首个以AI命名的网络的自白

我,在网络圈儿还算是一个新人。
不过,有一点让我深感自豪,因为我是第一个以AI命名的网络。
在这里先卖个关子,不告诉你我的名字,或许通过以下的介绍,你能猜出个八九不离十。
以AI之名
下面我要讲述的是自己生命旅程中的一件大事,就在上个月,我荣幸地通过了国际权威测试机构Tolly Group的对比测试验证。就像学生要参加升级考试,专业人员上岗要考取各类证书,在我诞生到现在不长的时间里,虽然我也获得过林林总总许多证书,但是闯过Tolly Group测试这道关对我来说还是意义重大。
测试结果显示,在数据中心面向AI时代的典型业务场景中,我相比业界其他主流厂商的组网方案,性能全面领先,引领了数据中心网络迈向智能无损的新纪元。
什么?你说我的口气有点大?Tolly Group的权威性在网络圈里儿是有口皆碑的,通常来说只有通过Tolly Group严格考核的网络设备,才能被归到“顶尖”的行列。因为我AI的新身份,在参加Tolly Group测试前,还真有点忐忑,不过最终仍过五关斩六将,整体性能表现优于业界平均水平。就像是花样滑冰运动员,不仅滑行、旋转、抛跳动作质量高,而且在测试专家的心中留下了很高的印象分。作为“监考官”,Tolly Group创始人兼首席执行官Kevin Tolly对我零丢包、低时延和高吞吐的表现给予了充分肯定。他也相信,我能引领AI时代数据中心网络的建设潮流。
智闯三关
说到这次参与Tolly Group评测的经历,现在回想起来仍感觉惊心动魄,精彩纷呈。Tolly Group参照实际应用需求设置了三大测试场景——人工智能/机器学习(AI/ML)训练、高性能计算(HPC)以及分布式存储,每个测试场景都安排了有针对性的测试内容。这阵势有点像是少林武僧出寺之前要闯过木人巷的种种机关。由于我特殊的出身,类似的考验已屡见不鲜,关键是我对自身的素质和能力充满信心,所以能够坦然应对。
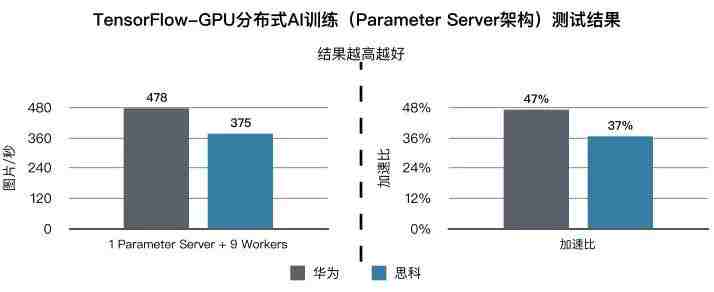
第一关,我要挑战的是“AI训练效率”。
本关的难点在于,在深度学习的AI训练模型中,为满足处理海量非结构化数据的要求,计算单元从CPU发展到GPU,计算性能提升100倍;存储介质从HDD演进到SSD,存储性能提升100多倍。然而,网络仍停留在传统以太网阶段,通信时延占整个任务时间的50%以上。此外,服务器采用TCP/IP以太传输协议需要服务器内核处理,也会占用大量CPU资源。RDMA(Remote Direct Memory Access,远程直接数据存取)协议虽然可以减少时延、提升CPU利用率,但有个很大的缺点,即对网络丢包异常敏感。传统以太网0.1%的丢包,会导致RDMA协议处理能力下降50%,使得AI训练的计算能力下降50%。因此,满足RDMA协议对网络丢包的严苛要求成了亟待解决的难题。
在模拟真实的网络环境中,服务器采用100G链路接入网络,接入交换机的上下行收敛比1:1,训练软件采用TensorFlow-GPU 1.10,训练算法采用VGG16 PS-Mode,训练样本采用ImageNet 2012图片库。
测试主要是针对我在RoCEv2(RDMA over Converged Ethernet)网络下使用CNN(Convolutional Neural Networks,卷积神经网络)模型分布式深度训练的性能。CNN通过模拟人类大脑的多层神经网络,将数据量庞大的图像识别问题不断降维,明显降低识别错误率,是广泛使用的业务模型。由于我是智能无损数据中心网络,在服务器通过AI算法深度学习识别图片的100Gbps时,可以完全做到零丢包。
我的闯关成绩是,GPU每秒可以学习识别478个图片,高于业界27%的水平。
第二关,主要考验我的身手是否敏捷。
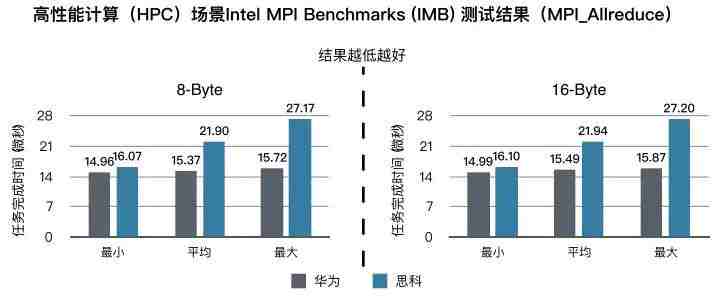
本关的难点是,高性能计算已经渗透进生活的方方面面,从环境监测、医药到银行、证券、税务,从搜索引擎、流媒体、动漫渲染到生命科学、石油勘探、决策支持系统等,几乎包罗万象。而这些行业应用都需要在包含海量数据的数据仓库基础上,进行深度地数据挖掘和数值仿真,模拟真实情况,为决策和诊断提供依据。统计学认为,标准差可以反映采样数据的精确度,是检验模拟真实性的重要指标。但是以前只能靠人工完成采样数据的标准差统计分析,工作量巨大且易出错。如今高性能计算系统的MPI AllReduce模型可以代替人力完成机械的重复性劳动,实现大数据分析。
MPI AllReduce模型采用分布式系统,也就是有一台服务器充当“总管”的角色,将计算任务分解成多个子任务交给其他众多服务器处理;当计算任务结束时,这些服务器同时把完成的子任务统一交给“总管”服务器,这时网络中传输的数据量会瞬间撑爆网络管道,造成拥塞和丢包。传统以太网为了防止数据丢失,会把这些数据放入缓存队列排队,并反复不断地重新传送,大大延长了网络传输时间,进而导致计算任务完成时间拖延。因此,平衡好网络丢包和时延成了令人头痛的难题。
测试环境中服务器配置RDMA网卡,100G链路接入网络,接入交换机上下行收敛比1:1,操作系统采用Ubuntu 16.04,用Intel MPI Benchmark工具测试。高性能计算一般会把任务分解成8字节或者16字节的子任务。此时身处测试环境中的我,再次实现了零丢包,闯关成绩为,完成一次AllReduce计算任务的通信时延比业界其他友商缩短了30%。
第三关,我在性能方面的硬实力得到了充分展现。
本关的难点在于:在分布式存储场景中,数据被分散存储在多个设备中,虽然提高了系统的可靠性、可用性和扩展性,但是时延是个大问题,包含介质访问时延、网络通信时延和其他时延。传统以太网的通信时延已占到存储处理时间的50%以上。通信时延大,存储访问I/O端口的时间就长,每秒可以访问的I/O端口数就少,存储访问I/O端口的IOPS性能就会受到严重制约,数据的实时存储也就无从谈起。因此,降低网络时延、提升存储IOPS性能成为严峻的挑战。
在测试环境中,服务器操作系统采用Ubuntu 16.04,25G链路接入网络;存储节点安装NVME SSD硬盘,100G接入网络;接入交换机上下行收敛比1:1;使用FIO工具构建70%背景流。在实际测试中,我不负众望,将存储介质的IOPS性能发挥到极致,在采用相同存储介质的情况下,存储的IOPS性能比业界平均水平提高30%以上。我再以优异的成绩过关。

