Twitter设计:分布式系统“推拉模式”的优化


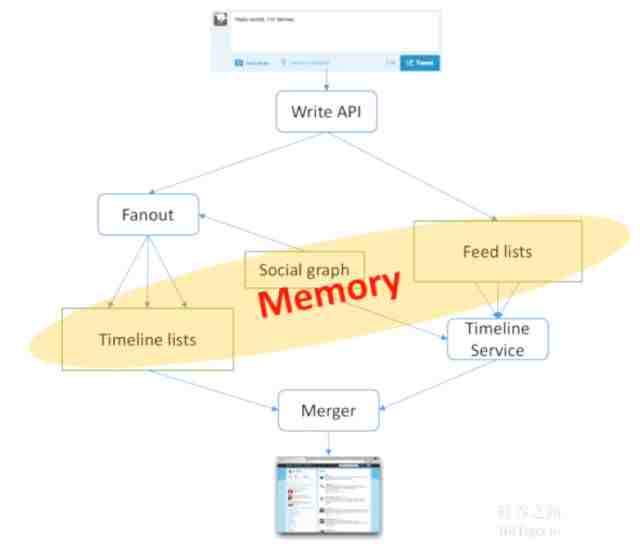
我们在上一章最终给出了一个推拉结合的模型,左边属于推模型 ,写进一个消息可以发给所有关注我的人;右边属于拉模型,当我发出消息以后,只写到我自己的list里面,每个人可以过来读取;而Merger将推拉模式结合到一块得到这种结果,针对这种架构我们怎么做优化呢?如何使它更快?

变更快的方法实际上非常简单,第一个就是内存,任何一个分布式系统,它的性能取决于4个因素,第一个是计算时间,第二个是数据传输时间,第三个是任务调度时间,最后除以并发度。所以减少数据传输时间的方法就是放进内存里,这比硬盘快10倍以上。当我们把所有核心数据全部放进内存之后就会变得很快,但如果把东西放进内存里,内存会占据多少呢?
为了计算这个值,我们首先要做出如下假设。
Assumption:
1 billion users
Average feed size:50 tweets
Average timeline size:1000 tweets
Tweet size:200B
Average followers=30
针对这个估算,我们需要的内存有多少呢?大家可以计算一下
Size of timeline lists=1 billion*10^3*200=200T
Size of feed lists=1 billion*50*200=10T
Size of social graph=1 billion*30*2*8=480G
这里的2是双向的意思,8是假设我们存2个ID,会存8B。实际上会比8多,但由于跟前面相比差距并不很大,算出来之后发现真正占内存的是Timeline list,200T,这说明是不可行的,怎么可能有200T的内存呢?所以需要优化,怎么来优化呢?
有很多优化的方法,大家可以自己想一想,
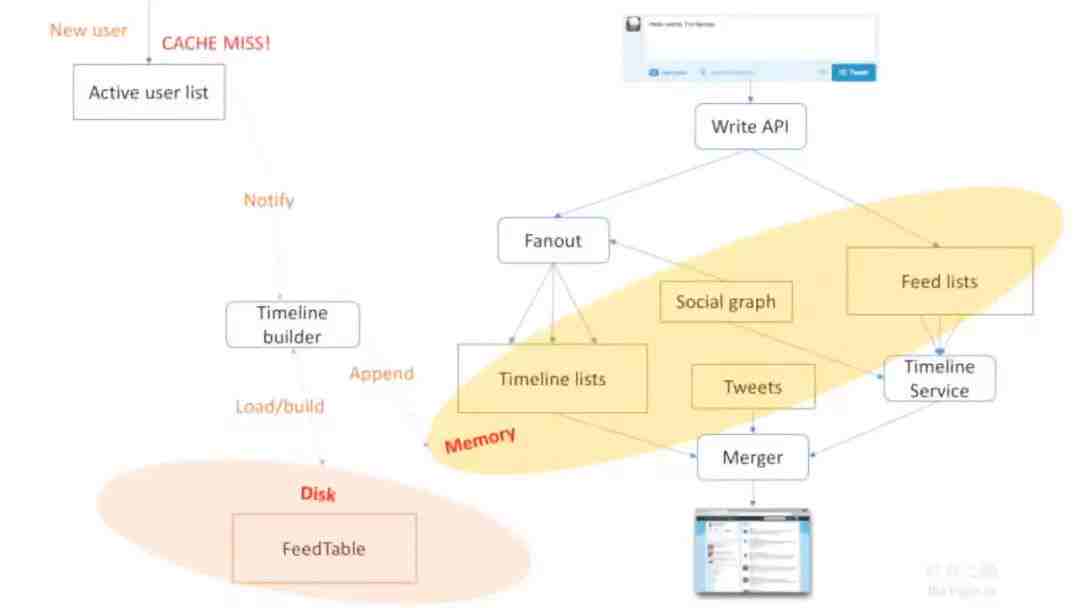
第一个省空间的方法是之前讲过的,你说有十亿个用户,但可能你的系统已经崩溃没有人用了,可能每天只有1百万个活跃用户,所以我们可以只存活跃用户的,非活跃用户之后再说。这样会不会判定错呢?我们可以把过去1个月内的访问用户再缓存下,这样一定程度上降低了miss率,同时也极大减少了空间的占据。所以无论计算什么,只计算当前active user的数据,虽然计算时可能还需要一些过滤,但我们会把整个内存降低很多,降低多少呢?
Assumption:
Weekly active users:100 million
Average feed size:80 tweets
Average timeline size:500 tweets
Tweet size:200B
Average followers=20
所以这样一来:
Size of timeline lists=100 million*500*200=10T
Size of feed lists =100 million*80*200=1.6T
Size of social graph=100 million*20*2*8=32G

