极品干货:生存模型在信用风险中的应用


今天来给大家讲一讲如何把生存模型(Survival Model)应用到信用风险领域。
众所周知,生存模型顾名思义是用来研究个体的存活率与时间的关系。例如研究病人感染了某种病毒后多长时间会死亡;工作的机器多长时间会发有崩溃等。这个方法被普遍应用到医学、生物学等学科上,近年来也越来越多的被用在金融行业去预测房贷或者车贷什么时候会出现违约,当真的发生这个违约的时候又有多大部分的贷款会成为坏账。
面对这样一个课题,很多人可能会说我用传统的机器学习的方法也可以预测贷款违约,为什么我要选择生存模型呢?主要的原因有二。第一,生存模型可以很好的处理删失数据(Censored Data)。删失在维基百科中给出的定义是 “Censoring occurs when the values of a measurement or observation is only partially known”。但是,这个partially known也同样也适用于截尾数据,但是造成patially known的原因却是大不相同。
图一给出了左右删失和左右截尾数据的定义,通过这个定义我们大概能猜测出造成删失数据的patially known的两种情境。一个是事件在样本观测期前/后发生,再者是样本因为各种原因失去联系导致对样本的观察中断。接下来我们通过一些例子来进一步阐述。
假设你在做一个对孕妇怀孕期的研究,当你即将完成研究和分析时,有些孕妇还处于怀孕状态(表一的004号孕妇),所以她具体的孕期天数是未知的,这就是右删失数据。但是如果有孕妇在你的研究开始前已经生产,那么此种情况就是属于左删失数据。截尾数据的partially known一般是实验设计或者样本选择造成的。比如,如果你选择的寿命样本都是来自退休中心,而退休中心一般要60岁及以上才能加入。所以你所有的样本都是>=60岁,<60岁的数据被排除在外了,也就是左截尾。但是如果你的另外一个样本数据只有80岁以下死亡的老人的寿命,那就是所谓的右截尾了。
图一:删失和截尾数据的定义

图二:四种不同删失数据的可视化

表一:孕妇怀孕期长度的研究

第二,生存模型可以很好的展示出事件和时间的关系。一般的二元分类模型可以预测一个事件发生与否,却无法回答什么时候这个事件会发生。不管在医学还是金融行业,能否回答这个问题对于医生、病人亦或者是公司都是非常关键的。因为对于这个问题答案的提前预测能够帮助医院减少死亡率、帮助公司更好的控制意料之外的风险。
接下来我们进入真正的正题。首先,我们要来普及一下一般银行借贷是如何计算预期损失(Expected Loss)的。维基百科 详尽的介绍了计算预期损失的三个要素: 违约概率(PD)、违约风险暴露(EAD)、违约损失率(LGD)。可以参照图三了解这三个要素的定义。
公式1:
预期损失 = 违约概率 * 违约损失率 * 违约风险暴露
公式2:
预期损失率= 预期损失/总额
图三:预期损失的三个要素

