TensorFlow 2.0到底怎么样?简单的图像分类任务探一探

选自Medium
作者:Cameron Cruz
机器之心编译
参与:李诗萌、思源
一个月前,谷歌在 Tensorflow Developer Summit 2019 大会上发布 TensorFlow 2.0 Alpha 版。那么使用 TF 2.0 写模型到底是一种什么样的体验?在这篇文章中,我们将介绍如何用 TF 2.0 打造一个简单的图像分类模型,虽然任务很简单,但它们展示了 TensorFlow 将来的新特性。
好处多多的新版本
从历史角度看,TensorFlow 是机器学习框架的「工业车床」:具有复杂性和陡峭学习曲线的强大工具。如果你之前用过 TensorFlow 1.x,你就会知道复杂与难用是在说什么。
2.0 版本体现了开发人员在改善 TensorFlow 可用性、简洁性和灵活性方面所做出的努力,亮点如下:
- 在不牺牲基于图形的执行的性能优化情况下,默认情况下启用实时执行(Eager Execution);
- API 更简洁、更一致,也更少冗余;
- 更紧密地集成了 Keras 作为高级 API;
- 其他(https://www.tensorflow.org/community/roadmap)。
因此,TensorFlow 2.0 更 Python 化(Pythonic),而且学习起来不那么困难,如果你需要的话,还可以保留较底层的自定义和复杂性。接下来我们要用 TensorFLow 2.0 研究如何在经典的图像分类中应用其高级 API。
在 Colab 上安装 TensorFlow 2.0 Alpha
谷歌 Colaboratory 可以轻易地在云上设置 Python 笔记本。Colab 可以免费使用 GPU 12 小时,因此我一般都将它作为我进行机器学习实验的首选平台。
用 pip 在 Colab 笔记本上安装 TensorFlow 2.0 Alpha(内测版)GPU 版:
!pip install tensorflow-gpu==2.0.0-alpha0
检查是否正确安装了 TensorFlow 2.0:
import tensorflow as tf
print(tf.__version)
# Output: 2.0.0-alpha0
你应该可以正常运行了!如果运行时遇到了问题,请在 Edit>Notebook 的设置中仔细检查 Colab 运行时是否用「GPU」作为运行时加速器。
用 tf.data.Dataset 加载数据
我们用的是 Kaggle 的 Aerial Cactus Identification(仙人掌航拍识别)竞赛(https://www.kaggle.com/c/aerial-cactus-identification)中的数据集。我们的任务是要建立可以分辨航拍图像中是否含有树状仙人掌的分类器。这是 Cactus Aerial Photos 数据集的修改版,Kaggle 将每张图的大小调整为 32*32 像素。

