Twitter实时大数据Streaming进化,从Storm到Heron


今天我们来解读文章《Twitter Heron: Streaming at Scale》,聊一聊从Storm到Heron,Twitter在大规模实时流处理的逐渐进化。这篇文章的作者是符茂松,他是Twitter的资深工程师、Heron的作者之一。

Twitter的需求
首先我们来看Twitter的需求。
- 实时地发现趋势。比如最近疫苗出问题了,它应该能够自动发现”疫苗“,然后自动推送给大家。
- 实时讨论。比如今天上午正在开苹果的发布会,我们就能一起实时地讨论这一事件。
- 更重要的是实时推荐,因为广告的点击率决定了现在整个公司的收入。
- 实时搜索,比如地震发生后,很多人都会在Twitter上搜索“Earthquake”来得到最新的消息。
所有以上这些,都有一个共同的词:实时。
因此,在Twitter里,Storm就是用来提供数据到来时的毫秒级别的处理能力,它有很多重要的属性:
- 保证消息被处理:如果有时消息没有被处理,会丢失很多重要的东西。
- 从0到TB的扩展能力:Twitter的数据肯定是不断扩展的,最终一定会达到TB的级别,如何让架构能够逐渐扩展是一个重要的能力。
- 机器挂掉时的应对:由于机器特别多,因此错误是常态,那么机器挂掉应该怎么办?它会有一些相对应的应对方式。
- 方便写代码:应该能够让大家在用的时候,能非常方便地写代码,不然没人会用你的系统。

Storm如何统计单词的出现次数?
首先我们有一个实时的Tweet,也就是用户发了一个消息。第一步是将Tweet裁剪成Words,相当于一个具体的计算因子。另外一个计算因子是获得字母出现的次数,每出现一次计为1,最后全部加到一起。因此你发的所有Tweets,在最后会输出所有Tweets的每个字母出现的次数。
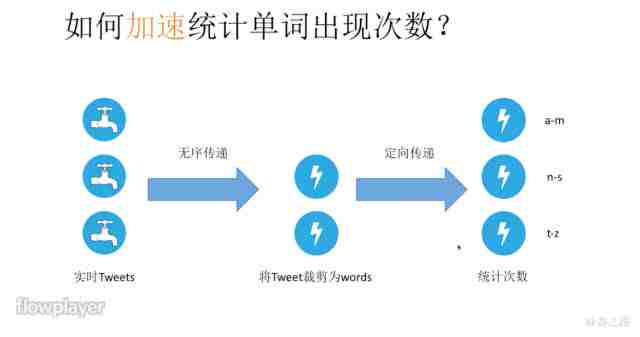
如何加速统计单词出现的次数?
但是在这个架构里,如何才能继续加速?我们很容易想到去Scale,把每个模块扩展出多个,那它们之间就会进行数据的传输。我们看第一个传输,实际上第一列每个Tweet交给第二列的任何一个计算因子,都能用同样的方式裁剪,所以它是无序传输,也就是说交给谁都行,可以根据流量、压力来进行选择。
但是下一个传输就不行了,为什么?比如要统计首字母为b的单词次数,如果你一会儿发给甲,一会儿发给乙,你得到的单词出现次数就是不一样的,因此我们往往会把这个计算因子拆解开来。比如甲负责统计首字母为a到m的单词次数,乙负责n到s,丙负责t到z。这就是一个定向传输,根据首字母的不同决定传递给谁。
Storm的架构是什么?

讲完Storm的计算方式,接下来我们来看看Storm的架构是什么。刚才我们要计算一个单词出现的次数,计算方案就是:首先有一个Master,即上图的Nimbus,Master负责调度Worker,监控数据,以及一些分布式远程调用,相当于它把整个Strom的集群对外体现成了一个远程调用的服务。
得到计算方案以后,它会将任务表交给ZooKeeper集群进行维护,之后底下的Supervisor会负责和这个ZooKeeper的集群进行连接,然后调度里面的Worker进行执行。
这看起来是一个非常简单的架构,它有什么问题呢?
首先,Master是单点失败的,它一失败整个架构就全挂了。其次,由于之前架构里的资源没有一些分配机制,如果挂了就需要人工重启,并且恢复得特别慢,这样会造成很多损失。另外,ZooKeeper的Cache太多了,它同步任务表就会变成性能瓶颈。
Worker是什么?