后面两个已经很小了,已经可以放进硬存里, 但第一个还是特别大,仍然需要优化,但还可以怎么优化呢?
我们发现只有Tweet size没有优化,那怎么做呢?答案是把内容和ID分开。前面Tweet内容是200B,但传来传去发现根本不需要200B,只保存Tweet ID就行了,只是在最后一步,返回给用户之前在里面把Tweet装配成完整版就可以。所以我们在timeline lists,social graph,feed lists里只存Tweet ID,内容只是在最后一步Merger里保存进去,所以tweets放进Merger里了,这样占用多少内存呢?
Assumption:
Weekly active users:100 million
Average feed size:80 tweets
Average timeline size:500 tweets
Tweet size: 20B=userID(8)+tweetID(8)+indicators(4)
Average followers=20
这样一算,就会发现Timeline lists变成1T,
Size of timeline lists=100 million*500*20=1T
Size of feed lists=100 million*80*20=160G
Size of social graph=100 million*20*2*8=32G

1T是什么概念呢?1个好的机器差不多250G内存,所以4个机器就可以装下。做一个分布式的存储就可以存下1T架构,那看似Twitter很复杂的架构,拿十几台机器就可以把所有消息,包括timeline lists和social graph 都存下。但实际上,这里面还有需要计算的,tweets本身也要存里面,这个到底占多少大家可以自己计算。
我们这个架构目前看来能够存下来,但仍然存在很多问题需要去考虑。
问题1:如何处理缓存缺失(Cache Miss)?
很多用户可能一直没来,结果今天突然来了,他的数据没有怎么办?这时我们需要做一个过程,加一个新激活用户的过程。
举个例子,一个新用户来了,就会进入active user list,立马需要启动CACHE MISS 过程,去通知Timeline builder,它会从硬盘里读出用户的所有数据,并且build起来放进内存里。你可能认为这个过程比较慢,会占用你1-2秒时间,但这是没关系的。因为当用户登录的时候,他还没开始看自己的内容,当用户输入密码登录的瞬间就可以启动Timeline Builder,当用户已经登录完开始访问首页时,往往已经经历过3-5秒,这给了充足的时间把数据放进内存里,用户就可以立刻看到,感觉不到Cache Miss,也能够极大地减小内存的使用率,这是一个非常有趣的过程。
问题2:Timeline Builder 接口如何做?
SNAKE(Scenario, Necessary, Application, Kilobit, Evolve)原则里的A,在微观角度来说就是应用接口,这个接口的定义往往体现出Engineer的能力,为什么呢?接口需要能够通用,能够普适,而且能够表达意思,所以要建好Timeline builder的接口。
举个例子,最简单的是得到所有用户的Timeline list,相当于把这个用户的所有关注好友的Feed组合到一起形成Timeline list,那需要怎么做呢?为了防止查2次,要定义一个通用接口,传入一堆用户ID list,并输出这些ID list所发布的Feed集合,这就是Timeline builder的基本接口,那这个好吗?
其实不好,因为还有很多需要去考虑。首先,没有必要取全部的ID list,可能取最近的800个就行,如果取全部计算会特别慢,那要取多少个?有时候800,有时候800-1600是不一样的。所以还需要传个参数k告诉它我需要取最近多少个,这样就结束了吗?还可以再优化,举个例子,我可以说取最近1年的,或最近1个月的,1个月之前的就不用发送了,就算不到500个也不需要再发,这样加上endTime能极大减少我的计算。这样可以了吗?还可以再加上begin Time,什么意思呢?可能说我之前想取最近1个月的,结果还想取更多,那就取1-2个月,那要怎么办呢?也可以传个参数范围。
