从Hadoop到Spark,看大数据框架发展之路


谈到大数据框架,不得不提Hadoop和 Spark,今天我们进行历史溯源,帮助大家了解Hadoop和Spark的过去,感应未来。
在Hadoop出现前人们采用什么计算模型呢?是典型的高性能 HPC workflow,它有专门负责计算的compute cluster,cluster memory很小,所以计算产生的任何数据会存储在storage中,最后在Tape里进行备份,这种workflow主要适用高速大规模复杂计算,像核物理模拟中会用到。
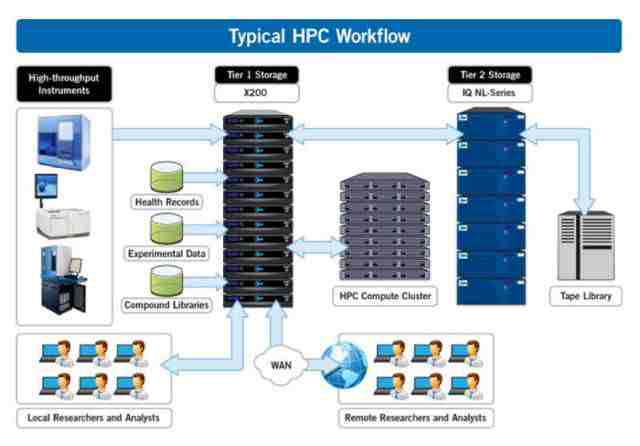
HPC workflow在实际应用中存在一些问题,这些问题促进了Hadoop的出现。
首先如果想对大量进行简单计算,比如对Search logs 进行“what are the popular keywords”计算,这时是否可以用HPC workflow?当然可以,但却并不适合,因为需要做的计算非常简单,并不需要在 high performance compute cluster中进行。
其次由于数据量大,HPC workflow是I/O bound,计算时间只有1个微秒,但剩下的100个微秒可能都需要等数据,这时候compute cluster就会非常空闲,因此HPC同样不不适用于 specific use。
另外HPC主要在政府部门、科研等领域使用,成本高昂,不适合广泛推广。
如果不能把数据移到计算的地方,那为什么不转换思维,把计算移到数据里呢?
所以Google在2003至2006年发表了著名的三大论文——GFS、BigTable、MapReduce,解决怎么样让framework 挪到有数据的地方去做,解决了数据怎么存储,计算及访问的问题。
在Google 发出三大论文后,Yahoo用相同的框架开发出JAVA语言的project,这就是Hadoop。Hadoop Ecosystem在十年多时间发展的如火如荼,其核心就是HDFS,Mapreduce和Hbase。
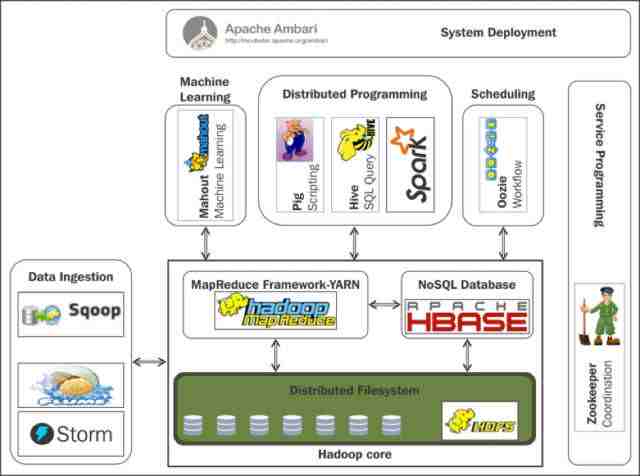
HDFS很好地实现了数据存储的以下特性要求:
- Cheap
- High availability
- High throughput
- High scalability
- Failure detection and recovery

大家从图中可以看到HDFS数据读取和写入的过程,这个Architecture非常稳定,当数据量越来越大时Namenode从一个发展为多个,使内存增大,产生了Namenode Federation。

数据存储已经实现,那如何进行计算呢?
如果有1PB size log,当需要计数时, 一个machine肯定无法计算海量数据,这时候可能需要写Multi-threads code,但也会存在进程坏了,性能不稳定等问题,如果Data Scientist还要写multi-threats程序是非常浪费时间的,这时候Mapreduce 就应运而生,目的是让framework代替人来处理复杂问题,使人集中精力到重要的数据分析过程中,只需要通过code Map和Reduce就可以实现数据运算。

让我们来思考下:在一次Mapreduce中至少需写硬盘几次?
至少3次!
开始从HDFS中读取数据,在Mapreduce中计算,再写回HDFS作为 Intermediate data,继续把数据读出来做reduce,最后再写回HDFS,很多时候做meachine learning需要不断迭代,一次程序无法算出最终结果,需要不断循环。
循环过程一直往硬盘里写,效率非常低,如果把中间数据写入内存,可以极大提高性能,于是Spark出现了

当把数据从HDFS中读出来到内存中,通过spark分析,Intermediate data再存到内存,继续用spark进行分析,不断进行循环,这样Spark会很大地提高计算速度。
Spark在2009年由AMPLab开发,吸取了很多Hadoop发展的经验教训,比如Hadoop对其他语言支持不够,Spark提供了Java,Scala,Python,R这些广泛受到Data Scientist欢迎的语言

那Spark与Hadoop的区别有什么?
- Spark比Hadoop使用更简单
- Spark对数据科学家更友好(Interactive shell)
- Spark有更多的API/language支持(Java, python, scala)



最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。