广义相对论与深度学习能够碰撞出什么火花?高通AI Research最新研发成果一览

机器之心原创
作者:路
自 2007 年启动首个 AI 项目之后,高通(Qualcomm)在人工智能研发方面取得了很多进展。2018 年 5 月,高通成立 Qualcomm AI Research,进一步强化整合公司内部对前沿人工智能研究。现在,高通不仅是一家移动通信公司,更是人工智能领域的重要玩家。
那么,在人工智能基础研发方面,高通做了哪些事情呢?高通技术工程高级总监、AI 研发负责人侯纪磊在近期举行的高通人工智能开放日上对此进行了介绍。
侯纪磊博士强调,针对 AI 和深度学习应用,Qualcomm AI Research 更加着重打造平台式创新,推动人工智能在行业实现高效、规模化的应用,这主要体现在三个方面:能效、个性化和高效学习。
本文主要介绍了高通在能效和高效学习方面的研究进展,其中高效学习主要涉及结合物理学和深度学习创建的新型 CNN 模型——规范等变卷积神经网络(G-CNN)。
能效(power efficiency)
能效,即使应用能够实时、低功耗、流畅地进行推理。随着神经网络规模越来越大,它们所需的内存、计算量和能源也越来越多。如何提高能效,尤其是在终端侧实现高能效是高通一直以来的研究方向。
侯纪磊博士介绍道,高通通过自动化技术,利用 AI 技术来优化 AI 模型 。比如将谷歌 AutoML 的概念引入压缩、量化和编译场景,结合硬件感知(hardware-aware)实现高能效。
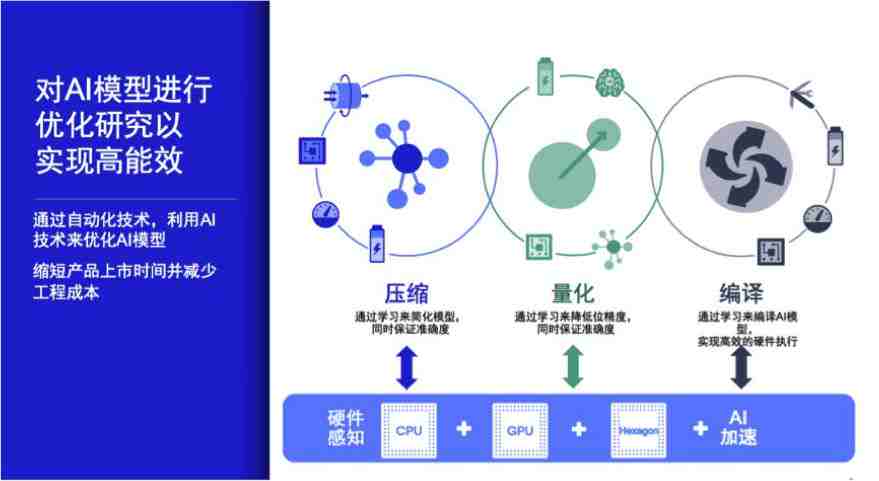
高通在高能效 AI 计算方面的研究主要围绕四个方向展开:神经网络压缩、神经网络量化、内核优化和内存计算。
内存计算:有潜力、重要的 AI 加速计算发展方向
针对内存和计算核心之间数据传输时所产生的能耗和计算成本,高通在进行一项革命性的试验研究:把内存单元与计算单元重叠,在内存单元中引入计算功能,将传统的计算架构进行重要的转变,从而大幅提升能效。
侯纪磊博士在演讲中强调,「内存计算」是未来有潜力、重要的AI加速计算发展方向。
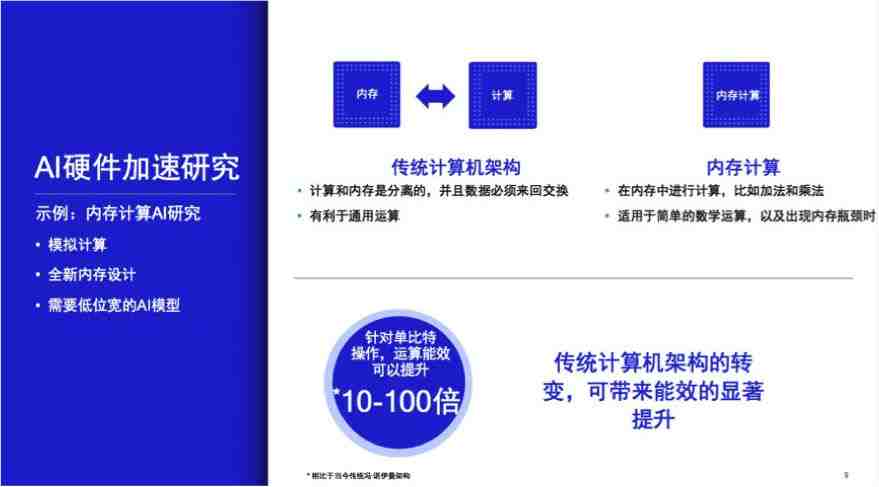
那么,内存计算是如何实现的呢?