Get(userIDList)
Get(userIDList,k)
Get(userIDList,k,endTime)
Get(userIDList,k,endTime,beginTime)
所以在这个过程中不断添加一些configuration,你的系统就变得集中性更好,但是如果我一开始做就需要这么复杂吗?不需要,只要做到第二步就够了,大家可以根据实际情况不断去优化。但需要先有根秤,通过不断的修改接口来普适的做这个东西。这是大家应该学会的基本能力,也是当你自己做系统测试或是面试回答接口设计时需要不断考虑的。你上来就用第4个,好不好呢?同样不是很好,因为事物是由简到繁的,上来做一个繁的,不见得你能力好,反而觉着你over thinking,所以根据需求不断的进化,并且讲出你的理由。很多时候大家在面试,其实是模拟一个真实的场景,真实场景中并不是一次达到最优结果,而是不断的优化得到你的最优结果,这才是你做系统设计面试题真正的核心,就是不断生长得出你的结果而且把你的思考讲出来让大家信服。
问题3:Timeline Builder 数据是什么样子?
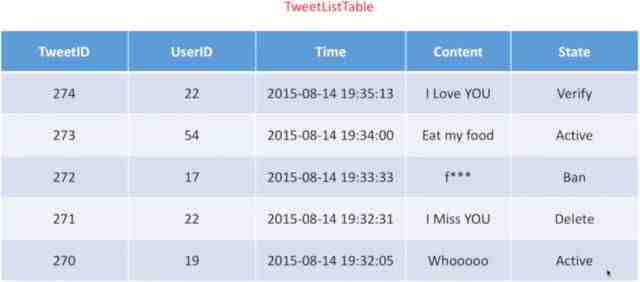
我们会想存很多数据,Tweet应该存哪些呢?TweetID是消息的ID,UserID是谁发的,还有时间,内容,另外还有一个状态。什么状态呢?比如你在新浪微博里发一个消息,看着发出来了,其实并不是,后台还需要验证,有验证过程中,活跃状态中,甚至有些东西被删掉了,还有些管理员把你Ban掉了这些都有可能,所以针对所有这些消息,往往需要一个状态码标记出来,这就是我们状态符。这么么存真的好吗?其实不用存这么多,当在计算过程中,应该把空间尽量节省。这里面最不可或缺的是什么,我认为是两个,一个是TweetID,一个是UserID,所以这两个是你在中间需要计算的,在保存时只存ID就行了,那再加一列状态行不行?也可以,有时候把State放在里面也比较好。

针对这样一个TweetListID,应该怎么存到硬盘上呢?那就要想一个存储策略。讲这个之前强烈建议大家学习GoogleFileSystem,BigTable和Mapreduce这三部分,因为只有理解了它们的设计核心,才能够深刻的理解在设计Twitter底层文件存储的方式,它们是异曲同工的,所以一个好的设计能够激发你想出更美好的设计,那我们来看一看Twitter是怎么设计的。
问题4:如何将TweetListTable保存到磁盘上?
为了在底层保存,首先要多备份,每个存多份,防止数据丢失,我们认为一块一块的数据存在好几个机房里面,两个是在同一个机房数据中心里,一般是跨机架的,一个是在另外的机房里。并且一个机房在加州,一个在东部,这样保证数据不容易丢失,就算某个仓库挂掉也没有问题,每个存3个副本,这都是很容易理解的。
那难点是里面具体的某一块应该怎么存呢?我们讲过应该存两列数据,一列是TweetID,一列是UserID。最简单的方式肯定是说TweetID按照一个序列来排序,后面是UserID,这是最简单想到的方式,查的时候不断在里面查就行。
然后一些细节,比如每一块多大呢?我们会给它分装成64M,为什么呢?这是基本的块大小,而且是2的n次方,便于底层管理。
但现在有个趋势,一般会把块放大点,会放到120-156,往往这样效果很好。由于它是按Tweet排递,实际上Twitter本身是个时间序关系,可以给它起名叫时间胶囊。之所以按照TweetID逆序排,是因为要lookup方便,因为往往我们查最新的,所以把ID大的放在前面。

问题5:如何查找时间胶囊?
讲了怎么写,那还要知道如何读,怎么读出来呢?我们举个例子,我们想得到用户是2,12,22这三个人发的TweetList,这里是时间胶囊里的数据,我们会看到一共有5条是它发的,我们把这5条全部找到,怎么找到呢?答案就是遍历,遍历一遍找到5个全部返回,那时间复杂度就是O(n),特别繁琐,尤其你在硬盘上遍历就麻烦了。