我们再来看Worker是什么。上图中,最下面的Supervisor负责管理这个Worker的所有东西,里面会有n个Worker,每个Worker是一个JAVA虚拟机在运行着。而Worker里面就是执行者,每一个执行者是一个线程,所以Worker里有很多线程,每个线程执行了很多任务,这些任务之间在互相传递和影响,变得越来越复杂,
所以Worker其实很复杂,它不仅不好理解,还不好调试、不好优化。更重要的是,这些Task在执行过程中,需求都是不一样的,有的需要IO,有的需要CPU,因此混在一起更没有办法去验证了,这就是力度太弱的一个原因,即没有资源隔离的能力。
Worker的数据流是什么?
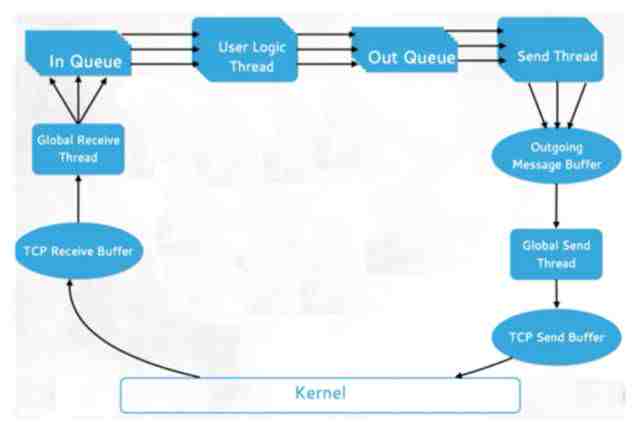
首先,Kernel层把数据发给TCP Receive Buffer,因为它是用TCP的方式接受数据流的。然后Global Receive Thread将收到的Buffer里的东西放到Queue里,Queue会交给User Logic Thread去具体执行。执行完以后,它又去到另外一个Queue,再通过Send Thread发回到Out Message,然后通过Global Send Thread发回到TCP Send Buffer,最后再返回Kernel。因此这是一个遥远的长期过程,中间涉及很多Thread。
因此Worker不仅数据流的执行过程很复杂,更重要的是,它在写的过程中因为一些历史原因,会使用各种语言,导致Queue是个瓶颈。并且很容易在执行过程中,由于JAVA虚拟机的各种原因造成内存阻塞,结果CPU没用完,内存占多了,造成了CPU的浪费。
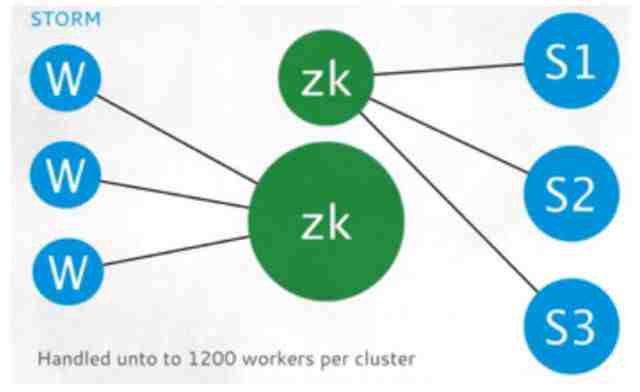
具体来看,在Twitter里,很多Worker都要跟着ZooKeeper协调很多数据,导致它有1200个Worker,这就是一个集群的上限,在Twitter里不能再多了。
为什么Worker会达到1200这个瓶颈呢?因为它里面的Kafka是用Batch的方式传数据,一般是每两秒一次。而且Worker会有三秒一次的心跳。1200个Worker每三秒发生一次心跳,那么每秒就会有四百多个Worker发生心跳,这将对ZooKeeper产生很大的压力。
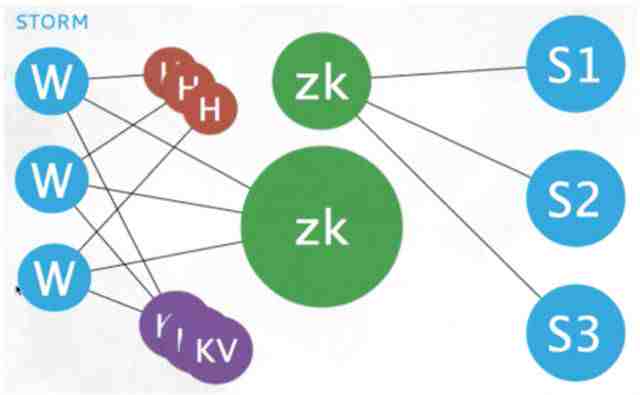
那怎样才能破这个心跳风暴呢?实际上Twitter里有很多解决方案,最简单的方法是干脆把心跳独立出来(上图中的红色就是Heartbeat),不交给ZooKeeper做,这就是一个很好的解决方案。很多系统一般一开始会用ZooKeeper,但之后就不用了。
资源如何分配?

