深度解读Apache Hadoop生态圈:哪一种流架构模式才最适合你的需求?


原文作者:Ted Malaska
成功生产开发的先决条件在于:评估好哪一种流架构模式才最适合你的需求。
Apache Hadoop 生态系统已成为企业实时地处理和挖掘大数据的首选。 Apache的Kafka, Flume, Spark, Storm, Samza等技术在不断地推进新的可能。在这种情况下,人们很容易泛化大规模实时数据案例,但其实他们可以细分为几种架构模式,Apache系统里的不同组件适合于不同的案例。
这篇文章探讨四种主要的设计模式,案例来自于企业客户的数据中心的实例,并解释如何在Hadoop上实现这些架构模式。
流处理模式
四种流模式(经常串联使用)为:
流采集:低延迟将数据输入到HDFS,Apache HBase和Apache Solr。
基于外部环境的准实时事件处理: 对事件采取警报,标示,转化,过滤等动作。这些动作的触发可能取决于复杂的标准,例如异常监测模型。通常的使用案例,例如准实时的欺诈监测和推荐系统,需要达到100毫秒以内的延迟。
准实时事件分割处理:类似于准实时事件处理,但通过将数据分割获得一些好处—例如将更多相关外部信息存入内存。这个模式也要求延迟在100毫秒以内。
为整合或机器学习使用的复杂拓扑结构:流处理的精髓,实时地通过复杂而灵活的操作从数据中获取答案。这里,因为结果通常依赖于一段窗口内的计算,需要更多的活跃的数据, 于是重点从获得超低延迟转移到了功能性和准确性。
接下来,我们将介绍如何用可检测的,可被证明的和可维护的方式来实现这些设计模式。
流采集
传统上,Flume是最为推荐的流采集系统。它的源和池囊括了所有关于消费什么和写到哪里的基础(关于如何配置和管理flume,参考Using Flume,由O’Reilly 出版的Cloudera工程师/Flume 项目管理委员会成员Hari Shreedharan编写)。
因为playback和replication等特性,Kafka也变得非常受欢迎。由于Flume和Kafka有重叠的目标,他们的关系常常令人困惑。他们如何配合?答案很简单:Kafka的管道和Flume的通道类似,由于上述两点特性,Kafka是一个更好的管道,因此可行的方法就是用Flume作为源(source)和池(sink),而Kafka是中间的管道。
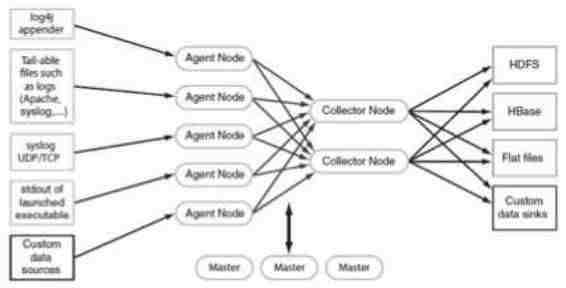
下图阐明kafka如何作为Flume的上游数据和下游目的,或Flume管道。

下图的设计是具有大规模拓展性,经过实战检验的架构设计,它由Cloudera 管理器监控,有一定容错能力,并且支持回放。

值得注意的一件事就是,这个设计多么优雅地处理故障。Flume 池从Kafka消费者群里取回。通过Apache zookeeper的帮助,Kafka 消费者群取回topic的位移。如果一个Flume池发生故障,Kafka消费者将把负载重新分发到其他的池中。当那个池恢复了,消费者池将重新分发。
基于外部环境的准实时事件处理
重申一下,这个模式的适用案例通常是观察事件流入然后采取立即动作,可以是转化数据或一些外部操作。决策的逻辑依赖于外部的档案或元数据。一个简单并且可拓展的实现方法是,在你的Kafka/Flume架构中添加源(Source)或池(Sink)Flume拦截器。只需简单配置,不难达到低毫秒级延迟。
Flume拦截器允许用户的代码对事件或批量事件进行修改或采取动作。用户代码可以与本地内存或外部Hbase交互,以获取决策需要的档案。Hbase通常可以4-25毫秒内给予我们信息,根据网络状况,模式概要,设计和配置而有所不同。你也可以将Hbase配置为永远不停止服务或被中断,即便在故障情况下。

