想要出专辑、开个唱?试一下 Facebook「歌手变声器」

选自VentureBeat
作者:KYLE WIGGERS
机器之心编译
参与:张倩、杜伟
据说很多人在独处时都会偷偷开小型演唱会,模仿自己喜欢的歌手,幻想自己是 super star。现在 AI 换脸的技术已经非常常见,把明星的脸换成自己的也不是什么难事,但是声音还有些难办。前段时间 AI 换脸张国荣的小哥就被诟病「声音不像」。最近,Facebook 推出了一个歌手「变声器」,仅需不到半小时的音频数据就能实现歌手声音的转换。
去年 6 月份,机器之心报道过,谷歌发布了从声纹识别到多重声线语音合成的迁移学习,利用该技术能够从任意一段参考音频中提取出说话者的声纹信息,并生成与其相似度极高的合成语音(参考:学界 | 现实版柯南「蝴蝶结变声器」:谷歌发布从声纹识别到多重声线语音合成的迁移学习)。这不禁让人想起《黑镜》中利用逝者音频合成语音继续陪伴生者的精彩脑洞。
近日,语音领域又有了新的突破,来自 Facebook 和以色列特拉维夫大学的研究人员在 arXiv 上发布了一份新的研究,可以将一名歌手的声音换成另一个。与谷歌的研究相比,这项技术更像柯南的蝴蝶变声器。
这项技术是在一篇名为「Unsupervised Singing Voice Conversion」的论文中提出的。它采用了非监督学习技术,模型能够从以前未见过且未分类的无标注数据中学习并执行转换。
研究者称,他们的模型仅需 5~30 分钟的歌声就能学会转换,这在一定程度上要归功于一项创新训练方法和数据增强技术。
论文作者写道,「举例来说,我们的方法可以将某个人从自己声音的某些局限中解放出来……这项工作不依赖于文本或标注,也不需要不同歌手之间的对齐数据,也没有对任何文本或音符使用音频副本……虽然现在已经存在音高校准方法、正确的局部音高转换……但本文提供了其他语音特征方面的灵活性。」
该方法基于谷歌开发的自编码器 WaveNet,这是一种用于学习无监督数据集表征的 AI 技术,能够从声音记录的波形中生成模型。它还使用了回译法,即在回译之前将一个数据样本转换为一个目标样本(在这项工作中是指将一个歌手的声音转换为另一个),如果与原始样本不匹配,则调整下一次尝试。
此外,该团队使用了应用「虚拟身份」的合成样本,比其他说话者更接近原歌手,以及一个「混淆网络」,确保系统仍然不依赖于歌手。
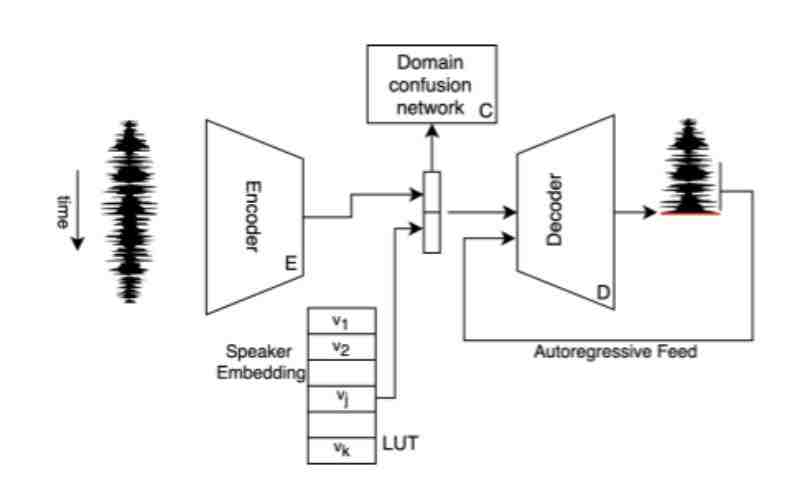
网络架构。研究人员使用编码器 E、域混淆网络 C 和条件解码器 D。说话者的声音嵌入 v_j 存储在 LUT 中。解码器 D 则取决于说话者声音嵌入和每一时间点上解码器输出之间的级联。
AI 训练分为两个阶段。首先,被称为 softmax 重建损失函数的数学函数应用于每位歌手的样本中。之后,通过混合训练歌手的向量嵌入(即数值表示)获得的新歌手的样本在回译步骤之前生成。