「存储单元实际上都是通过半导体二极管来实现的。简单来说,存储单元(memory cell)是内存最基本的存储单位。一个常见的存储单元里面有 6 个晶体管,也就是我们说的 6T 存储单元。现在为了做内存计算,我们可以在 6T 存储单元原有的 6 个晶体管之外再额外增加晶体管,通过新加晶体管来实现乘法或者是累积(accumulation)。不管是卷积还是其他模型,讲到最后其本质就是乘法和加法,乘法在某种意义上也可以用加法来完成。如果在存储单元中可以增加新的晶体管,那么很多运算功能就可以在存储单元里实现,这相当于把原来的存储单元从纯粹的存储功能演进成既具有存储又具有运算的功能。而这需要重新设计硬件。」侯纪磊博士介绍道。
神经网络压缩和量化
神经网络压缩和量化是降低计算时间和能耗的重要手段。
据介绍,高通目前考虑的压缩方法包括张量分解和通道简化。高通技术副总裁、全球知名深度学习学者韦灵思教授(Max Welling)在通道简化方面创造性地引入了贝叶斯方法,即贝叶斯通道剪枝,在压缩领域实现了很好的效果。高通将两种方法结合起来,组合使用贝叶斯压缩和空间奇异值分解(SVD),相比于基线模型,该方法实现了 3 倍的压缩比,同时准确率降低小于 1%。
而模型量化有两个方向:一个是对模型进行重新训练的量化,另一个是不需要对模型重新训练的量化。侯纪磊博士表示高通在两个方向上都进行了相关研究。
关于后者,高通已经取得了一定成果。将模型从 32 位浮点到 8 位定点量化后,可实现几乎相同的准确率,每瓦特性能提升超过四倍。在使用 MobileNetV2 系列网络进行分类或分割之类的任务时,如果只是做一个「所见即所得」的简单量化,量化后的模型准确率会很差;但在不需要重新训练的情况下通过 data free quantization(DFQ)的方式进行量化,量化后的模型可以取得非常好的效果,达到和32位浮点几乎相同的准确率。这将为生态链中广泛客户的量化需求提供强有力的支持。
而关于需要重新训练的模型,侯纪磊博士表示,高通已有两篇相关论文 [4, 5] 被 ICLR 2019 接收,其中 [4] 介绍了在训练阶段进行模型量化的新方法,[5] 使用的方法是对梯度反向传播做优化。
内核优化
在内核优化方面,侯纪磊博士介绍了一个新的概念—— AI 优化代理(AI Agent):取出神经网络的某一层(如卷积层),要想使它在硬件层面上获得最好的时延指标,需要依赖 data locality,使数据尽量在计算单元本地反复使用,以降低功耗和计算成本。为了达到 data locality 的目标,则需要通过对图块大小重排序,展开并行化、向量化,从排列组合的角度找到最优的组合。
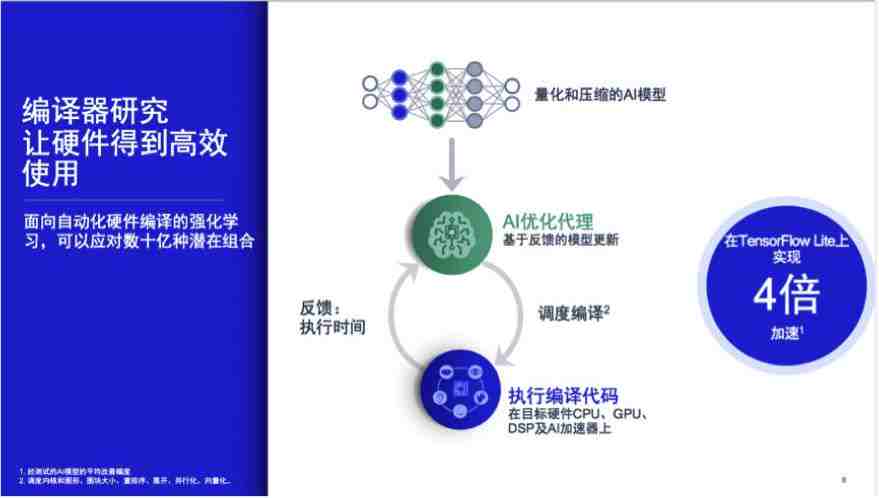
针对此,高通提出了面向自动化硬件编译的强化学习和贝叶斯优化方法,可以应对数十亿种潜在组合,从中找出相对最优解。
贝叶斯优化是一种近似逼近的方法。如果说我们不知道某个函数具体是什么,那么可能就会使用一些已知的先验知识逼近或猜测该函数是什么,这正是后验概率的核心思想。贝叶斯优化可以简单理解为黑箱的数据驱动技术,在搜索空间很大且每个样本的效果评估成本很高的情况下,贝叶斯优化是非常高效的方法,因为它的样本效率优于强化学习。