在这个过程中,我们有很多任务产生,这些资源应该如何分配呢?上图的方格代表各种机器的资源,其中有三个任务,用不同的颜色来表示,红色是Joe的,绿色的Jane的,黄色是Dave的,也会有蓝色的共享资源,大家都可以用。
但问题是,在Storm里,由于资源分配机制写得不好,独占的资源是无法共享的,红色、绿色、黄色都被独占了。但是有的东西可能内存占得多,CPU占得少,或者CPU占得多,内存占得少,而无法调度,这就造成了浪费。
上游数据过快怎么办?
我们进一步看,还有一个问题,比如上游数据过快怎么办?Supervisor得到任务以后都会交给Worker去执行,如果Worker收到的数据太多怎么办?它需要防止自己被雪崩掉(雪崩的概念见经典系统设计题:如何设计支持上亿用户的即时通讯软件?)。如果下游特别慢,因为上游又不能等他,所以假如不解决,上游就会崩掉,因此必须要用丢失的方式来解决。可是即使是丢失,上游还是会重发的,因为他需要任务来执行,因此你会看到很高的失败率,这也是一个问题。简单理解,就是无法细粒度地进行各种控制。
如果内存成为瓶颈,会产生什么问题?
产生的问题就是20%~30%的低CPU利用率,以及没有CPU和内存的细粒度隔离和调度。在Twitter里的各种实验或实际情形中发现,往往内存已经用完了,而CPU才用20%到30%,这就造成了极大的浪费。
有这么多问题,怎么解决呢?在此之前我们讲最后一个问题:
数据很多会发生什么?
这是一个很有意思的问题。在Storm里是一个一个单独处理数据的,当数据很多的时候不能批量处理。大家知道批量处理是人类一个非常厉害的能力,因为批量处理不仅传输得少,而且逻辑会变得简单。但如果不能批量处理,而是一个个单独处理,数量一大就完蛋了。
由此,Twitter决定设计一个新的系统:Heron。