我的闯关秘籍?可以剧透一点儿,CloudEngine系列数据中心交换机内嵌AI芯片,基于Spine-Leaf网络架构,采用独创的iLossless智能无损交换算法,实现定时采集流量特征和动态基线智能调整,最终实现零丢包、低时延、高吞吐的极致性能,有效提高客户的ICT投资收益率。
还要补充一点,Tolly Group将我与思科Nexus交换机组网的性能进行了对比,双方均基于RDMA over Converged Ethernet(RoCEv2),在所有三大场景中,我的性能全面占优。
真实身份揭秘
Ok,我的闯关故事到这里就告一段落了。是不是有些人已经猜出了我的名字?没错,我就是面向AI时代的华为CloudFabric智简数据中心网络子方案“AI Fabric智能无损数据中心网络”。
我们已经进入了AI时代。华为GIV(Global Industry Vision)预测,到2025年,企业对AI的采用率将达到86%。AI将成为企业重塑商业模式、提升客户体验和开创未来的核心推动力,同时也将驱动ICT基础设施的变革。我诞生于2018年华为全联接大会,虽然年轻,但是已经肩负起帮助企业构建高性能数据中心、加速企业AI业务商用进程的责任。
Tolly Group的这次测试(点击文后“阅读原文”可观看完整测试报告),让我对自己的能力有了更全面的认知,增强了自信。面对AI时代数据中心的高性能计算、人工智能/机器学习和分布式存储三大典型应用场景,我可以自豪地喊出:我行!我行!我行!

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。