侯纪磊博士表示,高通和阿姆斯特丹大学共同建立的战略合作实验室 QUVA Lab 在贝叶斯优化上有很好的技术积累,发表了很多重要论文。高通把他们的技术引进公司内部放到内核优化这一问题上,并开展进一步的研发工作。
「总体来看,高通的 AI 研发有两个重要的特点。第一,我们更侧重于与硬件相关度更高的AI或机器学习。第二,我们非常关注终端侧的用例,当然现在我们在云端也有发力。我们正通过 AI 和数据驱动的方式,让骁龙计算平台以及各个子系统有更好的性能、能效和用户体验,这是我们非常重要的方向。」
物理学和深度学习的碰撞
目前的深度学习技术能够很好地分析 2D 数据,但是我们如何教会机器理解曲面物体的图像数据呢?尤其是在终端侧执行数据处理过程的情况。
高通技术副总裁韦灵思教授和另一位高通 AI 研究科学家 Taco Cohen 将广义相对论和量子场论的数学原理应用于深度学习,提出了一种新型卷积神经网络:规范等变卷积神经网络(Gauge Equivariant CNN,G-CNN)。该模型可接受几乎所有曲面物体数据,并将新型卷积应用其中。

侯纪磊博士详细地介绍了 G-CNN 的原理和提出过程:
CNN 的平移不变性(shift invariance)使得它可以处理目标平移后的图像,输出结果与平移之前一致。比如一个小猫小狗出现在图像上,不管它出现在图像的任意位置,CNN 模型都能够把它抓取并识别出来。然而 CNN 缺乏旋转不变性(rotation invariance),即如果我们将小猫小狗的图像旋转一个角度,CNN 模型是无法有效识别出来的。
尽管 CNN 本身无法做到旋转图像的识别,但研究者可以通过数据增强方法来做到这一点。比如,在模型训练过程中将图像旋转很多角度,使目标映射时能够将旋转后的图像映射到原来的图像上面。但这个方法存在两个问题:一,需要大量的数据增强,导致训练效率非常低;第二,即使做了数据增强,但数据增强的范围是有限的,因此还存在着很多角度的死角。
针对旋转不变性问题,高通 AI研发团队的顶级学者——韦灵思教授以及 Taco Cohen 提出了一系列解决方法。
- 第一步:在平面上引进一个初步泛化的 CNN——即组等变 CNN(Group Equivariant CNN)[3],来解决平面上的二维旋转问题。
- 第二步:在二维旋转不变性解决以后,韦灵思教授和 Taco 又提出了球面 CNN(Spherical CNN)[1],用于解决三维的旋转不变性问题,比如说在球面性物体或者三维 CT 图像上的旋转问题。相关研究《Spherical CNNs》获得了机器学习顶会 ICLR 2018 的最佳论文奖。
- 第三步:球面 CNN 的旋转不变性必须具备在给定空间内的整体对称性(global symmetry),这对应于物理学中通常所指的时空不变性。因此韦灵思教授和 Taco 紧接着提出针对局域对称性(local symmetry)的 G-CNN(规范等变 CNN,Gauge Equivariant CNN)[2]。
那么局域对称性跟整体对称性有什么不同呢?
