的密集层来传输它,而不是尝试找出如何直接从转置卷积中使用潜在向量。
映射网络应该减少特征纠缠(相关讨论见 StyleGAN 论文)。
如果这个想法对你来说不够直观,没有关系。你只需要知道,通过「利用微型神经网络将输入向量映射到中间潜在向量」这种做法非常好用,因此我们宁愿选择这种做法。
现在有了一个允许我们更加高效地利用潜在空间的映射网络,但要更好地控制生成图像的风格,还需要做很多工作。
自适应实例归一化(ADAIN)
回到向法医艺术家描述嫌疑人的例子,想想真实的描述过程。
你不能简单地说「他是一个瘦高的家伙,留着大红胡子。他抢了一家银行之类的。抱歉警官,我要赶一个电视节目,有空再找你……」然后打包走人。

图源:Andy Beales
你要描述嫌疑人的样子,然后等法医艺术家描出嫌疑人的轮廓,接下来你会提供更多细节,这个过程会一直持续下去,直到你们两人可以合作创作出嫌疑人的精确肖像。
换句话说,你是特征和信息(即潜在向量)的来源,会不断地将信息灌输给艺术家,后者将你的描述转化为有形的可见事物(即生成器)。
然而,在 GAN 的传统形式中,潜在向量不会「停留足够长的时间」。一旦你将潜在变量作为输入馈送至生成器中,它就不会被再次使用了,这就相当于你打包走人。
StyleGAN 模型解决了这个问题。它可以让潜在向量「停留」地久一点。通过将潜在向量注入每一层的生成器,生成器可以不断地参考「风格指南」,就像艺术家可以不断地向你发问一样。

