性能提升19倍,DGL重大更新支持亿级规模图神经网络训练

机器之心专栏
作者:DGL 团队
本文重点介绍了 DGL v0.3的重要特性之一 — 消息融合。
我们在去年12月发布了Deep Graph Library (DGL)的首个公开版本。在过去的几个版本的更新中,DGL主要注重框架的易用性,比如怎样设计一系列灵活易用的接口,如何便于大家实现各式各样的图神经网络(GNN)模型,以及怎样和主流深度学习框架(如PyTorch,MXNet等)集成。因为这些设计,让DGL快速地获得了社区的认可和接受。然而天下没有免费的午餐,不同的框架对于相同的运算支持程度不同,并且普遍缺乏图层面上的计算原语,导致了计算速度上的不足。随着DGL接口的逐渐稳定,我们终于可以腾出手来解决性能问题。即将发布的DGL v0.3版本中,性能问题将得到全面而系统地改善。
相比当前的DGL稳定版本v0.2,DGL v0.3在性能上取得了显著提升。相比v0.2, DGL v0.3训练速度提高了19倍,并且大幅度降低了内存使用量,使得单GPU上能训练的图的大小提高到原来的8倍。比起PyG等其他框架,DGL不但训练更快,而且能够在巨大的图上(5亿节点,250亿边)训练图神经网络。
接下来,我们将介绍DGL v0.3的重要特性之一 — 消息融合(Fused Message Passing)。我们会逐一解释,为什么普通的消息传递无法拓展到大图上以及消息融合是怎么解决这一问题的。更多细节可以参考我们被 ICLR’19 的 RLGM workshop 所收录的论文[1]。
大图训练的性能瓶颈
绝大多数图神经网络模型遵循消息传递的计算范式,用户需要提供两个函数:
- 消息函数:在边上触发,定义了如何计算发送给相邻节点的消息。
- 累和函数:在点上触发,定义了如果在点上累和收到的消息。
下图中,用户自定义的消息函数用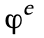 表示。消息函数将点 i 和 j 上的特征
表示。消息函数将点 i 和 j 上的特征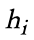 ,
, 以及边i->j上的特征
以及边i->j上的特征 作为输入,生成边上的消息(黄色方框)。在每个节点上,用户定义的累和函数将消息累和,然后调用另一个用户定义的更新函数
