我是怎么走上推荐系统这条(不归)路的……

选自Medium
作者:Dimitris Apostolopoulos
机器之心编译
参与:shooting、杜伟
什么是推荐系统?有哪些类型的推荐系统?怎么做推荐系统?想知道?可以看看这篇小白文~
在这个系列文章中,我将分享掌握推荐系统的经验,以及围绕推荐系统从低级模型到高级模型的实现。
我还会简要提及你构建推荐系统时将会遇到的挑战以及我所用的解决办法。
最后,我会带你们浏览我追踪模型表现和构建其它机器学习模型时的想法、不成功的尝试和验证框架,以得出成功的方法。
但首先……
什么是推荐系统?
推荐系统可以说是大数据中最常见的应用了,它通过为你的网站推荐内容来改善个人用户体验。
推荐系统是信息过滤系统和人工智能的一部分,旨在预测用户偏好。
我们在哪些地方使用推荐系统?
最常见的领域是产品推荐字段过滤和通过用户的偏好来学习,以便将这些知识应用于他人。
我学习推荐系统的初衷
虽然我很享受生活,但我觉得…嗯,太安逸了。所以我决定改变一下这种状态。
然后我决定挑战点什么,你懂的。
比如漫游数据科学世界和征服人工智能什么的。
呵呵,挑战。
就是那种你后悔也为时晚矣的东西。
不过你看,我这不是冒险跳进来,和「海怪」斗争,最后存活下来了吗?也许,你可以听听我——「水手辛巴达」讲讲这个跌宕起伏的故事。
大概是一年前吧,我工作的电子邮件营销和自动化公司(Moosend)给我分配了一个全新的项目。
其理念是创建一个适合且适用于每个电子商务平台的数据驱动推荐引擎。这个通用系统要根据用户和产品的交互产生个性化的产品推荐。
这个项目的挑战之处在于它必须是完全动态的,能够适应各种模式,即季节性购买模式(如圣诞节、光明节、复活节等送礼期间),同时还要实现收益最大化。
如何理解推荐引擎?
每次接到新项目后,我做的第一件事就是了解它的基本信息;它是用来做什么的?什么时候用?系统的结构是什么?它可能具有的多样性和可扩展性?