简单地说,19 世纪、20 世纪的物理学演进,从一定程度上可以理解为是从整体对称性到局域对称性的变化。狭义相对论可以理解成在整体对称性框架之下的理论,例如电场跟磁场的等价性是时空不变的。但到了广义相对论的时候,时空不变性已经不适用了,时空是弯曲的,很多时候对称性只能是在局域上的一种属性。将这样的对应关系放在神经网络的场景里,如果一个三维物体是球状的,那么它就具备了球状旋转的整体对称性,这个时候球面 CNN 模型是可行的;一旦这个三维物体不具备这种整体对称性,而是一个尼曼三维任意曲面的时候,我们就必须通过规范等变 CNN 的方法来实现局部的旋转等变性。
与球面 CNN 模型相比,规范等变 CNN 模型的最大优势在于,它摆脱了前一种模型对于整体对称性的假设,只要在局域上近似地具备对称性,它就可以将广义相对论规范场论(gauge theory)的数学工具及相应结论借用到这里来。
「需要强调的是,规范等变 CNN 为几何深度学习(Geometric DL)这一重要方向提供了合适的理论框架。」侯纪磊博士表示。

在流形 M 上定义卷积运算,使其对局域规范变换保持不变性 [2]。
基础研究、应用研究两手抓
Qualcomm AI Research 成立将近一年。据了解,其研发方向从平台式创新,即用 AI 的方法使 AI 更有效,转向了全方位、全频谱的 AI 研究,在基础研究跟应用研究之间进行很好的平衡。因此高通在基础研究上有了更多的投入,比如贝叶斯深度学习、几何深度学习(G-CNN)、深度生成模型,以及一些新方向(无监督学习、图 CNN、贝叶斯优化等)。
而在应用研究方面,高通的 AI 技术已经应用于手机、物联网、汽车行业等多个领域。以自动驾驶为例,侯纪磊博士介绍了 AI 技术与自动驾驶具体产品线之间的结合。他表示从技术角度来看,目前 L2、L3、L4 级别的项目侧重点有所不同。
- L2 级别:无论是高通正在做的工作还是从合作方的角度,L2 项目更多处于成本优化阶段,大家都希望能够在高性价比的平台上承载更多运算功能。
- L3 级别:高通目前做了大量的原型系统工作。在今年的 CES 大会上高通公布了这方面的新动态,高通开发了原型车系统,并通过路测进一步优化技术,原型车在路上获得的数据可以帮助高通在芯片研发层面定义具体的规格参数,比如计算能力、与摄像头和传感器对接需要什么样的界面等等。
- 从 L4、L5 的角度来看,高通认为将来如果要纯粹依靠汽车自身的被动传感来实现任何时间、任何地点的自动驾驶,在很多时候会有很多极端情况是难以支持的。因此,高通认为 C-V2X 将是一项重要的技术。跟车载摄像头相比,C-V2X 在一定程度上可以认为是一种主动传感,通过车和车之间的主动通信,即使其他车辆在视距之外,或者在天气非常槽糕的情况下,司机依然可以通过 C-V2X 技术来获知其他车辆处在周围的什么位置。从安全性的角度来看,L4、L5 要做到任何地方、任何时间都能够安全稳定的自动驾驶,C-V2X 是一项非常重要的技术。侯纪磊博士表示,这是高通一直在业界推动的理念,也是从技术和产品路线上一直推动的重要方向。
而关于自动驾驶领域讨论已久的激光雷达问题,侯纪磊博士表示:「不同芯片厂商的定位可能不太一样。对于主流厂商来说,一套从计算到传感器都包含在内的模组,他们在每一辆车上能够接受的成本范围可能是在人民币 2000—3000 元左右,这一成本范围基本已经把激光雷达排除在外了。这种情况下,要做到 L3 级,无论是高速自动驾驶或者低速自动停车,我相信做好摄像头跟雷达之间的融合可能会是更加直接的方式,这也是高通从技术演进路线来看更加着重投入的一个方向。」
目前,高通已经与阿姆斯特丹大学开展战略合作,共建了 QUVA 实验室,专注于发展面向移动领域和计算机视觉的先进机器学习技术。侯纪磊博士表示,Qualcomm AI Research 将不断加强与大学之间的合作,将高通与阿姆斯特丹大学的战略合作模式拓展到全球其它国家和地区。

参考文献
[1] Cohen, T. S., Geiger, M., Koehler, J., and Welling, M. Spherical CNNs. In ICLR, 2018.
[2] Cohen, T. S., Weiler, M., Kicanaoglu, B., and Welling, M. Gauge Equivariant Convolutional Networks and the Icosahedral CNN. In ICML 2019.
[3] Cohen, T. S. and Welling, M. Group equivariant convolutional networks. In ICML, 2016.
[4] Louizos, C., Reisser, M., Blankevoort, T., Gavves E., and Welling, M. Relaxed Quantization for Discretized Neural Networks. In ICLR, 2019.
[5] Yin, P., Lyu, J., Zhang, S., Osher, S., Qi, Y., and Xin, J. Understanding Straight-Through Estimator in Training Activation Quantized Neural Nets. In ICLR, 2019.
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。