作为输入,生成边上的消息(黄色方框)。在每个节点上,用户定义的累和函数将消息累和,然后调用另一个用户定义的更新函数 更新节点的特征。
更新节点的特征。



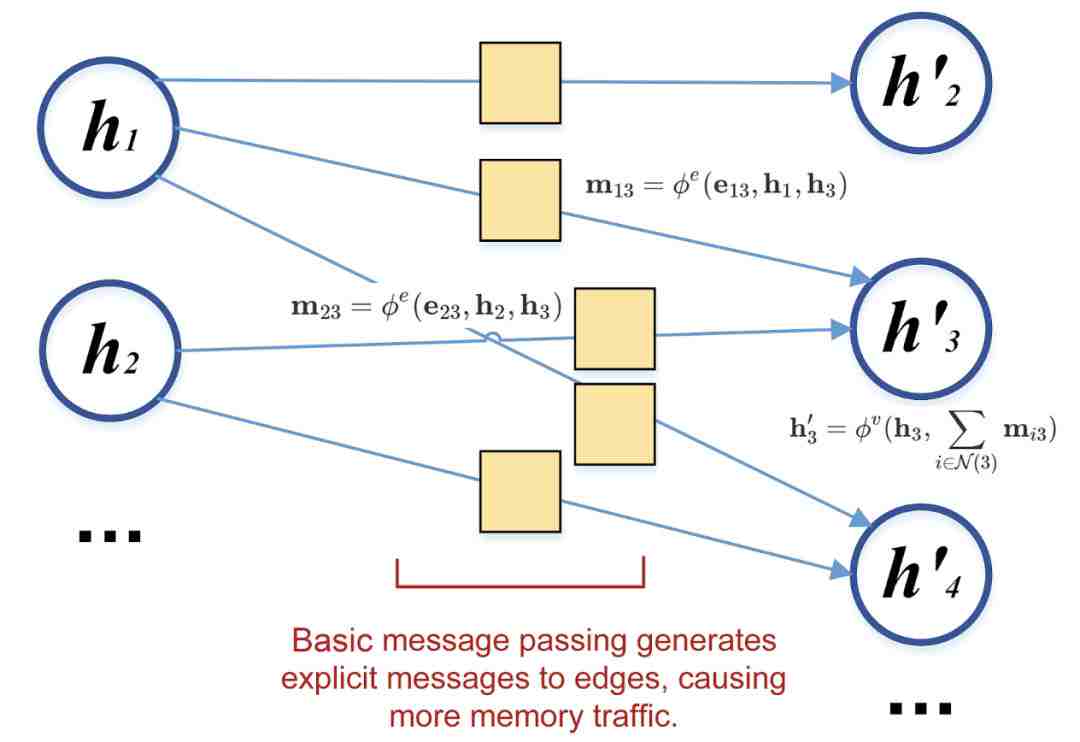
普通的消息传递很容易在DGL中实现:首先,我们通过 send 接口调用消息函数,然后通过recv 接口调用累和函数。下面的例子实现了目前流行的图卷积网络 Graph Convolution Network(GCN)。
# 使用自定义消息函数和累和函数计算图卷积
G.update_all(lambda edges: {'m' : edges.src['h']},
lambda nodes: {'h' : sum(nodes.mailbox['m'], axis=1)})
以上的代码非常简洁易懂,但性能却不佳。原因在于消息传递的过程中实际生成了消息张量(message tensor)。消息张量的大小正比于图中边的数量,因而当图增大时,消息张量消耗的内存空间也会显著上升。以 GraphSage 论文中的 Reddit 数据集(23.2万节点,1.14亿边)为例,如果我们用上述代码训练GCN,点上的特征会被拷贝成边上的信息,这会导致内存使用量骤增500倍。除了浪费内存,该做法还使得访存变得更为频繁,进而导致 GPU 的利用率降低。
消息融合解决大图训练难题
为了避免生成消息张量带来的额外开销,DGL实现了消息融合技术。DGL将 send 和 recv 接口合并成 send_and_recv(见下图)。DGL的后端通过自己的CUDA代码,在每个GPU线程中将源节点特征载入其本地内存并计算消息函数,然后将计算结果直接累和到目标节点,从而避免生成消息张量。

为实现消息融合,DGL提供了一系列预先定义好的内建函数。尽管这限制了用户对消息函数和累和函数的选择,但DGL提供了非常丰富的内建函数以实现绝大多数GNN模型。当然,用户也可以选择自己定义消息函数和累和函数,这种情况下,DGL不会进行消息融合优化。
另外在反向传播中,由于消息张量没有保存,因此需要被重新计算。实际操作中,许多消息函数的求导都不需要使用到消息张量(比如拷贝源节点特征到边上),而我们的实现也利用了这一特性。
在DGL中使用消息融合
使用消息融合非常简单。比如,我们可以用copy_src内建消息函数和sum内建累和函数改写先前的GCN实现:
import dgl.function as fn
G = ... # 任意图结构