图源:Thiago Barletta
现在来看一下比较难的技术部分。
类比非常简洁,但无礼的电视迷和高瘦的红胡子银行抢劫犯不会自己转化为数学方程。
那么 StyleGAN 是如何在每一层将潜在向量注入生成器的呢?
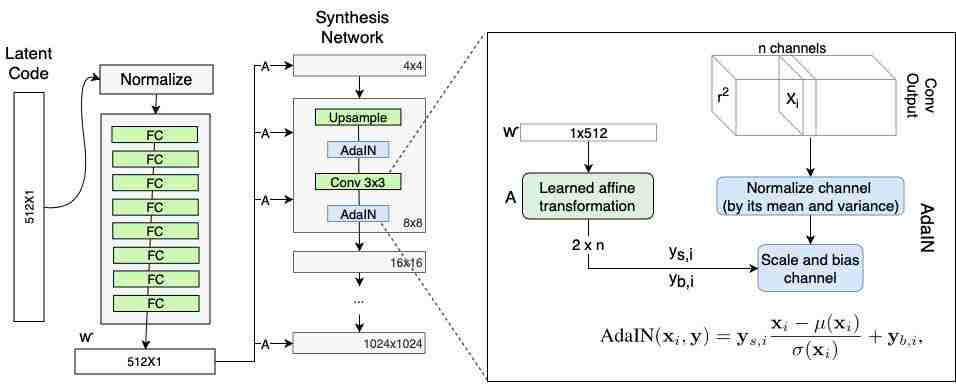
答案是自适应实例归一化(Adaptive instance normalization,AdaIN)。
AdaIN 最初用在风格迁移中,但后来在 StyleGAN 中也派上了用场。
AdaIN 利用一个线性层(原论文中将其称之为「学到的仿射变换」),该层将潜在向量映射到两个标量中,即 y_s 和 y_b。「s」代表大小,「b」代表偏差。
有了这些标量,你就可以按以下方式执行 AdaIN。
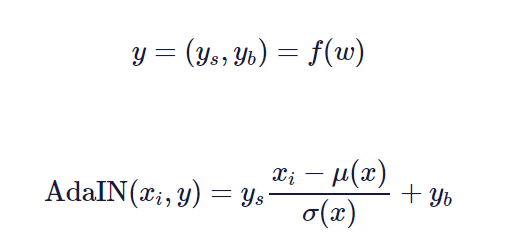
此处的 f(w) 表示一个学习到的仿射变换,x_i 是我们应用 AdaIN 的一个实例,y 是一组控制生成图像「风格」的两个标量(y_s, y_b)。
如果你之前用过批归一化,这里你可能觉得非常眼熟。但一个很大的不同之处在于,均值和方差是逐通道、逐样本计算的,而不是为整个小批次计算,如下所示:
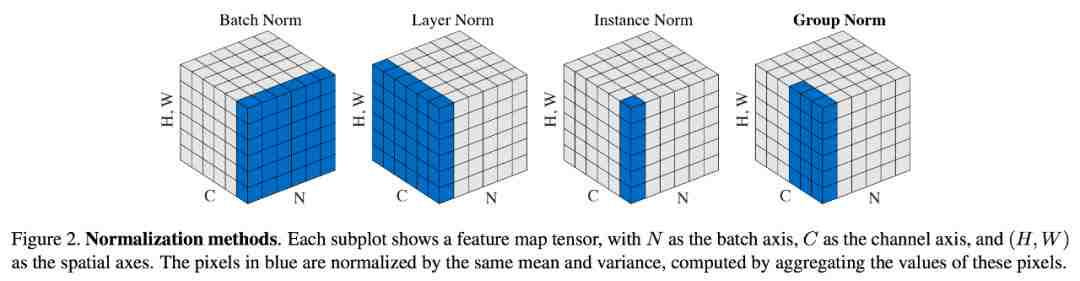
图源:https://nealjean.com/assets/blog/group-norm.png
这种将风格融入生成器隐藏层的做法可能乍看起来有点奇怪,但最新研究表明,控制隐藏层激活函数中的收益和偏差参数(即 y_s 和 y_b)可以极大地影响风格迁移图像的质量。
完成所有这些归一化工作之后,与仅使用一个输入潜在向量相比,我们就能将风格信息更好地注入生成器中。
生成器现在有了一种「描述」,知道自己要构建的是哪种图像(借用映射网络),而且它还能随时参考这个描述(借用 AdaIN)。但是我们还可以再做一些工作。
学习到的常数输入
如果你曾尝试过「只用 5 步画出一个迪士尼人物」但却以失败告终,你就会知道画这些东西通常都是从轮廓开始的。
注意,你可以用一个相同的基线轮廓画出一堆不同的人物面孔,并慢慢添加更多细节。
这一想法也适用于法医艺术家。Ta 对人脸的大致样子有一个相当不错的把握,甚至不需要你提供任何细节。
在传统的 GAN 生成器网络中,我们将一个潜在变量作为输入并利用转置卷积将潜在变量映射到图像中。
那个潜在变量的作用是为我们的生成图像添加变化。通过对不同的向量进行采样,我们可以得到不同的图像。
如果我们利用一个常数向量并将其映射到图像中,我们每次都会得到相同的图像。那将非常无聊。