公式1的三个要素分别对应了三个模型,即违约概率模型,违约风险暴露 模型和违约损失率模型。违约概率模型我们可以用任何一种二元分类模型,比如逻辑回归、决策树、随机森林等等。违约风险暴露模型我们可以用任何一种线性模型,比如简单线性模型, 回归树等等。关于违约损失率,因为我所从事的电信行业的手机贷款不涉及到任何抵押 ,所以损失率在此种情况下为100%。想要了解更多损失率模型的可以参考这篇Modeling Loss Given Default 文章。
众所周知,国内的三大电信公司都是采取预付(prepaid)的形式,而美国的电信公司除了少数的预付业务,大部分的业务都是后付费(postpaid)。在把手机当作一个小型贷款贷给顾客前,电信公司都对该顾客的信用风险进行评估分级,信用分数好的顾客有更大额度的贷款而信用分数差的顾客只能享受相对小额的贷款(关于美国信用体系的概论会在另外一篇文章中详细探讨)。一般来说,一个手机贷款的周期为24个月,顾客可以选择提前付清或者付满24个月。对提前付清的人来说,周期是短于24个月的,所以不同顾客的数据有长有短。这也印证我的之前提到的为什么要选择生存的第一个原因。
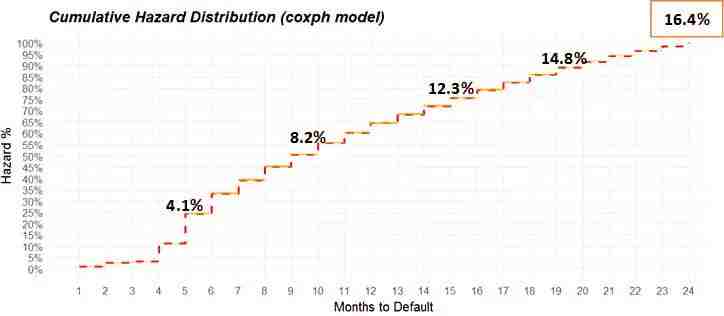
贷款预期损失率(Loan Loss Rate),是由贷款预期损失除以总的贷款金额所得(参考公式2)。它是作为公司储备金的重要指标,估计过高的话 会影响到公司的资金流动,而估计过低的话会带来意料之外的坏账,进而危害公司的健康运作。因此,三个模型能否精确预测至关重要。接下来也是通过一个例子来讲述生存模型是如何被应用到贷款预期损失率的计算中。因为商业需求的局限,违约概率的预测我采用了逻辑回归模型。我们假设该逻辑回归模型预测出一个贷款到第24个月的违约概率是16.4%。那么我们如何能得出此贷款到第四个月、到第十个月、到第十五个月等等的贷款损失预期呢?我们不可能建24个单独的逻辑回归模型来得到贷款从第一个月到第二十四个月的违约可能性,这非常的不现实。所以这个时候就需要借助生存模型的累积灾害分布图(Cumulative Hazard Distribution)来告诉我们这个贷款是如何一步一步从第一个月到第二十四个月违约过来的。从图四我们可以看到每个月违约概率的具体的比重,第一个月接近0,第五个月25%, 第十个月50%,以此类推,第24个月是100%。当用这个比重乘以16.4%后我们可以得到各个月的违约可能性,分别是0%, 16.4%*25%, 16.4%*50%,以此类推。
图四:累积灾害分布图 (0% to 100%)
还记得违约风险暴露回答的问题是如果一个$1000 的贷款要被违约,当违约发生的时候这$1000还剩下多少可以被违约。从图五我们可以看出,前四个月的违约风险暴露比率是100%,这是因为电信的Collection Policy 的原因导致前四个月时间不足以产生违约。从第五个月开始违约风险暴露比率一路走低,这是因为顾客开始每个月的账单支付,所以loan的余额会变得越来越少。至于为什么第24个月的EAD Ratio为什么不是0%,这也是因为电信公司的托收政策允许顾客在被记成是坏账之前还有四个月时间把余额还清。对违约风险暴露模型的选择很大程度上取决于数据本身,如果历史数据显著的是简单线性,那么本着能用简单模型就不用复杂模型的原则,选择线性模型进行拟合。从图三你可以看到历史数据点很好的拟合成两段线性模型,分别是y = 0 (x<=4)和y = 1.177-0.04x (x>4)。
图五:违约风险暴露= 违约风险保留 * 总额

当我们把违约概率、违约风向暴露和违约率三者结合在一起的时候我们可以得到最后的贷款预期损失和贷款预期损失率(见图六)。假如我们贷的是价值$1000的iPhone手机贷款,那么该贷款到第24个月的贷款预期损失率是12.5%,贷款预期损失是$125。
图六:贷款预期损失率曲线

以上就是一个完整的如何将生存模型应用到到信用风险的一个例子。相信生存模型可以在更广泛的领域有更多更深入的应用。谢谢大家的阅读,如有任何的建议,意见和反馈,欢迎留言,我会尽快回复。
作者:陈泓夙(Cali)
毕业于美国康涅狄格大学(University of Connecticut)商业数据分析专业(Business Analytics and Project Management)的研究生项目。大学期间在德勤的Forensic Analytics部门做数据分析相关的实习,毕业后加入美国最大的电信公司金融部门的Credit Risk Modeling组做信用模型、顾客流失分析和手机贷款损失预测等。在Credit组工作三年后,转到内部审计的Forensic Advisory and Analysis组继续做数据分析,发光发热。
斩获FLAG多个offer的面霸及资深数据科学面试官Joyce老师,吐血总结100+数据类面试,分类整理出AB Test核心面试考核重难点,深入浅出解析最热门的A/B Test面试,Take Home Challenge实战训练,逐个击破实验设计每个环节,让你一个周末攻克数据科学面试 - AB Test专题。
↓↓↓


最新评论
推荐文章
作者最新文章
你可能感兴趣的文章
Copyright Disclaimer: The copyright of contents (including texts, images, videos and audios) posted above belong to the User who shared or the third-party website which the User shared from. If you found your copyright have been infringed, please send a DMCA takedown notice to [email protected]. For more detail of the source, please click on the button "Read Original Post" below. For other communications, please send to [email protected].
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。
版权声明:以上内容为用户推荐收藏至CareerEngine平台,其内容(含文字、图片、视频、音频等)及知识版权均属用户或用户转发自的第三方网站,如涉嫌侵权,请通知[email protected]进行信息删除。如需查看信息来源,请点击“查看原文”。如需洽谈其它事宜,请联系[email protected]。