设计新系统也要考虑历史兼容,否则迁移会出现问题。所以第一个目标就是降低升级代价,让Heron兼容Storm的API。他们用了一个很巧的方法,通过重编译的方式,减少Strom的任务,编译成Heron可以理解的任务。因此只需要语义上的移植性,而不需要完全的移植性。
其次,他想提供更方便的调试和优化,因为这样可以发现错误。我们知道调试经常会占用我们一半的时间。优化能够让我们更好地找到一个好的配置参数。一般来说,如果配置较好,可以减少3到5倍的资源。另外他们也希望能隔离一些Task,并且希望使用主流的语言(C++/Java/Python)。
Heron的架构到底是什么?
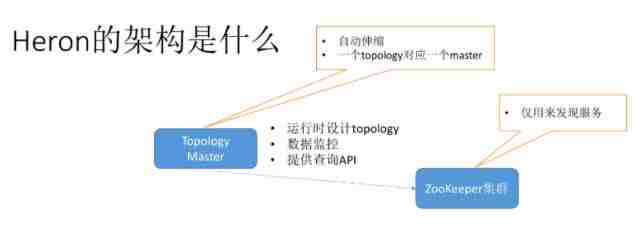
首先有一个Topology Master,即任务的拓扑管理器,但因为它是运行时设计Topology,所以它能在运行时,根据运行时的资源自动Scale。它还能提供数据监控,并提供查询API了解实时情况。
其次,ZooKeeper集群还存在,但它的任务变简单了。Topology连接ZooKeeper之后,自己就能够实现自动伸缩。此外,在这个架构里,一个Topology对应一个Master,会同时有很多Master来解决拓扑的问题,不会出现以前那种单点失败的问题,而且出现问题之后很容易恢复。
而对于ZooKeeper来说,它减轻了以前的心跳等各种服务,仅用来发现服务,所以ZooKeeper的压力很小,也不容易出现问题。并且现在它采用的是自定义的方式,以后甚至能用一些DNS的方式实现。
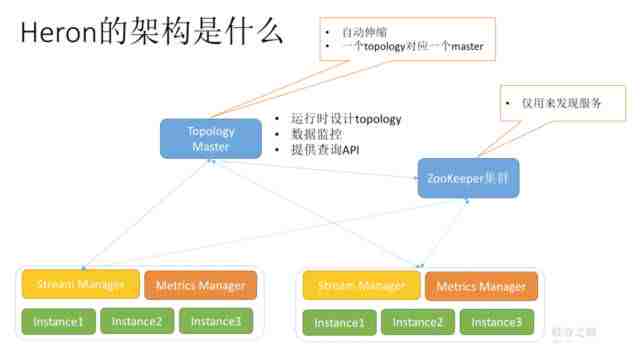
我们继续来看,底层有一个Stream Manager,负责整个流的处理,它和Topology Master之间有强连接,而和ZooKeeper连接比较弱,只用来发现服务。它的内部写了很多实例(Instance),实例实际上是一个逻辑上的概念,它是负责执行任务的,而且还有一个Metrics Manager,统计各种各样的资源。
这些放在一起就是一个Container,Container形成了一个最小的资源隔离单位,便于资源调度。我们也可以有很多Container,通过对资源的隔离和调度,来进行优化的设置。而且这些Container对外都有Stream Manager统一进行流处理,统一地管理流。
Stream Manager是如何传输的?

上图是一个例子,有4个这样的Container,他们之间互相传输。Stream Manager的好处是,他本身相当于一个数据沟通的基站,你可以把每一个Stream Manager里的实例都当成一个他的小手机。他们为了和外面打电话,必须通过Stream Manager这个基站进行沟通,这样简便了管理。同时Stream Manager自己也可以提供流量控制,如果有人压力太大,他就可以告诉大家不要传输太多,他的压力太大,这样便于优化设置。
大家可能会想,为什么不把这放到每个单独的Instance里面呢?因为这样会将Instance变得很复杂,互相传输也更麻烦,不如都用Stream Manager来管理。其次Stream Manager会用C++进行更细粒度的优化设置,比如内存的管理。
Instance的架构是什么?

Instance的架构其实非常简单,只有两个线程。左边是网关线程,负责和外面交互数据,以及汇报数据的监测情况。右边是执行线程,负责数据进来以后的执行,把结果和一些统计值输出。
Heron和Storm的比较

最后我们对Heron和Storm的优缺点做一个比较,拿什么指标来比呢?
第一个指标当然是CPU的利用率,CPU利用率有2到3倍的提升,而之前CPU总是占不满。吞吐量和延迟也是两个非常好的指标,分别有10到14倍、5到15倍的优化。这是用统计字符的方法做的,不同的HashMap会有不同的效果,但是至少说明Heron已经有了很大的提升。
总结
- Storm提供了毫秒级别的实时数据处理能力
- Heron通过将ZooKeeper减负,将资源进行隔离,使能够更好地配置并优化。同时还有流量控制,优化了CPU利用率、吞吐率、延迟等。
- 评测的指标要选择CPU、吞吐和延迟,当然也有别的指标,大家可以在实践中自己去选择。
参考文献http://www.infoq.com/cn/presentations/twitter-heron-streaming-at-scale
想用工业级项目完善简历?
↓↓↓

最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。