然而,在 StyleGAN 中,我们已经有了将风格信息注入生成器的另一种方法——AdaIN。
既然我们可以学到向量,那我们为什么还需要一个随机向量作为输入呢?事实证明,我们不需要。
在常规 GAN 中,变化和风格数据的唯一来源就是我们后面都不会再碰的输入潜在向量。但正如我们在之前的章节中所看到的,这点非常奇怪,也不够高效,因为生成器无法再次「看到」这一潜在向量。
StyleGAN 利用自适应实例归一化将潜在变量「注入」每一层,以此来修正上述问题,由此解决了很多问题。但这也带来了一些附加效应——我们不需要从一个随机向量开始,我们可以学习一个向量,因为可以提供的任何信息都会由 AdaIN 提供。
说得更具体一点,StyleGAN 选择一个学习到的常数作为输入(一个 4x4x512 的张量),你可以将其当做一个拥有 512 个通道的 4x4 图像。再次注意,这些维度完全是任意的,你可以在实践中使用任何你想要的维度。
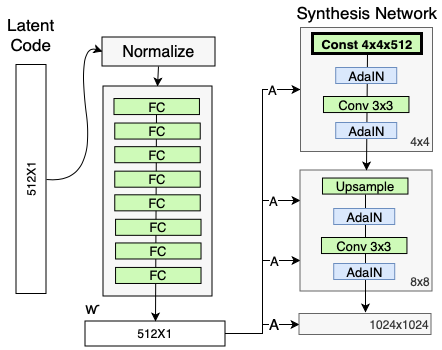
图源:https://www.lyrn.ai/wp-content/uploads/2018/12/StyleGAN-generator-Input.png
这背后的原理与迪士尼公主画圈圈是一样的:生成器可以学习一些大致的「轮廓」,这些轮廓对所有图像来说都适用。这样它就是从轮廓开始学习,而不是从零开始。
这就是 StyleGAN。实际上,还有其它一些巧妙的技术可以让你生成更逼真的图像。
现在,你大概理解了所有 GAN 中最新 GAN 的核心。
风格混合
还记得我说的怎么把潜在向量分别注入每一层吗?
那么,如果我们没有注入一个,而是注入两个潜在向量呢?
想想看。我们的生成器中有很多转置卷积和 AdaIN 层(英伟达的实现中有 18 层,但这完全是任意的)。在每个 AdaIN 层,我们单独注入一个潜在向量。
图源:https://www.lyrn.ai/wp-content/uploads/2018/12/StyleGAN-generator-AdaIN.png
所以,如果对每一层的注入是独立的,我们可以将不同的潜在向量注入不同的层。
这个主意不错吧,英伟达也是这么想的。他们团队使用 GPU,尝试用不同的潜在向量来对应不同层的「人脸」。
实验步骤设置如下:采用 3 个不同的潜在向量,单独使用这些向量时,将生成 3 个逼真的人脸图像。
然后,他们将这些向量注入 3 个不同的点:
- 在「coarse」层,隐表征占的空间很小,从 4×4 到 8×8。
- 在「medium」层,隐表征的层大小中等,从 16×16 到 32×32。
- 在「fine」层,隐表征的层在空间上也很小,从 64×64 到 1024×1024。
你可能会想,「天哪,这些精细层确实占太多层了吧。从 64 到 1024?太多了。间距不是应该更均匀吗?」
其实,并不完全是这样的。如果你读了论文《Progressive Growing of GANs for Improved Quality, Stability, and Variation》,就会知道生成器会很快获取信息,而较大的层主要细化和锐化前几层的输出。
然后,他们试着将三个潜在向量从初始位置移动一点,再查看图像如何定性地发生变化。
随机噪声
在看过英伟达用 StyleGAN 做了那么多好玩的东西后,抱歉让你失望了,但我最后保留的肯定不是最好的。
如果你生成很多张假脸图像并以新的方式将之混合后,如果找到一张最喜欢的你会怎么办?
你可以用那张图像生成一百个副本,但这样做未免太无趣了。
所以,我们可以对同样的图像做一些小小的改动。可能是稍微改变发型,或者是雀斑。反正是这类微小的改动。