总共有不同类型的推荐系统,而你选择哪种要取决于你接近客户的策略。
现在是数据的最好时代。过去从来没有像现在这样,这个世界为数据所驱动。大部分最大的电子商务网站依靠数据驱动决策系统来扩大销售。
而个性化的产品推荐是人工智能送给电子商务的礼物,因为它们可以帮你提高点击率和销售率。
就像我说的,AI 推荐系统有五种不同的类型:
基于内容的引擎:根据相似产品的属性(即每种产品的特性)来识别相似产品。
每个产品都有其属性(例如,手机的属性是屏幕大小、价格、相机、软件等),我们试图找出最相似的属性。
通过这种方式,我们给偏好具有特定属性的手机客户推荐相似的手机。
协同过滤引擎:识别相似客户的偏好,它基于这样一种概念:行为相似的人有相似的兴趣。
在这类系统中,我们用客户的交互来代表他们,预测他们对每个产品产生兴趣的概率,即客户真正欣赏推荐给他们的产品的可能性。
因此,我们可以通过给最相似的客户推荐产品来接近新客户。
混合系统:结合了基于内容的系统和协同过滤系统。
对两个模型中每个给定的产品进行评分,并对每个结果进行加权;最终的推荐结果来自两个分数的线性组合。
关联规则或购物篮分析引擎与先前几种系统略有不同。
有了大量的交互数据集,我们可以找到经常作为序列一起购买的物品的模式;例如,有人在购物车里加了咖啡,但没加糖,我们就会给他推荐糖。
重复购买引擎:预测客户购买特定产品的具体时间或大概时间。
这种算法使用产品周期、购买历史和日期统计来预测未来购买日期。
例如,如果有人买月抛的隐形眼镜,我们可以每隔 30 天为他推荐同样的产品,如果他忘记购买的话。这样,就鼓励客户一直在我们店里买眼镜了。
协同过滤
为了更新你的记忆,这种推荐引擎会通过客户的产品交互(购买、产品视图和添加到购物车产品)来尝试识别具有相似兴趣的客户。
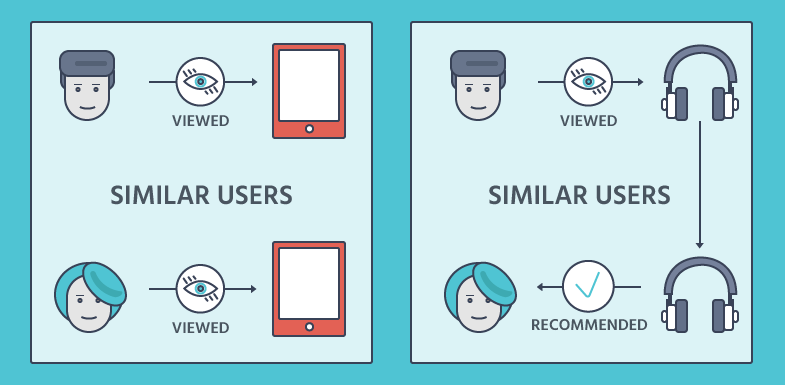
你可以用一两种方法实现协同过滤:基于记忆或基于模型的方法。在两种方法中,我们都用客户的交互行为来代表他们,就像向量格式化矩阵一样。
在基于记忆的方法中,你要测量所有向量(客户)彼此之间的距离,然后根据他们最相似的地方推荐产品。
而在基于模型的方法,即广为人知的矩阵分解模型中,我们要识别数据中的潜在因子。
在统计世界中,潜在因子不是我们直接观察或测量的变量,而是一组在较低维空间中解释(描述)其它变量及其关系而不丢失信息的变量。
而在推荐系统中,潜在因子发现和解码每个客户的模式,以识别他们之间的相似性。
推荐系统模型 #1(我的第一次尝试)
我想出来的第一个模型是标准的矩阵分解模型。
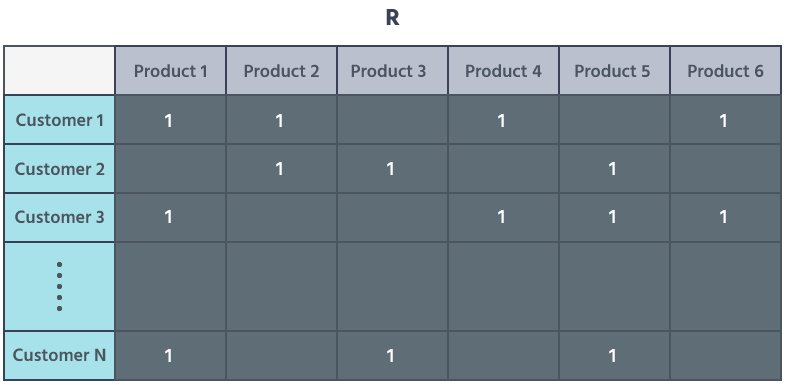
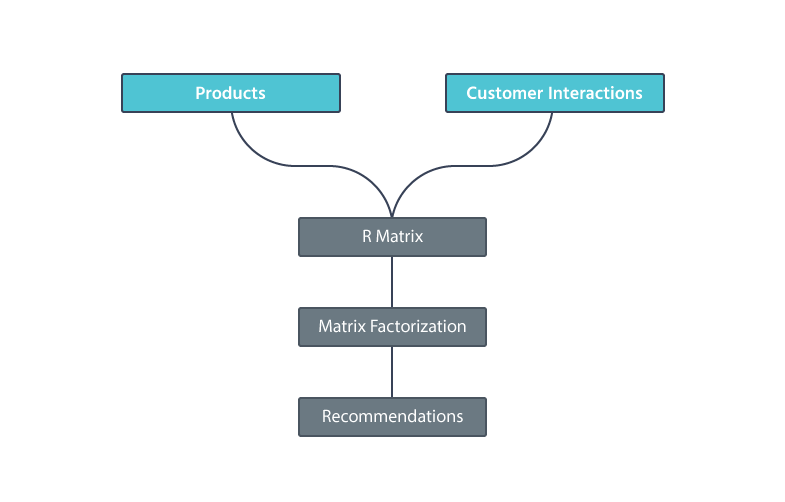
在这个案例里,我们在二维稀疏矩阵 R 中用客户的产品交互来代表他们;稀疏矩阵是一种高效计算和高效存储的方式,可以将大量数据存储在一起并准备处理。
矩阵中的行代表客户,列代表像向量一样的产品,然后我们在客户-产品交互单元中填上 1。
而在有产品但没有客户交互的单元格则是空的,如下所示:
下一步是将 R 矩阵分为两部分,一部分针对客户(P),一部分针对具有潜在因子的产品(Q)。然后,我们用 lambda 函数微调这两个矩阵并根据原始 R 矩阵的值测量误差率。当误差率从给定阈值开始下降时,我们中断这个过程。