# 将源节点的特征h拷贝为消息,并在目标节点累和生成新的特征h。
G.update_all(fn.copy_src('h', 'm'), fn.sum('m', 'h'))
图注意力模型 Graph Attention Network (GAT) 则可以用 src_mul_edge 内建消息函数和 sum内建累和函数组合实现:
# 这里假设注意力分数为边上特征e
G.update_all(fn.src_mul_edge('h', 'e', 'm'), fn.sum('m', 'h'))
DGL v0.3 将支持以下内建函数:
- 消息函数可以是从源节点特征、边特征、目标节点特征三者中选任意两个进行加、减、乘、除运算。
- DGL支持特征维度上的广播语义(broadcasting semantics)。这在多头注意力模块中非常常见。
- 累和函数可以是sum, max, min, prod。
我们推荐用户尽可能多的使用DGL的内建函数来定义图神经网络,这样DGL可以利用消息融合来提高性能。虽然这在上手上会有些门槛,但它对性能的提升是非常显著的(详见下一章节)。
性能测试
为了理解消息传递融合带来的性能提升,我们对DGL v0.3和DGL v0.2以及PyG(Pytorch Geometric v1.2.0)进行比较。其中PyG使用了普通的消息传递实现,因此在整个过程中会生成消息张量。
我们首先在主流的数据集上测试了GCN和GAT模型的性能,所有的实验使用了模型论文中的参数设定。实验在AWS p3.2xlarge instance上进行,该机器配备有NVIDIA V100 GPU (16GB 显存)。
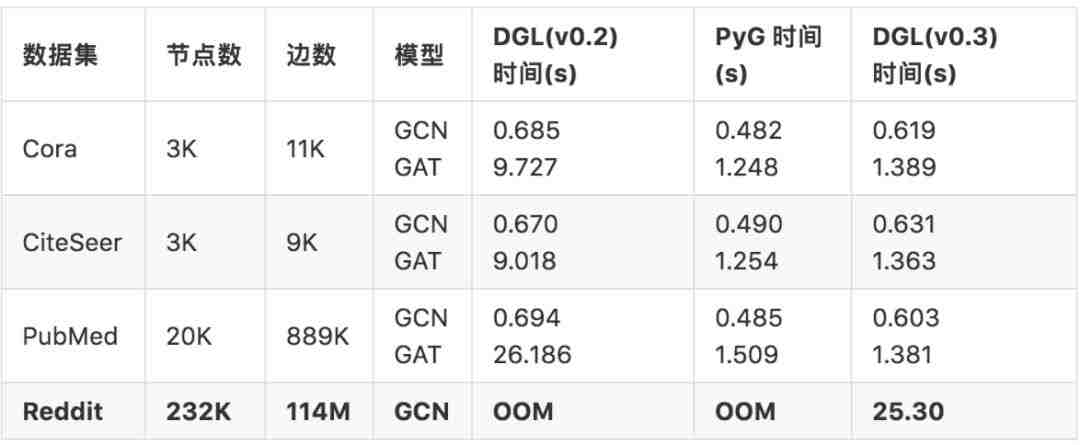
从表中可见,即将发布的DGL v0.3在性能上有显著提升,尤其在GAT模型上,训练速度提升了19倍,而这都是因为使用了消息融合技术。在小图上(比如Cora,CiteSeer和PubMed),训练的计算量和内存使用量几乎不随图的大小发生变化,和PyG相比,DGL有微小且固定的额外开销。然而,当在相对较大的图上(比如从Reddit抽取出来的图)训练时,PyG很快便耗尽了内存,而DGL则可以轻松地将数据存储在GPU上进行计算。
我们使用合成的图进一步分析DGL的性能:
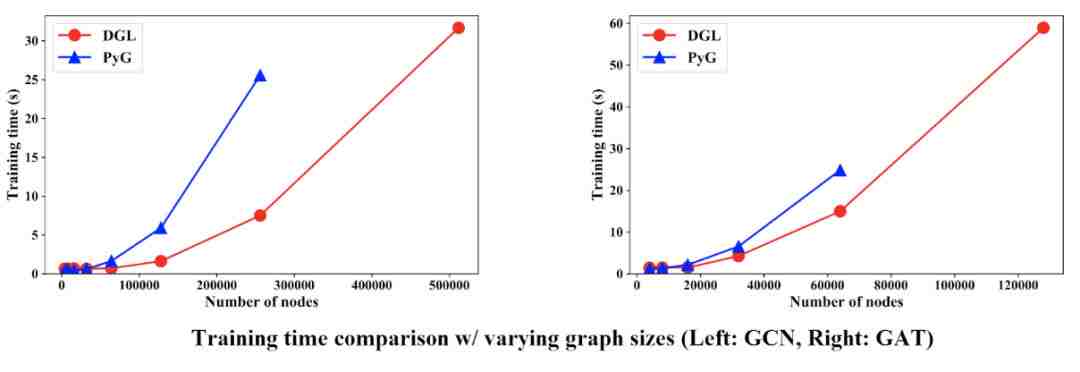