图源:https://arxiv.org/pdf/1812.04948.pdf
当然,你也可以像普通的 GAN 那样做,在潜在向量中引入一些噪声:
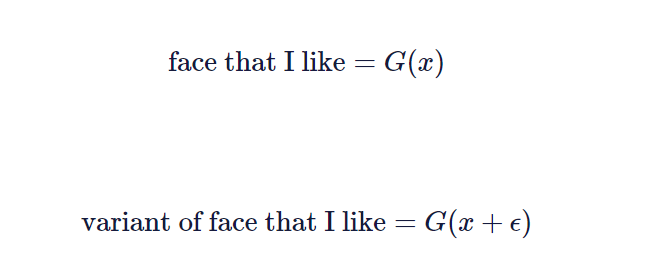
其中 G 是生成器,ϵ是向量,其组成部分是随机采样的小数字。
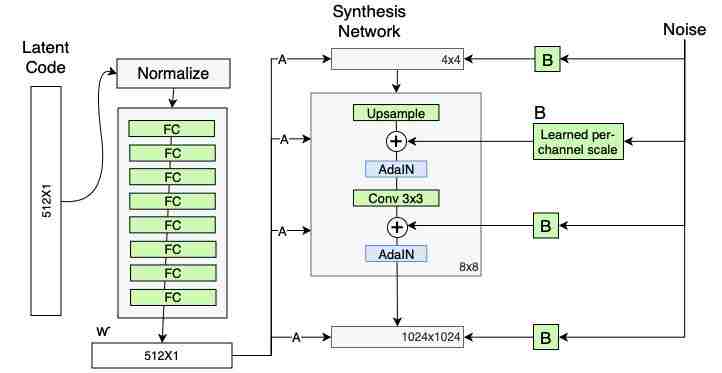
但我们有 StyleGAN,正如其名,我们可以控制图像风格。
就像我们对潜在向量所做的逐层注入一样,我们也可以对噪声这么做。我们可以选择在粗糙层、中间层、精细层或三者的任何组合中添加噪声。
StyleGAN 噪声是以像素为单位添加的,这样做是有意义的,因为这种给图像添加噪声而不是干扰潜在向量的方式更为常见,也更自然。
图源:https://www.lyrn.ai/wp-content/uploads/2018/12/StyleGAN-generator-Noise.png
在制作权游中的角色时,我没有使用噪声,因为我只想制作一些高质量的图像。
用 StyleGAN 探索你最喜欢的权游角色
现在你已经知道了 StyleGAN 的工作原理,是时候磨刀霍霍,不,摩拳擦掌试试我们最想要的效果了:预测琼恩和丹妮莉丝的孩子长啥样。
现在,我给大家隆重介绍 Djonerys(根据二者的名字结合而来,机智吧?):

喏,右下角的那个就是 Djonerys。
怎么样,帅不帅?一看就是龙母和琼恩亲生的。眉眼之间皆是两人的影子,比如那高高尖尖的鼻子,似颦非颦的眉头,尽得真传的双眼皮大眼睛……
呼,好一美少年,就是看起来比他爹少了一点阳刚之气。小编赌十块,Djonerys 是龙母和琼恩的孩子,鉴定完毕。
作为帝国的下一任守护者——Djonerys 是根据风格混合技术生成的,上面已讨论过该技术。
最后,为了庆祝维斯特洛大陆 8 周年纪念,下面我们用动画演示琼恩多年来的成长。

不同年龄段的琼恩——由 StyleGAN 生成
只要你有角色的潜在表征,就可以做点什么了。比如,生成孩童时期的卓戈·卡奥(龙母亡夫)或创建女版的詹姆斯。
其实小编最想尝试的是布兰·史塔克和艾莉亚·史塔克。犹记得在权游中刚出场的小布兰,白白嫩嫩玉雪可爱,像个女娃娃一样。但是后期饱经磨难之后,布兰变得越来越糙了。虽然依旧好看,但没有那么精致了。想知道利用前期的照片生成女版的布兰是什么样子,我猜一定是个很可爱的女孩纸。
而艾莉亚·史塔克,出场就是爬城墙的野小子,明明是个贵族小姐,性子却像个野小子。后期发展成为女刺客,一点也不令人意外。而且越到后来长得越中性,好奇她的男版会长怎样?
权游中你最喜欢谁?最想尝试谁的反性别角色?现在,放手尝试吧,七大帝国尽在你手。 

原文链接:https://blog.nanonets.com/stylegan-got/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。