这一设计的实现除了拦截器中应用的具体逻辑几乎不需要编程。Cloudera管理器提供直观的用户界面,可以部署这个逻辑,包括连结,配置,监测这一服务。
准实时基于外部环境的分割化的事件处理
下图的架构(未分割方案),你将需要频繁查询Hbase,因为针对某一事件的外部上下文环境在flume拦截器的本地内存中装不下。
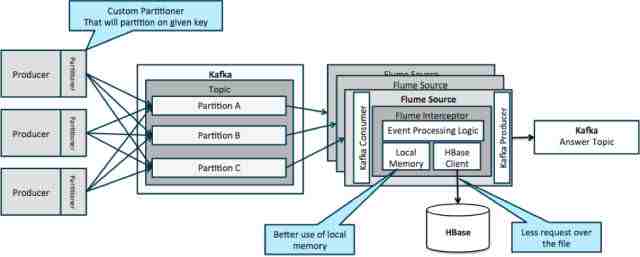
但是,如果你定义一个键值来分割数据,你将可以把数据流匹配到相关上下文的一个子集。如果你将数据分割成十部分,那么你只需要将十分之一的档案放入内存里。 Hbase是快,但本地内存更快。Kafka允许你自定义分割器来分割数据。
注意,在这里,Flume并不是必须的;根本的方案只是一个Kafka消费者。所以,你可以只用一个YARN消费者或只有Mapper的MapReduce。
针对集成或机器学习的复杂拓扑
到此为止,我们探索了事件层面的操作。然而,有时你需要更复杂的操作,例如计数,求平均,会话流程,或基于流数据的机器学习建模。在这种情况,Spark流处理是最理想的的工具,因为:
和其他工具相比,Spark易于开发
Spark丰富简明的API让建设复杂拓扑变得容易
实时流处理和批处理的代码相似
只需很少的修改,实时小量流处理的代码就可以用于大规模离线的批处理。不仅减少了代码量,这个方法减少测试和整合需要的时间。
只需了解一个技术引擎
培训员工了解一个分布式处理引擎的机制和构件是有成本的。使用spark并标准化将会合并流处理和批处理的成本。
微批处理帮你更可靠地进行拓展规模
在批处理层面的应答将允许更多的吞吐量,允许无需顾忌双发的解决方案。微批处理也帮助在大规模下高效发送修改到HDFS或Hbase。
与Hadoop生态系统的集成
Spark与HDFS,Hbase和Kafka有深度很深的集成。
无丢失数据的风险
由于有了WAL和Kafka,Spark流处理避免了故障时丢失数据的风险
易于排错和运行
在本地的IDE中你就可以对你的spark流处理代码进行排错和逐步检查。而且,代码和普通函数式程序代码类似,对Java或Scala程序员来说,无需花很多时间就能熟悉。(Python也支持)
流处理是天然状态化的
Spark流处理中,状态是“第一公民”,意味着很容易写基于状态的流处理应用,对节点的故障可恢复。
作为实际的标准,Spark现在正在得到整个生态系统的长期投入
在写此文时,spark在30天内已有700次左右的提交—和其它框架相比,例如Storm,只有15次的提交。
你可以使用机器学习的库
Spark的MLlib库越来越受欢迎,它的功能只会越来越强大。如果需要,你也可使用SQL。通过Spark SQL,你可以为你的流处理应用添加SQL逻辑,从而简化代码。
结论
流处理和几种可能的模式有很强大的功能,但正如你在这篇文章所了解,你可以通过了解哪一种设计模式适合你的案例,从而最少量的代码做非常好的事情。
原文地址:http://blog.cloudera.com/blog/2015/06/architectural-patterns-for-near-real-time-data-processing-with-apache-hadoop/
作者介绍: 译文作者:李若冰,硕士毕业于卡内基梅隆娱乐技术中心,本科就读于浙江大学计算机专业。现在微软Xbox从事后端开发,数据发掘和搜索服务方面的工作。
原文作者: Ted Malaska ,Ted Malaska是Cloudera解决方案架构师,Spark,Flume和Hbase的贡献者,O’Reilly书籍 《Hadoop 应用架构》的合作作者。

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。