我们首先固定图的密度(0.0008),通过调节图的节点数来观察GCN和GAT的训练速度。从图中可见,DGL可以在多达50万节点的图上训练GCN模型,比PyG的最大容量高出一倍。此外,DGL的训练速度比PyG快了3.4倍。
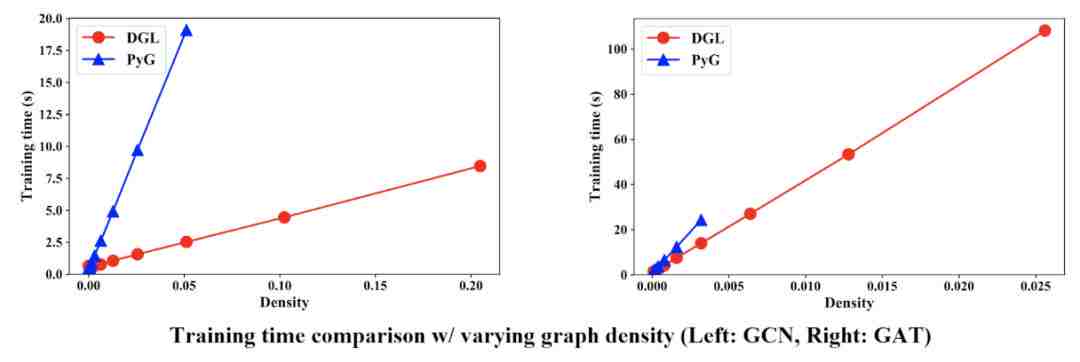
然后我们固定图的节点数,通过调节图的密度来观察训练速度。对GCN和GAT模型,相较PyG,DGL可以支持8倍多的边,并且训练快7.5倍。

我们还在一个中等大小的图上(3.2万节点,密度0.0008)通过调节隐含层的大小来观察训练速度。对于GCN模型,尽管PyG能够支1024个隐含单元,但其训练速度比DGL慢了4倍。对于GAT模型,PyG最多只能支持32个隐含单元,而DGL可以支持到256个。
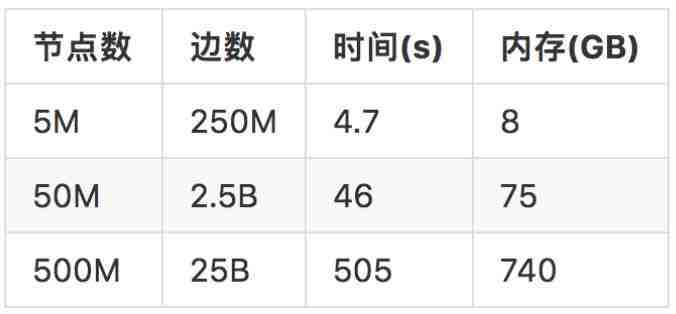
最后,我们想测试DGL的性能极限,了解DGL在单机情况下能够支持的最大的图的规模。我们在AWS x1.32xlarge (2TB 内存)上用CPU训练GCN。实验表明,DGL可以支持到5亿节点250亿边的图。
接下来期待什么
DGL团队正在积极开发其设计路线图上的功能特性。实际上,DGL项目开始之初,团队成员就考虑到了绝大多数性能优化,比如,DGL一直提倡使用其内建函数而非自定义函数,尽管内建函数只有在消息融合时才能发挥出其优势。以下是DGL团队正在积极拓展的方向:
- 撰写更详细的博客介绍如何在算力强大的CPU机器上复现大图的实验结果。
- 支持异构图结构。
- 用GPU加速图上的遍历和访问。
DGL一直努力接近用户和社区,并且渴望得到用户的反馈。如果您想要尽早尝试即将在v0.3版本发布的新特性,可以克隆DGL的GitHub仓库,切换到kernel分支,然后从源代码编译DGL项目。
请关注DGL之后的发布和更新,更多精彩敬请期待!
关于 DGL 专栏: DGL 是一款全新的面向图神经网络的开源框架。通过该专栏,我们 DGL 团队希望和大家一起学习图神经网络的最新进展。同时展示 DGL 的灵活性和高效性。通过系统学习算法,通过算法理解系统。
更多 DGL 专栏信息,请查看机器之心官网,或者点击阅读原文。
1.https://rlgm.github.io/papers/49.pdf
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。