含有仙人掌的示例

没有仙人掌的示例(放大到 4 倍)
从 Kaggle 下载和解压数据集的代码,请参阅:https://github.com/cameroncruz/notebooks/blob/master/Easy_Image_Classification_with_TF_2.ipynb
用 Pandas 将图像及对应标签加载到 DataFrame 结构中,然后用 sklearn.model_selection 按 9:1 的比例分割训练集和验证集。
train_csv = pd.read_csv('data/train.csv')
# Prepend image filenames in train/ with relative path
filenames = ['train/' + fname for fname in train_csv['id'].tolist()]
labels = train_csv['has_cactus'].tolist()
train_filenames, val_filenames, train_labels, val_labels =
train_test_split(filenames,
labels,
train_size=0.9,
random_state=42)
现在我们已经将图像文件名和标签分成了训练集和验证集,可以分别创建相应的 tf.data.Dataset 对象了。
train_data = tf.data.Dataset.from_tensor_slices(
(tf.constant(train_filenames), tf.constant(train_labels))
)
val_data = tf.data.Dataset.from_tensor_slices(
(tf.constant(val_filenames), tf.constant(val_labels))
)
但我们的数据集现在只有图像的文件名,并没有实际图像。我们需要定义可以通过文件名加载图像并执行必要预处理的函数。在这个过程中还要打乱(shuffle)数据集,并对数据集进行分批处理(batch):
IMAGE_SIZE = 96# Minimum image size for use with MobileNetV2
BATCH_SIZE = 32
# Function to load and preprocess each image
def_parse_fn(filename, label):
img = tf.io.read_file(img)
img = tf.image.decode_jpeg(img)
img = (tf.cast(img, tf.float32)/127.5) - 1
img = tf.image.resize(img, (IMAGE_SIZE, IMAGE_SIZE))
return img, label
# Run _parse_fn over each example in train and val datasets
# Also shuffle and create batches
train_data = (train_data.map(_parse_fn)
.shuffle(buffer_size=10000)
.batch(BATCH_SIZE)
)
val_data = (val_data.map(_parse_fn)
.shuffle(buffer_size=10000)
.batch(BATCH_SIZE)
)建立用于迁移学习的模型
迁移学习可以使用现有的预训练图像分类模型来加快训练速度,它只需要重新训练最后一个分类层,并借此确定图像所属类别即可。
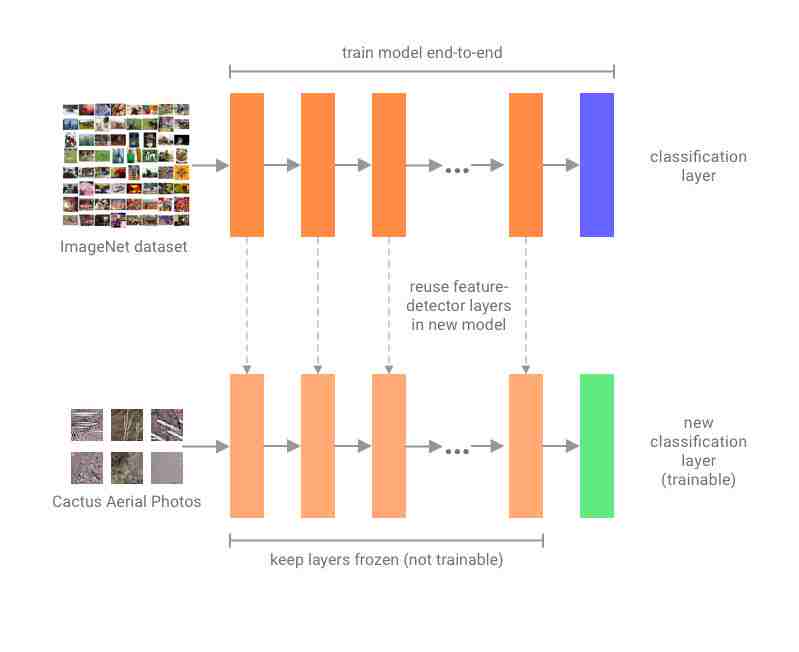
迁移学习图解
现在我们能用 TensorFlow 2.0 的高级 Keras API 快速构建图像分类模型。因为用了迁移学习,我们可以用预训练的 MobileNetV2 模型作为特征检测器。MobileNetV2 是谷歌发布的第二代 MobileNet,其目标是比 ResNet 和 Inception 更小、更轻量级,并可以在移动设备上实时运行。加载在 ImageNet 上预训练且没有最上层的 MobileNetV2,固定其权重,并添加新的分类层:
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3)
# Pre-trained model with MobileNetV2
base_model = tf.keras.applications.MobileNetV2(
input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet'
)
# Freeze the pre-trained model weights
base_model.trainable = False
# Trainable classification head
maxpool_layer = tf.keras.layers.GlobalMaxPooling2D()
prediction_layer = tf.keras.layers.Dense(1, activation='sigmoid')
# Layer classification head with feature detector
model = tf.keras.Sequential([
base_model,
maxpool_layer,
prediction_layer
])
learning_rate = 0.0001
# Compile the model
model.compile(optimizer=tf.keras.optimizers.Adam(lr=learning_rate),