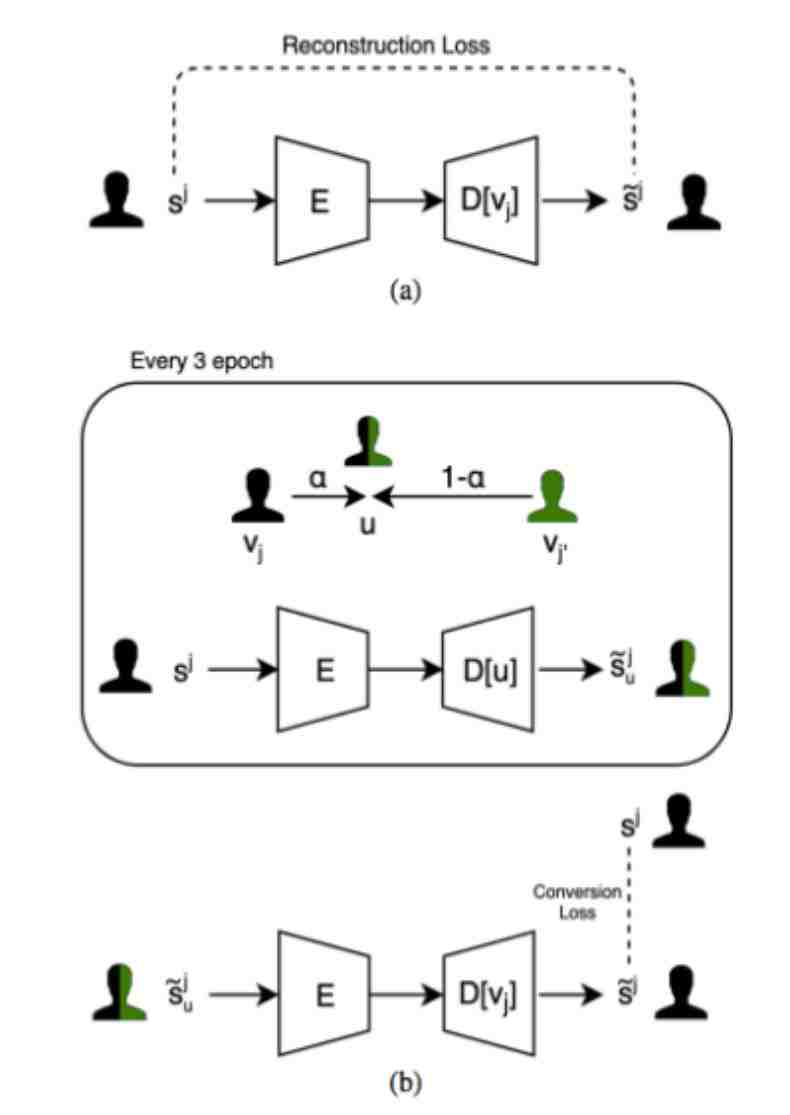
两个训练阶段。图(a)阶段Ⅰ只应用了重建损失函数(显示)和域混淆损失函数(不显示)。使用同一位歌手 j 的自动编码路径来重建样本。图(b)在训练的第二个阶段,通过将歌手 j 的样本转换成结合了歌手 j 和 j'演唱特色的混合声音,生成了合成样本。这些样本在回译过程中被用作训练样本,而在这一过程中,它们又被回译给歌手 j,之后将损失与歌手 j 的原始样本进行比较。
为了扩增训练数据集,研究人员通过反向播放信号以及不知不觉的相位移动来转换音频片段。他们写道:「它以四倍于数据集的大小增加。第一次扩增创建了一首杂序无章的歌曲,但仍可以识别为同一位歌手的声音;第二次扩增创建了一个感官上无法辨别但新颖的训练信号。」
在实验中,研究团队采用了两个公开数据集,即斯坦福的 DAMP 语料库和新加坡国立大学的 NUS-48E 语料库,这两个数据集都包含不同歌手演唱的歌曲。他们首先随机选择了 5 位歌手和 10 支歌曲,并最终使用每位歌手的 9 支歌曲进行训练。其次他们选择了 12 位歌手、每位歌手 4 支歌曲,这一部分数据都用作训练。
研究者接下来让人类评审员以 1-5 的等级判断所生成的人声和目标歌声之间的相似性,同时还通过分类系统自动评估样本质量,因此尽可能地做到客观评估。评审员判断转换后的音频平均分为 4,这已经是比较好的质量了,而自动评分系统发现生成样本和重建样本的识别准确率几乎一样高。
他们下一步的工作是希望实现有背景音乐的歌声转换。
论文:Unsupervised Singing Voice Conversion

论文链接:https://arxiv.org/abs/1904.06590
摘要:研究人员提出了一种歌声转换的深度学习方法。所提出的网络不依赖文本或音符,而是直接将一位歌手的音频转换成另一位歌手的声音。训练是在无任何监督的情况下进行的:无歌词或任何种类的语音特征、无音符、无歌手之间的匹配样本。
所提出的网络使用针对所有歌手的单个 CNN 编码器、单个 WaveNet 解码器以及迫使潜在表征(latent representation)不依赖歌手的分类器。每位歌手由一个解码器依赖的嵌入向量来表示。
为了处理相对较小的数据集,研究人员提出了一项新的数据扩增计划以及基于回译(backtranslation)的新型训练损失函数和协议。研究人员通过评估证明,人声转换能够生成与目标歌手高度吻合的自然歌声。

原文地址:https://venturebeat.com/2019/04/16/facebooks-ai-can-convert-one-singers-voice-into-another/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。