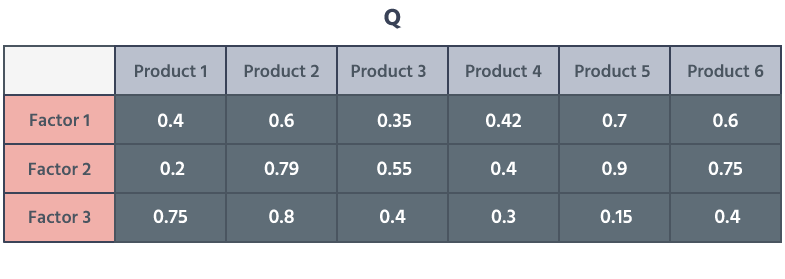
为了格式化 R-hat 矩阵,我们计算了 P 和 Q 的点积。在线性代数中,点积是矩阵乘法的结果。
最后一步是推荐一组根据特定客户的最高购买概率排序的产品。

性能指标
为了监测模型的性能,我们要测量模型生成的推荐系统的质量。
在推荐系统中,我们用 Precision@k 和 Recall@k 测量了系统的性能,这两个指标广泛应用于信息检索场景。
精度被定义为客户已经与之交互(浏览、添加到购物车等)的推荐项目的数量,除以推荐集 k 中的项目数量。

召回是客户已经与之交互的 @k 推荐项目数量,除以客户已经与之交互的项目的总数量(即使在推荐集之外)。

我们还使用了另一个指标:准确率分数,以测量模型的整体性能。我们把准确率分数定义为客户已经与之交互(至少一次交互/集)的推荐集总和,除以客户推荐总数。

在所有模型中,我们在前 5 个(k=5)推荐产品中测量了模型的性能。
模型的优缺点
前方预警:
模型的缺点大于优点。
实现较好的方面是模型和进程非常直接,对那些了解基础知识且具有领域经验的人而言很简单。此外,该模型的实现可以使我们将所有信息放入单个「训练好的」矩阵,为用于生产的推荐做好准备。
那么不好的方面是什么呢?考虑到矩阵稀疏性,当新商店加入推荐引擎时,计算和耗时会呈指数增长。
因此,经过数十个网站后,该系统将消耗大量内存,并且需要花费几天时间进行调整和正常运作。
数据在产生个性化产品推荐时最为重要;举例而言,大量的中小商店没有足够的交互数据来产生自己的个性化推荐。

在观察到令人失望的结果以及想通了研究系统目的之后,我决定改变方向,*专注于如何处理和发布信息*。
如此一来,我可以帮助到数据薄弱的较小商店,同时减小交互矩阵的规模。
在下一篇文章中,我将向大家介绍如何自动融合产品信息以及不同店铺之间的交互。

原文链接:https://medium.com/moosend-engineering-data-science/the-road-to-recommender-systems-d6bb79bd169d
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):[email protected]
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:[email protected]
阅读原文 最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。