loss='binary_crossentropy',
metrics=['accuracy']
)
注意,这里建议用 TensorFlow 优化器来训练 tf.keras 模型。在 TensorFlow 2.0 中,之前的 tf.train 和 tf.keras.optimizers API 中的优化器已经统一在 tf.keras.optimizers 中,并用升级的 TensorFlow 优化器代替了原来的 tf.keras 优化器。因此,用 TensorFlow 优化器现在成为了更简单也更一致的体验,它完全支持使用 tf.kears API,而且不会牺牲任何性能。
训练模型
TensorFlow 2.0 中的 tf.keras API 现在完全支持 tf.data API,所以训练模型时可以轻松使用 tf.data.Dataset。同样,在不牺牲基于图形的执行的性能优势的情况下,默认情况下会用 Eager Execution 进行训练。
num_epochs = 30
steps_per_epoch = round(num_train)//BATCH_SIZE
val_steps = 20
model.fit(train_data.repeat(),
epochs=num_epochs,
steps_per_epoch = steps_per_epoch,
validation_data=val_data.repeat(),
validation_steps=val_steps)
30 个 epoch 后,模型的验证准确率从 0.63 上升到 0.94。
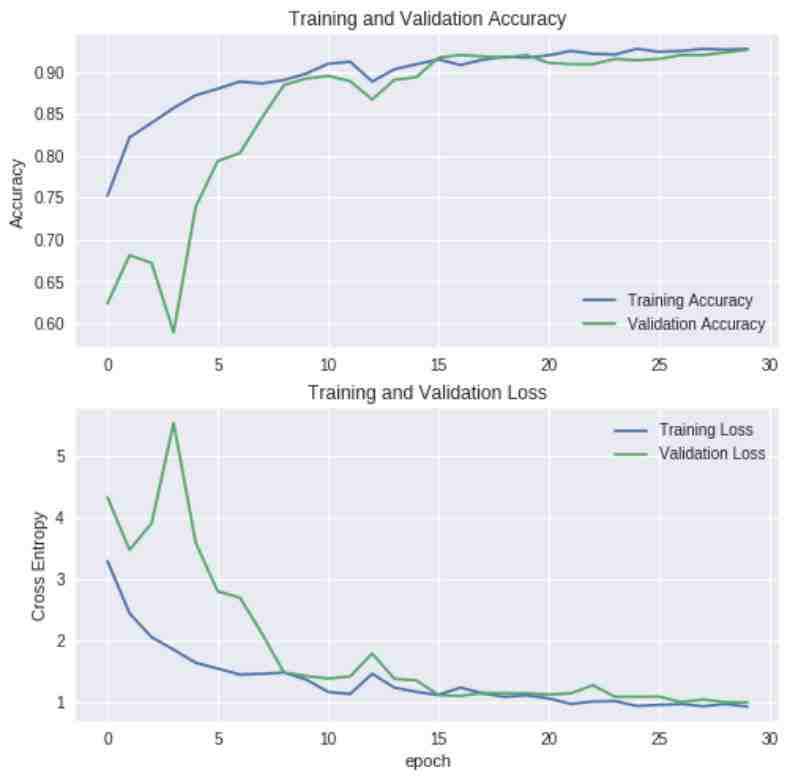
迁移学习 30 个 epoch 的准确率和损失。
模型的微调
接着我们试着进一步提高模型的准确率。当我们在使用迁移学习时,我们只要在固定 MobileNetV2 的情况下训练新的分类层即可。如果一开始没有固定权重,那模型会因新分类层的随机初始化而「忘掉」开始时所有的知识。不过既然我们已经先训练了分类层,那么我们就可以解除对预训练层级的固定,从而根据特定的数据集对模型进行微调。
# Unfreeze all layers of MobileNetV2
base_model.trainable = True
# Refreeze layers until the layers we want to fine-tune
for layer in base_model.layers[:100]:
layer.trainable = False
# Use a lower learning rate
lr_finetune = learning_rate / 10
# Recompile the model
model.compile(loss='binary_crossentropy',
optimizer = tf.keras.optimizers.Adam(lr=lr_finetune),
metrics=['accuracy'])
# Increase training epochs for fine-tuning
fine_tune_epochs = 30
total_epochs = num_epochs + fine_tune_epochs
# Fine-tune model
# Note: Set initial_epoch to begin training after epoch 30 since we
# previously trained for 30 epochs.
model.fit(train_data.repeat(),
steps_per_epoch = steps_per_epoch,
epochs=total_epochs,
initial_epoch = num_epochs,
validation_data=val_data.repeat(),
validation_steps=val_steps)
微调 30 个 epoch 后,模型的验证准确率达到了 0.986。根据准确率和损失的图,模型性能会随着 epoch 的增加而增加。

微调 30 个 epoch 后的准确率和损失。
总结
本文研究了 TensorFlow 2.0 对可用性、简洁性和灵活性的关注,并介绍了新特性是如何 TensorFlow 的学习和使用变得不那么困难的;Eager Execution 和改进的高级 API 抽象化了 TensorFlow 一直以来的复杂性,这些变化使快速实现和运行典型的图像分类实验变得简单。
在撰写本文时,只发布了 TensorFlow 2.0 的 Alpha 内测版,最终版可能要在今年的晚些时候才会发布。显然,TensorFlow 团队正在开发更直观的 TensorFlow。这可能会大范围提高机器学习工程师的生产力,因为在保留底层静态计算图的特征和灵活性的同时,还大大降低了开发的复杂程度。此外,尽管在机器学习实验中 TensorFlow 已经是热门选项了,但对初学者而言更平滑的学习曲线也是更具吸引力的选择。

请在评论中告诉我你对 TensorFlow 2.0 的看法。另外,如果需要本教程的完整代码,请参阅:
- https://github.com/cameroncruz/notebooks/blob/master/Easy_Image_Classification_with_TF_2.ipynb
原文地址:https://towardsdatascience.com/easy-image-classification-with-tensorflow-2-0-f734fee52d13
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。