问题6:如何加速?
加速最基本的肯定是建索引,那我们想想有可能建索引吗?建什么索引呢?
建索引之前有个想法:因为我们每次查都是按照用户来查,那能不能按照时间胶囊把用户的数据放到一起呢?也就是说先把22的数据全部放在一起,把用户2的放在一起。
所以可以在外面建个索引,每个指针指的就是起点,所以每次想找22的,就找到22 的位置,遍历一遍,找到不是22为止,想查2的,遍历一下到2为止,这也是非常好的。
但实际会发现里面有个问题,当我把数据按照这个方式整合以后,我还需要存这个22吗?其实不需要,为什么?因为指针每次指过来,一定知道对应的数据是22,但唯一不知道的是22后面有几个,所以我把22有三个数据也编到索引里面,就可以完全的知道索引信息了,现在我们的复杂度就是q*log(n)+k,q*log(n)就是索引中检索的复杂度,而+k就是硬盘遍历的复杂度。实际上前面的复杂度很低,因为这个index往往在内存里,所以这个k往往是复杂度的上限。

问题7:如何节省空间?
我们刚刚讲了,这个过程实际上还可以简化,就是把这个过程变没,再省空间。什么意思呢?将以前的压缩,只保留第一列TweetID,没有保留UserID,那就需要把编码编进内存里,所以我们索引会记(22,3),由用户22发的tweet一共有3个,所以当我的指针指过来以后就遍历3项就知道这3项是用户22发的,同理用户2的可能遍历2项就得到了,所以通过这个方式能够很快速的遍历,而且文件还变小了,只要读取就行了,所以性能会极大的提升,这是我们另外一种优化。

讲到这里我们已经讲完了底层存储的方式,如何实现大家可以试一试,但它的思想还是起源于GoogleFileSystem,所以大家有时间还是要仔细回顾GoogleFileSystem怎么做。
问题8:如何支持搜索
最后我们再讲一下怎么在Twitter上做搜索。讲到搜索,往往以为是很复杂的东西,但我们基于已有架构是可以把搜索做出来的。
举个列子,这里是我们刚刚讲的全结构,右边是读写,包括Cache过程,而左边是一个新用户过来以后怎么创建Timeline Builder,那怎么做一个搜索呢?我们在右边建个Indexer,每次用户数据一进来,就会建一个索引,建索引以后存起来就是Search index,然后用户一输入要搜索什么内容,直接找个Blender把结果拿到就出来了,这就是过程。

过程里面怎么实现呢?我们来看一看。首先输入一个消息进入到Indexer。Indexer可以做很多事,首先切词转换,把内容转成单词,
第一步我发送消息过来,”Hello,world,I’m Fennec”会转成(TweetID=300,keyword=(hello,world fennec)),TweetID是300,有关键词hello,world,fennec,我们把没用的语义性很弱的内容去掉。
第二步就是建字典,字典也是用ID来表达关键词,这样在里面计算或者存储的时候非常快,不然里面存的都是单词性能会非常差,而且占用很多空间,比如在字典里helllo是39,worldID是46,fennecID是99,就会把看似很长的一个串,变成<300,{39,46,99}>,300是tweetID,后面是关键词列表,之后会建一个倒排索引,这又是什么意思呢?是要记住39存的TweetID在哪。举个例子,我们右边列了好多东西,这些跟TweetID是一样的,只不过对于39这个关键词,一共有12个Tweet包含,起点在上面,所以下次用户搜索39的时候,它会在右边列表中找12个,举个例子之前存了11个,新信息过来以后,就会把39里再加上300,所以会在右边多写一个300,如果是内存中的数据就可以直接加,然后可以不断的持久化,有很多细节大家可以参考BigTable的做法。
但总之我会在内存中建立一个倒排索引,每个索引里会存两个关键词,一个是关键词的ID,另一个是ID在内存数据块里对应的tweet有几个。所以指过去后顺序遍历12个,就可以读出所有包含这个关键词39hello的index,这样就可以搜索出结果了。具体搜索的时候,包括46,99也都需要存一下都是把300存到里面。

那搜索怎么办呢?比如想搜索cook pie,Blender会变成cook和pie两个词的搜索,cook对应数字是76,pie对应数字是527,他们通过在index里找到并读出对应的列表,传回Blender,Blender再把结果整合到一起就可以返回给用户,所以这是一个完整的搜索过程。大家可以仔细想一想完整的搜索过程怎么做,如果把这个想通了,说明已经完全理解Twitter设计了。
最后总结一下:
- 内存加速
- 空间优化
- 接口包容
- 硬盘补足

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。